Multiprogramming
Disclaimer of Passing the Buck
Starting from PA4, the lecture notes will no longer provide watertight code guidance, and some key details of the code need to be considered and tried out by yourself (we deliberately omitted them). We will elucidate the principles of technology clearly in the lecture notes, and you need to first understand these principles, then read and write the corresponding code based on your understanding.
In a nutshell, rather than complaining about the unclear lecture notes, it's better to think more on your own. Now that we've reached PA4, to conform the grades to a normal distribution, scoring high will inevitably require extra effort. If you have been looking for shortcuts rather than trying to deeply understand how the system works, it might be too late now.
With the support of Nanos-lite, we have successfully run a batch processing system in NEMU and got the game "The Legend of Sword and Fairy" up and running! This demonstrates that our self-built NEMU, though seemingly simple, is equally capable of supporting the execution of real programs, no less inferior to a real machine! However, the batch processing system currently can only run one program at a time, and it only starts executing the next program after one has finished.
This indeed highlights a flaw in the batch processing system: if the current program is waiting for input/output, the whole system will come to a halt. In real computers, compared to the CPU's performance, input/output operations are significantly slower. For example, a disk read/write operation takes about 5 milliseconds, but for a 2GHz CPU, this means waiting for 10,000,000 cycles for the disk operation to complete. However, instead of letting the system fall into a meaningless wait, it would be better to use this time to do some meaningful work. A simple idea is to load multiple programs at the beginning, then run the first one; when the first program needs to wait for input/output, switch to the second program to run; when the second program also needs to wait, continue to switch to the next program to run, and so on.
This is the basic idea behind a multiprogramming system. The concept of multiprogramming sounds simple, but it's also a form of multitasking system because it already includes the basic elements of a multitasking system. In other words, to implement a multiprogramming operating system, we only need to achieve the following two points:
- Multiple processes can coexist in memory at the same time
- Under certain conditions, it is possible to switch the execution flow among these processes
Terminology Change
Since it's a multitasking system, there is more than one program running in the system. Now, we can directly use the concept of "process".
Implementing the first point is not difficult; we simply need to have the loader load different processes into different memory locations. The process of loading processes is essentially a series of memory copy operations, so there is nothing particularly challenging about it.
Actually, I'm fooling you!
For our currently implemented computer system, "loading different processes into different memory locations" is a troublesome task. Can you figure out why? If not, it's okay, we will discuss this issue in detail in the next stage.
For simplicity, we can directly define some test functions in the operating system as programs, because essentially, a program is just a sequence of meaningful instructions, and for now, we don't need to worry about where these sequences come from. However, one thing to note is the stack; we need to allocate separate stack spaces for each process.
Why do we need to use different stack spaces?
What would happen if different processes shared the same stack space?
The second point requires more thoughtful consideration: on the surface, "how to switch the execution flow among processes" is not an intuitive matter.
Context Switch
In PA3, we already discussed the switching of execution flow between the operating system and user processes, and introduced the concept of "context": the essence of context is the state of the process. In other words, what we now need to consider is how to switch contexts among multiple user processes.
To help you understand this problem, we have prepared an operating system yield-os of about 30 lines in am-kernels for everyone. It creates two execution flows and alternately outputs A with the support of CTE and B. You can run yield-os on native to see how it behaves.
Update am-kernels
We added the yield-os code to am-kernels on October 3, 2023, at 15:35:00. If you acquired the am-kernels code before this time, please use the following command to get the updated code:
cd am-kernels
git pull origin master
Fundamental
In fact, with CTE (Context and Trap Extension), we have a clever way to implement context switching. Specifically, suppose process A triggers a system call during execution and enters the kernel through a trap instruction. According to the code in __am_asm_trap(), A's context structure (Context) will be saved on A's stack. In PA3, after the system call is handled, __am_asm_trap() will restore A's context based on the context structure saved on the stack. Here comes the magic part: what if we don't rush to restore A's context, but instead, switch the stack pointer to another process B's stack? Since B's stack contains the previously saved context structure of B, the subsequent operations will restore B's context based on this structure. After returning from __am_asm_trap(), we are now running process B!
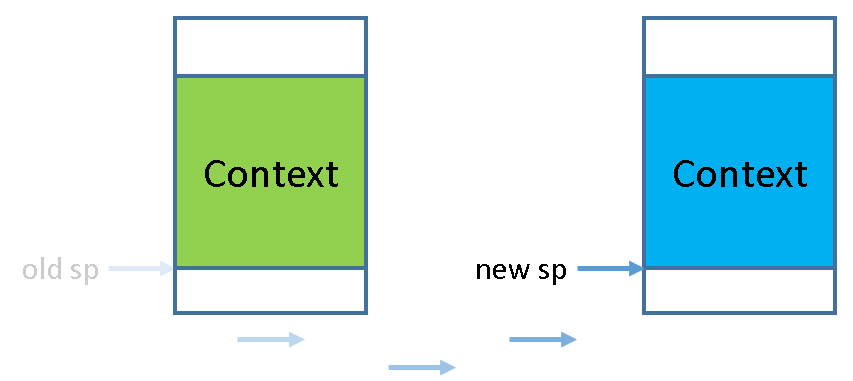
So where did process A go? Don't worry, it was just "suspended" temporarily. Before being suspended, it saved the context structure on its stack. If the top pointer of the stack is switched to A's stack at some point in the future, the code will restore A's context based on the context structure on the stack. A will be awakened and executed. Therefore, context switching is a stack switching between different processes!
