Write an immortal legend
At the end of the PA, let's do something fun.
Showcasing your computer system
Currently, Nanos-lite can run up to four processes simultaneously. We can utilize all four processes effectively. Specifically, we can load "PAL", "Flappy Bird", "NSlider", and "hello" programs. We can maintain the current foreground program through a variable called fg_pcb, enabling the foreground program and the "hello" program to run alternately. In detail, within the events_read() function of Nanos-lite, we can bind the keys F1, F2, and F3 to three foreground programs. For example, at the beginning, "PAL" and the "hello" program can run alternately. After pressing F2, it switches to "Flappy Bird" and the "hello" program running alternately.
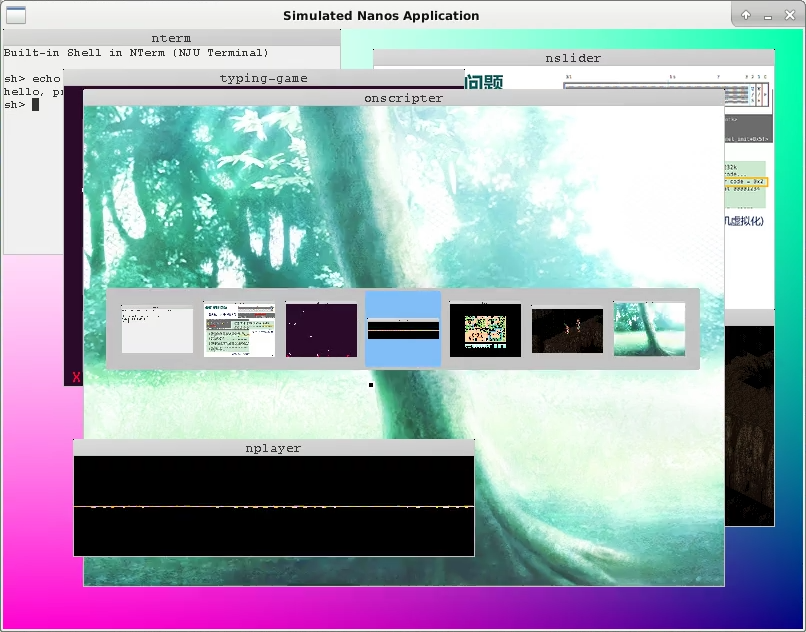
Moreover, you can also load three startup menu programs or NTerm. With VME support, they can be switched freely, just like playing three NES games simultaneously. It's pretty cool!
Showcase your computer system
Add foreground programs and their switching functionality to showcase your personally created computer system.
Run ONScripter simulator
Try in the new branch
The following are optional tasks and may introduce incompatible changes to the mandatory parts, if you wish to explore these contents, please create a new branch and make the code modifications there.
ONScripter is an open-source NScripter script engine which could be used to run text adventure games written in coresponding script. we cloned the project from this repo and ported it to Navy. Running make init in the navy-apps/apps/onscripter/ directory will clone the ported project from github. The ported project can still run on Linux native: To compile ONScripter to Linux native, execute make in the repo/ directory. However, you may need to install some libraries. Please STFW to resolve this; Next, download some smaller ONS games for testing (e.g., "Dream of the Stars," approximately 100MB; please search the web for details). After extracting the game, launch it with the following command:
./repo/build/onscripter -r GAME_EXTRACTION_PATH
Since it runs on Linux native, you can use the mouse to play the game. You can also use arrow keys to move the cursor and use ENTER to confirm or ESC to cancel actions.
In order to port ONScripter to Navy, we first need to know what libraries ONScripter depends on. You can find out which libraries you depend on by reading the LDFLAGS variable in navy-apps/apps/onscripter/repo/Makefile:
SDL- In Navy, we use libminiSDL to provide function compatible functionality.SDL_ttf- This is a TrueType font library, In Navy, we utilize libminiSDL and TrueType font parser in project stb, to provide partial API compatibility withSDL_ttf, primarily for rasterzing TrueType fonts.SDL_image- This is a image library, In Navy, we utilize libminiSDL and image decoders in project stb, to provide partial API compatibility withSDL_image, mainly for decoing JPG, PNG, BMP and other image formatsSDL_mixer- This is an audio mixing library, In Navy, we use libminiSDL and libvorbis to provide partial API compatibility withSDL_mixer, primarily for implementing multi-channel OGG audio mixing.bz2- This is a compression library, In Navy, we have removed the functionality related to accessing compressed files from ONScripter, Therefore, when compiling for Navy, ONScripter's execution does not depend on the compression library.m- This is the math library of glibc. In Navy, libfixedptc provides some floating-point arithmetic functionalities.
Caching and font rasterization
The TTF_RenderGlyph_Shaded() function in navy-apps/libs/libSDL_ttf/src/ttf.c is used to rasterize a character from the font library, generating the corresponding pixel information and a color palette. The code adds a small cache when generating the color palette, do you know how it works? Why does it improve performance? (though not by a huge margin).
It should be noted that due to some shortcomings of the above mentioned libraries in Navy, we can't run all ONS games perfectly on Navy. Specifically:
- The rasterization algorithm used by the truetype parser in the stb project may not be able to rasterize some truetype fonts well, resulting in less spaced text, which is not as effective as the Linux native
SDL_ttflibrary - The library in Navy only supports decoding OGG audio, so it does not support ONS games that need to play other audio formats (e.g. MP3).
Supplementing SDL-related libraries
Let's first consider running ONScripter on Navy native. Since ONS games generally requires a larger screen to run, we need to define macro MODE_800x600 in navy-apps/libs/libos/src/native.cpp. Afterwards, we we can try to run ONScripter on Navy native:
cd navy-apps/apps/onscripter
make ISA=native run mainargs="-r GAME_EXTRACTION_PATH"
If you see the terminal output something like the following, ONScripter has successfully read the game information:
ONScripter-Jh version 0.7.6 (20181218, 2.96)
Display: 800 x 600 (32 bpp)
Audio: -937182692 Hz 0 bit stereo
Where the display resolution is related to the specific ONS game, the output of the audio information is some garbage, this is because we haven't implemented the sound mixing library yet. Next ONScripter may trigger an assertion fail in the miniSDL library, or report that it cannot open the file and exit.
In order for ONScripter to run successfully, we need to add to the implementation of the miniSDL library. The additional features include (be sure to RTFM for details):
timer.c: Add timer registration and removal functions. The implementation of the callback function can be referred to the implementation of the audio data filling in PA3.
// register a counter, invoke callback function after `interval` milliseconds
SDL_TimerID SDL_AddTimer(uint32_t interval, SDL_NewTimerCallback callback, void *param);
// remove previously registered conuter
int SDL_RemoveTimer(SDL_TimerID id)
event.c: Add event queuing and checking. SDL supports user-defined events, so we need a queue to buffer unprocessed events. After implementing the event queue, we can add the key events that read from NDL to the event queue viaSDL_PushEvent()so that we can handle all kinds of events in a unified way.
// add an event `ev` to the event queue
int SDL_PushEvent(SDL_Event *ev);
// Perform the `action` on the first `numevents` events in the event queue that match the mask.
// macro `SDL_EVENTMASK()` well illustrate the meaning of `mask`
// In NScripter, `numevents` is always 1 and `action` is always `SDL_GETEVENT` which could be used to simplify implementation
int SDL_PeepEvents(SDL_Event *ev, int numevents, int action, uint32_t mask);
file.c: The SDL library provides user programs with a unified interface such asSDL_RWread(),SDL_RWwrite(). It also abstracts file operations on various platforms through function pointers, so that users do not need to care about the details of specific file operations. This idea is very similar to the VFS we introduced in PA3, see here. In ONScripter, we only use ordinary files and "memory files", you need to implement the corresponding file operations for them. An "in-memory file" is a section of memory that is treated as a sequence of bytes and is accessed through file operations. Note that the semantics and return values of these operations may differ from the corresponding library functions in libc, so please RTFM carefully.
glibc support for in-memory files
In fact, glibc provides a library function at fmemopen() to support in-memory file manipulation. You can use fmemopen() to greatly simplify your implementation, please refer to RTFM for details.
Apart from miniSDL library, we also need to implement another two APIs in SDL_image. The first API is
SDL_Surface* IMG_Load_RW(SDL_RWops *src, int freesrc);
It is very similar to the IMG_Load() in PA3, except that it decodes the pixel infomation of the image from the SDL abstract file. When used by ONScripter, the type of src is always an in-memory file, while freesrc is always 0 , and this information can help you simplify your implementation.
The second API is
int IMG_isPNG(SDL_RWops *src);
It is used to determine whether the SDL abstract file src is an image file in PNG format. The best way to determine the type of a file is to check the magic number stored in the file: recall that we consider a file to be an ELF file when it has a magic number of 0x7f 0x45 0x4c 0x46. PNG files have a similar magic number, please STFW for more details.
Running ONScripter
After conquering the above tasks, you can run in ONScripter Navy native! There's no sound yet, but you can still see the image and manipulate it.
Since Navy doesn't support mouse, you can only use keyboard to perform operation. We add a simple cursor of 4x4 pixels to the ONScripter code, so you can see the cursor move when you type the arrow keys. However, the implementation of this simple cursor is not perfect, sometimes you will see more than one cursor on the screen.