Process Control Block
However, how do we locate the context structure of another process? Notice that the context structure is saved on the stack, and the stack space is vast. Affected by the stack frames formed by function calls, the location where the context structure is saved is not fixed each time. Naturally, we need a cp (context pointer) to record the location of the context structure. When we want to find the context structure of another process, we just need to look for the cp pointer related to that process.
In fact, many pieces of information are process-related, including the context pointer cp mentioned earlier, as well as the stack space discussed above. To facilitate the management of these process-related pieces of information, the operating system uses a data structure called the Process Control Block (PCB), maintaining a PCB for each process. The PCB structure that we need to use has already been defined in the code of yield-os:
typedef union {
uint8_t stack[STACK_SIZE];
struct {
Context *cp;
};
} PCB;
The code uses a union to place other information at the bottom of the process stack. Each process is allocated a 32KB stack, which is sufficient to prevent stack overflow leading to undefined behavior (UB). During context switching, all that needs to be done is to return the cp pointer from the PCB to the CTE's __am_irq_handle() function, and the remaining part of the code will restore the context based on the context structure. With just a bit of mathematical induction, we can be confident that this process is always correct for the processes that are running.
So, how do we switch to a process that has just been loaded, to get it running?
Kernel thread
Create kernel thread context
The answer is simple, we only need to manually create a context structure on the process stack so that the context can be correctly restored based on this structure when switching in the future.
As mentioned earlier, we start by using some test functions directly defined in the operating system as programs. yield-os provides a test function f(), and our next task is to create a context for it, and then switch to it for execution. This type of execution flow has a specific name, called a "kernel thread."
Why not call it "kernel process"?
This question is essentially equivalent to "What is the difference between a process and a thread", which is a good question. Moreover, this also falls under the typical content for graduate entrance exams, so you can find a variety of answers by searching the web (STFW), such as "Threads are more lightweight", "Threads do not have independent resources" and so on.
If you want to further explain "what does lightweight mean" and "what are independent resources," it might be difficult in the context of PA. However, in PA, it is not necessary to delve deeply into this issue; for now, you can simply consider them both as streams of execution. More importantly, you will implement both, and isn't experiencing their differences firsthand in code a better choice? Additionally, taking this question into next semester's operating systems course might be a good idea.
Creating the context for a kernel thread is implemented through the kcontext() function provided by CTE, which is defined in abstract-machine/am/src/$ISA/nemu/cte.c, where "k" stands for kernel. The prototype of kcontext() is:
Context* kcontext(Area kstack, void (*entry)(void *), void *arg);
In this, kstack defines the range of the stack, entry is the entry point for the kernel thread, and arg is the parameter for the kernel thread. Additionally, kcontext() requires that the kernel thread must not return from entry, as this would result in undefined behavior. You need to create a context structure at the bottom of kstack with entry as the entry point (you can ignore the arg parameter for now), and then return the pointer to this structure.
yield-os calls kcontext() to create a context and records the returned pointer in the PCB's cp field:
| |
+---------------+ <---- kstack.end
| |
| context |
| |
+---------------+ <--+
| | |
| | |
| | |
| | |
+---------------+ |
| cp | ---+
+---------------+ <---- kstack.start
| |
Thread/Process scheduling
The creation and switching of contexts is the responsibility of the CTE, while deciding which context to switch to is determined by the operating system, a task known as process scheduling. Process scheduling is accomplished by the schedule() function, which is used to return the context of the process to be scheduled. Therefore, we need a way to track which process is currently running, so that we can return the context of another process in schedule(), achieving multitasking. This is done using the current pointer, which points to the PCB of the currently running process. This way, we can decide which process to schedule next using current in schedule(). However, before scheduling, we also need to save the current process's context pointer in its PCB:
// save the context pointer
current->cp = prev;
// switch between pcb[0] and pcb[1]
current = (current == &pcb[0] ? &pcb[1] : &pcb[0]);
// then return the new context
return current->cp;
Currently, we have schedule() always switch to another process. Note that the context of the chosen process is created by kcontext(), and it is only decided in schedule() to switch to it, then the context is actually restored in CTE’s __am_asm_trap().
Decoupling Mechanisms and Policies
This actually reflects an important principle in system design: the decoupling of mechanisms and policies. Mechanisms address the question of "can it be done," while policies address the question of "how to do it well." Clearly, policies rely on mechanisms, and mechanisms need policies to be most effective.
The benefits of decoupling are obvious: high code reusability and ease of understanding. In Project-N, this decoupling has been taken to the extreme: mechanisms and policies are separated into two sub-projects. For example, the "context switching" mechanism is implemented in the AM's CTE, which enables the system to "switch execution streams"; which specific execution stream to switch to, however, is implemented in the operating system.
Another advantage of AM is that it abstracts the behavior of the underlying hardware into system-level mechanisms, Applications on AM (including OS) only need to call these system-level mechanisms and implement corresponding policies. Currently, the strategy in schedule() is quite simple, but next semester's operating system lab, and even more complex real-world process scheduling strategies, can all be implemented on the same mechanism provided by AM.
Implement Context Switching
Based on the content in the lecture notes, implement the following functions:
- The
kcontext()function in CTE - Modify the implementation of
__am_asm_trap()in CTE so that after returning from__am_irq_handle(), the stack pointer is first switched to the new process's context structure, and then the context is restored, thus completing the essential operation of context switching.
Once implemented correctly, you will see yield-os continuously outputting ?, which is because we have not yet implemented the parameter functionality for kcontext(), but these outputs of ? at least demonstrate that CTE can currently correctly switch from the yield-os main() function to one of its kernel threads.
About kcontext()
We want the code to start executing f() after returning from __am_asm_trap(). In other words, we need to construct a context in kcontext() that indicates a state from which f() can be correctly started. So what you need to consider is, in order to start executing f() correctly, what conditions should this state meet?
As for "switching the stack pointer to the new process's context structure" The natural question is, where is the new process's context structure? How do we find it? And how should we switch the stack pointer to it? If you find the code going astray, don't forget, that the program is a state machine.
Working with DiffTest
To ensure DiffTest runs correctly, you need to make some additional settings based on the ISA you've chosen:
- For x86: Set
csin the context structure to8. - For riscv32: Set
mstatusin the context structure to0x1800. - For riscv64: Set
mstatusin the context structure to0xa00001800.
Kernel thread parameters
To enable yield-os's kernel threads to output characters correctly, we need to pass arguments to f() through kcontext(). So we need to continue thinking about how f() will read its arguments. Oh, isn't this about calling conventions? You're already very familiar with them. We just need to ensure that kcontext() places arg in the correct position according to the calling convention, so that when f() is executed, it can obtain the correct arguments.
Calling conventions for MIPS32 and RISC-V32
We haven't provided the calling conventions for MIPS32 and RISCV32. You'll need to read the corresponding ABI manuals. Of course, you can also experiment on your own to summarize the rules for passing arguments.
Implement Context Switching (2)
Based on the content provided in the lecture, modify the kcontext() function in CTE to support passing the argument arg.
Since f() calls yield() after printing each message, once we correctly implement passing arguments to kernel threads, we should observe the phenomenon of yield-os switching back and forth between two kernel threads.
In real operating systems, many background tasks, daemon services, and drivers in the kernel exist in the form of kernel threads. If you execute ps aux, you'll see many kernel threads with square brackets in the COMMAND column (e.g., [kthreadd]). The principles behind creating and executing them are very similar to the experimental content above (although the specific implementation will certainly differ).
Preserve the Characteristics of kcontext()
When defining the behavior of kcontext(), AM also requires that kcontext() can only place one context structure on the stack, and cannot place more content. This requirement has two benefits:
kcontext()writes only one context structure to the stack, without causing any other side effects.- The OS can predict the return value after calling
kcontext(), and can utilize this deterministic feature for checks or to simplify certain implementations.
We know that x86 passes parameters through the stack. If kcontext() needs to support passing arg, it will need to place more content on the stack, thus violating the aforementioned determinism. However, in the PA, this won't lead to fatal issues, so we don't strictly require your kcontext() implementation to adhere to this determinism. Nevertheless, you can still consider how to implement parameter passing while adhering to determinism.
One solution is to introduce a helper function to defer the passing of actual parameters from kcontext() to the runtime of the kernel thread. Specifically, we can set the entry point of the kernel thread to the helper function in kcontext(), and set the parameters to some available registers. Later, when the kernel thread starts executing, the helper function will place the previously set parameters from the registers onto the stack and then call the actual thread entry function (f()). This solution bears some resemblance to loading user programs in Linux: User programs don't directly start from the main() function; instead, they start from _start() defined in the CRT, which performs a series of initialization operations including setting parameters, before finally calling main().
If you've chosen x86 as your ISA, you can try implementing the aforementioned helper function in CTE. Considering that it involves directly manipulating registers and the stack, it's more appropriate to write this helper function in assembly code. However, since the functionality of this helper function is relatively simple, you only need to write a few instructions to implement it.
Context Switching in Operating Systems
yield-os is a tiny OS that lacks functionality beyond context switching. However, it serves as a valuable tool for focusing on the core details of context switching. Once we grasp these details, we can swiftly apply these principles to larger operating systems.
RT-Thread (Optional)
RT-Thread is a popular commercial-grade embedded real-time operating system (RTOS) with comprehensive OS functional modules. It can be adapted to various development boards and support the execution of various application programs.
RT-Thread has two abstraction layers: BSP (Board Support Package) and libcpu (CPU Support Package). BSP defines a common API for various types of development boards and implements the RT-Thread kernel based on this API. For a particular development board, only the corresponding API needs to be implemented to run the RT-Thread kernel on that board. libcpu defines a common API for various CPU architectures, and the RT-Thread kernel also calls certain APIs from it. This design philosophy is very similar to AM (Abstract Machine). Of course, BSP is not only for real development boards but also applicable to simulators like QEMU, as the RT-Thread kernel does not need to be concerned about whether the underlying platform is a real development board.
To compile and run RT-Thread after porting it to AM, follow these steps:
Clone the ported RT-Thread repository by executing the following command in a different directory, as RT-Thread's code does not need to be packaged and submitted:
cd ~/Templates git clone git@github.com:NJU-ProjectN/rt-thread-am.gitTo compile the code, you also need to install the project build tool
scons:apt-get install sconsExecute
make initin thert-thread-am/bsp/abstract-machine/directory to perform some pre-compilation preparations. This command only needs to be executed once, and does not need to be executed again before subsequent compilation and execution.Compile or run RT-Thread in the same directory using commands like
make ARCH=native. The default output of the execution is as follows:heap: [0x01000000 - 0x09000000] \ | / - RT - Thread Operating System / | \ 5.0.1 build Oct 2 2023 20:51:10 2006 - 2022 Copyright by RT-Thread team Assertion fail at rt-thread-am/bsp/abstract-machine/src/context.c:29After running, the assertion is triggered. This is because some functions in the code need to be implemented by everyone.
We removed all BSPs and libcpus from the original project, and then added a special BSP, and used AM's API to implement BSP's API. For details, see the code in the rt-thread-am/bsp/abstract-machine/ directory. The AM APIs used are as follows:
- Use TRM's heap to implement the heap in RT-Thread
- Use TRM's
putch()to implement the serial port output function in RT-Thread - Do not use IOE for now
- Use CTE's
iset()to implement the on/off interrupt function in RT-Thread - Use CTE to implement the context creation and switching function in RT-Thread. This part of the code is not implemented, we will use it as optional homework.
For context creation, you need to implement the rt_hw_stack_init() function in rt-thread-am/bsp/abstract-machine/src/context.c:
rt_uint8_t *rt_hw_stack_init(void *tentry, void *parameter, rt_uint8_t *stack_addr, void *texit);
Its function is to create a context with entry tentry and parameter parameter as the bottom of the stack with stack_addr as the bottom, and return the pointer of this context structure. In addition, if the kernel thread corresponding to the context returns from tentry, texit is called, and RT-Thread will ensure that the code will not return from texit.
Note:
- The passed
stack_addrmay not have any alignment restrictions, so it is best to align it tosizeof(uintptr_t)before using it. - CTE's
kcontext()requires that it cannot return from the entry point, so a new way is needed to support thetexitfunction. One way is to construct a wrapper function, let the wrapper function calltentry, and calltexitaftertentryreturns, and then use this wrapper function as the real entry point ofkcontext(). However, this also requires us to pass the three parameters oftentry,parameterandtexitto the wrapper function. How should we solve this parameter-passing problem?
For context switching, you need to implement the rt_hw_context_switch_to() and rt_hw_context_switch() functions in rt-thread-am/bsp/abstract-machine/src/context.c:
void rt_hw_context_switch_to(rt_ubase_t to);
void rt_hw_context_switch(rt_ubase_t from, rt_ubase_t to);
The rt_ubase_t type is actually unsigned long, and to and from are pointers to context pointer variables (secondary pointers). rt_hw_context_switch_to() is used to switch to the context pointed to by the context pointer variable pointed to by to, and rt_hw_context_switch() also needs to write the current context pointer to the context pointer variable pointed to by from. In order to switch, we can trigger a self-trap through yield(), and then process to and from after identifying the EVENT_YIELD event in the event processing callback function ev_handler(). Similarly, we need to think about how to pass the two parameters to and from to ev_handler(). There is also a rt_hw_context_switch_interrupt() function in rt-thread-am/bsp/abstract-machine/src/context.c, but it will not be called during the current RT-Thread operation, so it can be ignored for now.
According to the analysis, the implementation of the above two functions needs to deal with some special parameter-passing issues. For context switching, taking rt_hw_context_switch() as an example, we need to call yield() in rt_hw_context_switch(), and then get from and to in ev_handler(). rt_hw_context_switch() and ev_handler() are two different functions, but due to the existence of the CTE mechanism, rt_hw_context_switch() cannot directly call ev_handler(). Therefore, a direct way is to use global variables to pass information.
Dangerous global variables
Global variables have only one copy in the entire system, which is usually safe if there is only one thread in the entire system. The programs we wrote in the C language class all belong to this situation, so using global variables does not cause obvious correctness problems. But if there are multiple threads in the system and their periods of using the same global variable overlap, it may cause problems.
However, our hardware currently does not implement interrupts or support multiple processors, From the programming model point of view, it is similar to the C language class, so it is still possible to use global variables to solve this problem.
Dangerous global variables (2)
If global variables are used to pass information, consider the following scenarios, what problems may occur?
- In a multi-processor system, two processors call
rt_hw_context_switch()at the same time - A thread calls
rt_hw_context_switch()and writes to the global variable, but a clock interrupt arrives immediately, causing the system to switch to another thread, but this thread also callsrt_hw_context_switch()
But for context creation, the problem is more complicated: the two threads calling rt_hw_stack_init() and executing the wrapper function are not the same.
Dangerous global variables (3)
If global variables are used to pass information, and the code calls rt_hw_stack_init() twice in a row, what problems will arise?
Therefore, we need to find another solution. Looking back, the reason why global variables cause problems is that they are shared by multiple threads. In order to get the right solution, we should do the opposite: use a storage space that is not shared by multiple threads. Hey, in fact, it has been mentioned in the previous article, that is the stack! We just need to let rt_hw_stack_init() put the three parameters of the wrapper function in the context stack, and in the future, when the wrapper function is executed, these three parameters can be taken out of the stack, and other threads in the system cannot access them.
Finally, we need to consider the number of parameters. kcontext() requires that the entry function can only accept a parameter of type void *. However, we can agree on what type to use to parse this parameter (integer, character, string, pointer, etc.), so this becomes a C language programming problem.
Create and switch context of RT-Thread through CTE
Implement relevant codes according to the above content. For the implementation of rt_hw_stack_init(), we have given the correct direction to solve the problem, But we did not point out all the details related to the implementation, and the rest is left to you to analyze and solve, This is also to test whether you have understood every detail of this process.
After implementation, try to run RT-Thread in NEMU. We have built some Shell commands into the ported RT-Thread. If your code is implemented correctly, you will see that RT-Thread executes these commands in sequence after startup, and finally outputs the command prompt msh >:
heap: [0x01000000 - 0x09000000]
\ | /
- RT - Thread Operating System
/ | \ 5.0.1 build Oct 2 2023 20:51:10
2006 - 2022 Copyright by RT-Thread team
[I/utest] utest is initialize success.
[I/utest] total utest testcase num: (0)
Hello RISC-V!
msh />help
RT-Thread shell commands:
date - get date and time or set (local timezone) [year month day hour min sec]
......
msh />utest_list
[I/utest] Commands list :
msh />
Since NEMU does not currently support interaction via the serial port, we cannot transmit the input on the terminal to RT-Thread. After all built-in commands are completed, RT-Thread will enter the idle state, and you can exit NEMU at this time.
Context switch on native
Since native AM will enable interrupts by default when creating a context, in order to successfully run the kernel thread created by native, You also need to identify the clock interrupt event in the event processing callback function. We will introduce the content related to clock interrupts at the end of PA4. Currently, after identifying the clock interrupt event, you don't need to do anything, just return the corresponding context structure.
Dangerous global variables (4)
Can we implement context switching without using global variables?
Similarly, we need to find a storage space that is not shared by multiple threads. However, for the thread that calls rt_hw_context_switch(), its stack is being used, and writing data to it may be overwritten, or even overwrite existing data, causing the current thread to crash. Although the stack of to is not currently in use and will not be shared by other threads, we need to consider how to allow ev_handler() to access the stack of to, which is back to the problem we wanted to solve at the beginning.
In addition to the stack, is there any other storage space that is not shared by multiple threads? Hey, in fact, it has been mentioned in the previous article, that is PCB! Because each thread corresponds to a PCB, and a thread will not be scheduled multiple times at the same time, So passing information through PCB is also a feasible solution. To get the PCB of the current thread, naturally use the current pointer.
In RT-Thread, you can return the PCB of the current thread by calling rt_thread_self(). Reading the definition of the PCB structure in RT-Thread, we find that there is a member user_data, which is used to store the private data of the thread, This means that the scheduling-related code in RT-Thread will definitely not use this member, so it is very suitable for us to use to pass information. However, in order to avoid overwriting the existing data in user_data, we can save it in a temporary variable first, and restore it before switching back to the current thread next time and returning from rt_hw_context_switch(). As for this temporary variable, of course, a local variable is used. After all, local variables are allocated on the stack, perfect!
However, the functions provided by AM are not as rich as those of other BSPs. Some more complex functions in RT-Thread also require support from the underlying hardware, such as network, storage, etc. Therefore, we can only run a subset of RT-Thread on AM at present, but this is enough for our testing and demonstration.
Nanos-lite
RT-Thread is a complete OS, but its kernel code has about 16,000 lines of code. In comparison, Nanos-lite has less than 1,000 lines of code, which is more suitable for everyone to learn the core principles. Therefore, subsequent experiments will still be based on Nanos-lite.
The functions and data structures needed for Nanos-lite context switching are very similar to those of yield-os, but due to the larger code size of Nanos-lite, they are scattered in different files, and you need RTFSC to find them. In addition, the framework code of Nanos-lite has defined the PCB structure, which also contains other members that are not currently used, we will introduce them in the future.
Implement context switching in Nanos-lite
Implement the following functions:
- Nanos-lite's
context_kload()function (the prototype of this function is not given in the framework code), It further encapsulates the process of creating kernel context: callkcontext()to create the context, and record the returned pointer to thecpof the PCB - Nanos-lite's
schedule()function - After Nanos-lite receives the
EVENT_YIELDevent, callschedule()and return the new context
Nanos-lite provides a test function hello_fun() (defined in nanos-lite/src/proc.c), You need to create two contexts with hello_fun as the entry in init_proc():
void init_proc() {
context_kload(&pcb[0], hello_fun, ???);
context_kload(&pcb[1], hello_fun, ???);
switch_boot_pcb();
}
The call to switch_boot_pcb() is to initialize the current pointer. You can agree on the type of parameter arg to be parsed (integer, character, string, pointer, etc.), Then modify the output code in hello_fun() to parse arg in the way you agreed. If your implementation is correct, you will see that hello_fun() will output information of different parameters in turn.
Context switch on native
Since native AM will enable interrupts by default when creating a context, in order to successfully run the kernel thread created by native, You also need to identify the clock interrupt event in the event processing callback function. We will introduce the content related to clock interrupts at the end of PA4. Currently, after identifying the clock interrupt event, you don't need to do anything, just return the corresponding context structure.
User Process
Create User Process Context
Creating the context of a user process requires some additional considerations. In the batch processing system of PA3, we directly transfer the code of the user process through a function call in naive_uload(). At that time, the kernel stack was still used. If a stack overflow occurred, the operating system data would indeed be damaged. However, there was only one user process running at that time, so we did not pursue it. But in a multi-programming operating system, there are more than one process running in the system. If the user process continues to use the kernel stack, if a stack overflow occurs, it will affect the operation of other processes, which is what we do not want to see.
What to do if a kernel thread has a stack overflow?
If it can be detected, the best way is to trigger a kernel panic, because the kernel data is no longer reliable at this time. If a corrupted data is written back to the disk, it will cause irreparable and devastating damage.
The good news is that the correctness of kernel threads can be guaranteed by kernel developers, which is at least much simpler than guaranteeing the correctness of unknown user processes. The bad news is that most kernel bugs are caused by third-party drivers: Stack overflows are rare, and more are use-after-free, double-free, and elusive concurrency bugs. Faced with a large number of third-party drivers, it is difficult for kernel developers to guarantee their correctness one by one. If you think of a way to improve the quality of driver code, it is to contribute to the field of computer systems.
Therefore, unlike kernel threads, the code, data and stack of user processes should all be located in the user area, and it is necessary to ensure that the user process can and can only access its own code, data and stack. To distinguish them, we call the stack in the PCB the kernel stack, and the stack in the user area the user stack. So we need a way different from kcontext() to create the context of the user process. For this purpose, AM has prepared an additional API ucontext() (defined in abstract-machine/am/src/nemu/isa/$ISA/vme.c), and its prototype is
Context* ucontext(AddrSpace *as, Area kstack, void *entry);
Among them, the parameter as is used to limit the memory that the user process can access. We will use it in the next stage, so you can ignore it for now; kstack is the kernel stack, which is used to allocate the context structure, and entry is the entry point of the user process. Since we have ignored the as parameter, the implementation of ucontext() is almost the same as kcontext(), even simpler than kcontext(): no parameters need to be passed. But you still need to think about what state the user process needs to start execution.
Hey, where is the user stack? In fact, the allocation of the user stack is independent of ISA, so the user stack-related parts are handed over to Nanos-lite, and ucontext() does not need to be processed. At present, we let Nanos-lite use heap.end as the top of the stack of the user process, and then assign this top of the stack to the stack pointer register of the user process.
Oops, the stack pointer register is ISA-related, and it is not convenient to handle it in Nanos-lite. Don't worry, remember the _start of the user process? Some ISA-related operations can be performed there. So Nanos-lite and Navy agreed: Nanos-lite sets the top of the stack to GPRx, and then the _start in Navy sets the top of the stack to the stack pointer register.
Nanos-lite can encapsulate the above work into the context_uload() function so that we can load the user process. We replace one of the hello_fun() kernel threads with the Legend of Sword and Fairy:
context_uload(&pcb[1], "/bin/pal");
Then we also need to call yield() at the beginning of serial_write(), events_read() and fb_write() to simulate the slow device access situation. After adding, context switching will be performed when accessing the device, thus realizing the function of a multi-programming system.
Implement a multiprogramming system
According to the above content of the lecture notes, implement the following functions to implement a multiprogramming system:
- VME's
ucontext()function - Nanos-lite's
context_uload()function (the prototype of this function is not given in the framework code) - Set the correct stack pointer in Navy's
_start
If your implementation is correct, you will be able to run Chinese Paladin while outputting hello messages. It should be noted that in order for AM native to run correctly, you also need to set the correct stack pointer in Navy's _start.
Think about it, how to verify that Chinese Paladin is indeed using the user stack instead of the kernel stack?
A great man cannot tolerate a rival?
Try replacing hello_fun() with hello in Navy:
-context_kload(&pcb[0], (void *)hello_fun, NULL);
+context_uload(&pcb[0], "/bin/hello");
context_uload(&pcb[1], "/bin/pal");
What problem did you find? Why is it like this? Think about it, the answer will be revealed in the next stage!
Parameters of the user process
When we implemented the kernel thread, we passed it an arg parameter. In fact, user processes can also have their own parameters, which are argc and argv that you learned in the programming class. There is also envp that you may not be familiar with. envp is an environment variable pointer, which points to a string array. The format of the string is like xxx=yyy, which means there is a variable named xxx, and its value is yyy. When we initialize the PA project through init.sh in PA0, it will define some environment variables in the .bashrc file, such as AM_HOME. When we compile FCEUX, the make program will parse the content in fceux-am/Makefile, When encountering
include $(AM_HOME)/Makefile
, it will try to use the library function getenv() to find a string in the string array pointed to by envp. If there is a string like AM_HOME=yyy, it will return yyy. If AM_HOME points to the correct path, the make program can find the Makefile file in the abstract-machine project and include it.
In fact, the complete prototype of the main() function should be
int main(int argc, char *argv[], char *envp[]);
So, when we type in the terminal
make ARCH=x86-nemu run
How are the two parameters ARCH=x86-nemu and run and the environment variables passed to the main() function of the make program?
Since the user process is created by the operating system, it is natural that the operating system is responsible for the transmission of parameters and environment variables. The most suitable place to store parameters and environment variables is the user stack, because when switching to the user process for the first time, the content on the user stack can be accessed by the user process. Therefore, when the operating system loads the user process, it is also responsible for placing argc/argv/envp and the corresponding strings in the user stack, and making their storage method and location one of the agreements with the user process, so that the user process can access them according to the agreement in _start.
This convention actually belongs to the content of ABI. The ABI manual has a section on Process Initialization. It stipulates in detail what information the operating system needs to provide for the initialization of the user process. But in our Project-N system, we only need a simplified version of Process Initialization: The operating system places argc/argv/envp and its related contents on the user stack, and then sets GPRx to the address where argc is located.
| |
+---------------+ <---- ustack.end
| Unspecified |
+---------------+
| | <----------+
| string | <--------+ |
| area | <------+ | |
| | <----+ | | |
| | <--+ | | | |
+---------------+ | | | | |
| Unspecified | | | | | |
+---------------+ | | | | |
| NULL | | | | | |
+---------------+ | | | | |
| ...... | | | | | |
+---------------+ | | | | |
| envp[1] | ---+ | | | |
+---------------+ | | | |
| envp[0] | -----+ | | |
+---------------+ | | |
| NULL | | | |
+---------------+ | | |
| argv[argc-1] | -------+ | |
+---------------+ | |
| ...... | | |
+---------------+ | |
| argv[1] | ---------+ |
+---------------+ |
| argv[0] | -----------+
+---------------+
| argc |
+---------------+ <---- cp->GPRx
| |
The above figure divides these parameters into two parts, one part is the string area, The other part is the two string pointer arrays argv/envp. Each element in the array is a string pointer. These string pointers will point to a certain string in the string area. In addition, Unspecified in the above figure represents an interval of any length (can also be 0), The order of each string in the string area is not required, as long as the user process can access the correct string through argv/envp. The placement format of these parameters is very similar to the description in the ABI manual. You can also refer to a diagram in Chapter 7 of the ICS textbook.
Read the ABI manual and understand the computer system
In fact, the ABI manual is a bridge between ISA, OS, compiler, runtime environment, C language, and user process. It is worth reading by everyone. Most of the conventions in ICS textbooks that make you confused are also from the ABI manual. The ABI followed on Linux is System V ABI, which is divided into two parts, Part of it is processor-independent generic ABI (gABI), such as ELF format, dynamic connection, file system structure, etc.; The other part is the processor specific ABI (psABI) related to the processor, such as calling convention, operating system interface, program loading, etc. You should at least read the table of contents of the ABI manual and look through the pictures in the text, so that you will have a general understanding of the ABI manual. If you are willing to think deeply about "why it is agreed like this", then you have truly "understood the computer system in depth".
According to this convention, you also need to modify the _start code in Navy to pass the address of argc as a parameter to call_main(). Then modify the code of call_main() so that it parses the real argc/argv/envp and calls main():
void call_main(uintptr_t *args) {
argc = ???
argv = ???
envp = ???
environ = envp;
exit(main(argc, argv, envp));
assert(0);
}
In this way, the user process can receive the parameters belonging to it.
Pass parameters to the user process
The essence of this task is a pointer-related programming exercise, But you need to pay attention to writing portable code, because call_main() is shared by various ISAs. Then modify a small amount of code in Chinese Paladin, if it receives a --skip parameter, Just skip the playback of the opening trademark animation, otherwise it will not be skipped. Implementing this function will help speed up the testing of Chinese Paladin. The playback of trademark animation is not far from the main() function in terms of code logic, so I leave it to you to RTFSC.
However, in order to pass parameters to the user process, you also need to modify the prototype of context_uload():
void context_uload(PCB *pcb, const char *filename, char *const argv[], char *const envp[]);
This way you can directly give the parameters of the user process in init_proc() for testing: Give the --skip parameter when creating the Chinese Paladin user process, and you need to observe that Legend of Sword and Fairy does indeed skip the trademark animation. Currently, environment variables are not used in our test program, so there is no need to pass real environment variable strings. As for what the actual parameters should be written, this is another pointer-related issue, so I’ll leave it to you to solve.
It is unrealistic for the operating system to manually set parameters for each user process. Because the parameters of the user process should still be specified by the user. So it would be best to have a way to tell the operating system the parameters specified by the user. Let the operating system put the specified parameters into the user stack of the new process. This method is of course the system call SYS_execve. If you look at man, you will find that its prototype is
int execve(const char *filename, char *const argv[], char *const envp[]);
Why is there a const missing?
In the main() function, the types of argv and envp are char * [], In the execve() function, their types are char *const []. Judging from this difference, the strings pointed to by argv and envp in the main() function are writable, Do you know why this happens?
In order to implement SYS_execve with parameters, we can directly call context_uload() in sys_execve(). But we also need to consider the following details, for the convenience of description, We assume that user process A will execute another new program B through SYS_execve.
- How to create user process B in the execution flow of A?
- How to end the execution flow of A?
To answer the first question, we need to review what is required to create user process B. The first step is to create the context structure of B in the kernel stack of PCB. This process is safe because the kernel stack of the current process is empty. The next step is to place the parameters of user process B in the user stack. But this will involve a new question: Can we still reuse the same user stack located near heap.end?
In order to explore this problem, we need to understand what is already in A's user stack when Nanos-lite tries to load B through SYS_execve. We can list the contents of the user stack from the bottom of the stack (heap.end) to the top of the stack (the current position of the stack pointer sp):
- The user process parameters (
argc/argv/envp) passed by Nanos-lite for A before - A stack frame for function calls starting from
_start. This stack frame will continue to grow untilexecve()in libos is called. - The context structure saved by CTE, which is caused by A executing the system call trap instruction in
execve() - Nanos-lite starts the stack frame of function call from
__am_irq_handle(), This stack frame will keep growing until the system call handler ofSYS_execveis called.
Through the above analysis, we come to an important conclusion: when loading B, Nanos-lite uses A's user stack! This means that before A's execution flow ends, A's user stack cannot be destroyed. Therefore, the user stack near heap.end cannot be reused by B. We should allocate a new memory as B's user stack, so that Nanos-lite can place B's parameters in this newly allocated user stack.
To achieve this, we can let context_uload() uniformly obtain the memory space of the user stack by calling the new_page() function. The new_page() function is defined in nanos-lite/src/mm.c, which manages the heap area through a pf pointer. It is used to allocate a continuous memory area of size nr_page * 4KB and return the first address of this area. We let context_uload() allocate 32KB of memory as the user stack through new_page(), which is enough for the user program in PA. In addition, for simplicity, we do not need to implement free_page() in PA.
Memory management of operating system
We know that the malloc() function in klib can also manage the heap area, so that AM applications can easily apply for dynamic memory. However, as a special AM application, the operating system often has stricter requirements for dynamic memory application. For example, when applying for a memory area with a starting address that is an integer multiple of 4KB, malloc() usually cannot meet such requirements. Therefore, the operating system generally manages the heap area by itself, and will not call malloc() in klib. Managing the heap area in the operating system is the work of the MM (Memory Manager) module, which we will introduce in the subsequent content.
Finally, in order to end the execution flow of A, we can modify the current current pointer through switch_boot_pcb() after creating the context of B, and then call yield() to force triggering process scheduling. In this way, the execution flow of A will no longer be scheduled, and when it is next scheduled, B can be resumed and executed.
Implement execve() with parameters
According to the above lecture notes, implement execve() with parameters. There are some details that we have not fully given, For example, what content should be passed to pcb parameter when calling context_uload()? This question is left to you to think about!
After implementation, run the following program:
- The test program
navy-apps/tests/exec-test, which will continuously execute itself with increasing parameters. However, since we have not implemented heap area memory recycling, after runningexec-testfor a period of time,new_page()will allocate memory near0x3000000/0x83000000, causing the code segment of the user process to be overwritten. We can't fix this at the moment, you just need to see thatexec-testcan run correctly for a while. - MENU boot menu.
- Improve NTerm's built-in Shell so that it can parse input parameters and pass them to the started program. For example, you can type
pal --skipin NTerm to run Chinese Paladin and skip the trademark animation.
Run Busybox
We have successfully run NTerm, but there are not many shell tools to run. Busybox busybox is used to solve this problem. It is a collection of streamlined shell tools, which contains the common functions of most common commands. Oh, your usual experience of using the command line in Linux will soon be presented in the computer system built by yourself!
Navy's framework code has prepared a compilation script for Busybox. When you compile Busybox for the first time, the script will automatically clone the project and use the configuration file provided by the framework code. Busybox contains many small tools. You can
make menuconfig
to open a configuration menu to view them (but do not save changes to the configuration). The configuration file provided by the framework code has only a few tools selected by default. This is because most tools require more system call support to run, so we cannot run them on Nanos-lite.
Busybox links the Shell tools into an ELF executable file, unlike the Shell tools in Ubuntu/Debian and other distributions, where each tool is an independent ELF executable file. Busybox's main() function calls the corresponding tool's function based on the passed parameters:
if (strcmp(argv[1], "cat") == 0) return cat_main(argc, argv);
else if (strcmp(argv[1], "ls") == 0) return ls_main(argc, argv);
else if (strcmp(argv[1], "wc") == 0) return wc_main(argc, argv);
// ......
Busybox provides a simple installation script that allows users to easily use these gadgets by creating a series of soft links:
$ ls -lh navy-apps/fsimg/bin
total 1.6M
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 base64 -> busybox
-rwxr-xr-x 1 yzh yzh 161K Oct 21 12:11 bird
-rwxr-xr-x 1 yzh yzh 126K Dec 9 12:12 busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 cat -> busybox
-rwxr-xr-x 1 yzh yzh 33K Oct 20 20:43 cpp-test
-rwxr-xr-x 1 yzh yzh 29K Dec 9 12:12 dummy
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 echo -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 ed -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 false -> busybox
-rwxr-xr-x 1 yzh yzh 33K Dec 9 12:12 hello
-rwxr-xr-x 1 yzh yzh 81K Dec 9 12:12 menu
-rwxr-xr-x 1 yzh yzh 91K Dec 9 12:12 nterm
-rwxr-xr-x 1 yzh yzh 586K Dec 9 12:12 onscripter
-rwxr-xr-x 1 yzh yzh 390K Dec 9 12:12 pal
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 printenv -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 sleep -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 true -> busybox
In this way, when we type the cat command, we actually execute /bin/busybox, which makes it execute the cat_main() function linked to Busybox.
Run Busybox
Try to run some simple commands in Busybox through NTerm, such as cat and printenv. If you don't know how to use these commands, you can check them through man. Be careful not to let the output of these commands drown out the information printed by hello_fun(). For this reason, you may need to adjust the frequency of hello_fun() printing information.
Some tools are not placed in the /bin directory, but in the /usr/bin directory, such as wc. In order to avoid entering the full path, we can also add /usr/bin to the PATH environment variable. Different paths are separated by :. The specific format can refer to the result of running the echo $PATH command on Linux. In this way, we can use a library function execvp() to try to traverse all paths in PATH, until an existing executable file is found, and then SYS_execve will be called. You can read navy-apps/libs/libc/src/posix/execvp.c to understand how this function is implemented.
However, in order to traverse the paths in PATH, execvp() may try to execute a non-existent user program, such as /bin/wc. Therefore, when Nanos-lite processes the SYS_execve system call, it needs to check whether the program to be executed exists. If it does not exist, it needs to return an error code. We can check it through fs_open(). If the file to be opened does not exist, it returns an error value, and SYS_execve returns -2. On the other hand, execve() in libos also needs to check the return value of the system call: If the return value of the system call is less than 0, it usually means that the system call failed. At this time, the return value of the system call needs to be negative, set as the reason for failure to a global external variable errno, and then return -1.
-2 and errno
errno is a global variable defined by the C standard and in the runtime environment, which is used to store the error code of the most recent failed system call or library function call. You can view all error codes and their meanings by running the command errno -l (you need to install the moreutils package through apt-get). You should see that error code 2 is an error that you are familiar with. For more information about the errno global variable, refer to man 3 errno.
Run Busybox(2)
Implement the above content and let execvp() support PATH traversal. Then try to run wc and other commands in the /usr/bin directory through NTerm, For example, wc /share/games/bird/atlas.txt. You can check whether the result is correct by running the corresponding command on Linux. In addition, you can read the code of execvp() to help you judge whether the return value is set correctly.
Although we can only run a few Busybox tools on Nanos-lite at present, you basically present a scene very similar to your usual use of Linux command line tools in the computer system you built. We put this into the system stack of Project-N to let you understand what the various abstract layers of the computer system do when you usually type commands:
- How does the terminal read the user's keystrokes?
- How does the Shell parse the command?
- How does the library function search for the executable file based on the string parsed by the command?
- How does the operating system load and execute an executable file?
- ......
Although there are still huge differences between Project-N and the real Linux system, completing PA independently can help you eliminate the mystery of "how programs run on computers" to a great extent.
Friendly reminder
PA4 Phase 1 ends here.