Implementation of the mixer library SDL_mixer
This part is totally optional
Pre-task: Implement NDL and miniSDL audio playback in PA3.
Is should be noted that even without implementing a sound mixing library, ONScripter can still run without audio (but cannot support auto-reading). However, audio counts a lot in terms of text adventure gameplay experience.
Multiple audio clips are usually played at the same time in a game, for example, during a battle, there will be a background music BGM, the sound effect of the spell will be played during the casting of the spell, and the sound effect of the enemy's injury will be played when the spell causes damage to the enemy. From the player's point of view, these audio clips are played simultaneously, and the mixer library SDL_mixer is used to manage multiple audio clips and realize the effect of simultaneous playback through mixing.
First we provide the manual for the mixer library SDL_mixer. Although the manual describes a lot of APIs, we don't need to implement all of them. The APIs used by ONScripter are listed at navy- apps/libs/libSDL_mixer/src/mixer.c . We don't need to implement all of them, some of which are just used for linking and ONScripter doesn't call them when running some of the games. It is important to note that when implementing these APIs, please be sure to read the details via RTFM.
Is is possible to utilize the API of SDL sould to implement SDL_mixer. Specifically, you can call SDL_OpenAudio() and SDL_PauseAudio() from Mix_OpenAudio() and SDL_CloseAudio() from Mix_CloseAudio(). Recall that SDL_OpenAudio() needs to provide a callback function to populate the audio data, so the implementation of SDL_mixer can be divided into two parts, one for implementing various APIS that maintain the audio state and the other for implementing the real mixer effect in the callback function.
Play BGM
Playing BGM is relatively simple, so we can implement it first. Specifically, you need to implement the following API:
Mix_Music *Mix_LoadMUS_RW(SDL_RWops *src);
void Mix_FreeMusic(Mix_Music *music);
int Mix_PlayMusic(Mix_Music *music, int loops);
int Mix_VolumeMusic(int volume);
int Mix_HaltMusic();
int Mix_PlayingMusic();
Since there is only the BGM audio, no other sound effect audio exists. We need to do the mixing in the callback function so that we can realize the BGM playback.
Playing BGM in ONScripter
Implement the above API to play ONS game BGM in ONScripter.
In these APIS, Mix_PlayMusic() is used to start playing a piece of music, which can be done by opening an audio file via stb_vorbis_open_memory() in libvorbis and then decoding the audio via stb_vorbis_get_samples_short_interleaved() in a callback function, It is suggested to read documentation in navy-apps/libs/libvorbis/include/vorbis.h or reference the implementation of NPlayer for more details. The rest of the API is related to audio state maintenance, so it's up to you to decide how to implement state maintenance.
BGM auto-replay in ONScripter
The SDL_mixer library supports auto-playback of audio: when the audio has finished playing, it is automatically replayed from the beginning, without the user having to play it manually. This is accomplished by using the loops parameter in Mix_PlayMusic(). In addition, you can tell if the audio has finished playing by the return value of stb_vorbis_get_samples_short_interleaved() You can also play the audio from the beginning by stb_vorbis_seek_start(), please RTFM for more details.
Once implemented correctly, you can enjoy auto-replayed BGM in ONScripter.
Play sound effects
In order to support the simultaneous playback of multiple sound effects, the SDL_mixer library refers to a sound object as a "chunk" and introduces the concept of a "channel". Users can put a clip on any channel to play. Multiple channels of the clip will be mixed with the BGM so as to realize the effect of BGM and multiple sound effects at the same time. Note that the "channel" in SDL_mixer and the "channel" in the audio files have different meaning although they have the same name. The following diagram well illustrates the difference between the two.
+---> Left Channel
+++-+
* = |L|R|
+-+++
+---> Right Channel
+-----+------------------------------------------------------------+-----+
Channel 1 | |************************ Chunk 1 ***************************| |
+-----+------------------------------------------------------------+-----+
+-----+-------------+--------------------+-------------------+-----------+
Channel 2 | |** Chunk 2 **| |***** Chunk 3 *****| |
+-----+-------------+--------------------+-------------------+-----------+
+---------------------------------+-------------+------------------------+
Channel 3 | |** Chunk 2 **| |
+---------------------------------+-------------+------------------------+
The above figure shows three channels, each of which plays its clip at the same time. When multiple channels need clips simultaneously, the callback function needs to mix them. Considering the clips themselves, they are dual-channel, i.e. each sample has both left and right channel data.
Once you understand the above concepts, you can implement the following APIs related to sound playback:
Mix_Chunk *Mix_LoadWAV_RW(SDL_RWops *src, int freesrc)
void Mix_FreeChunk(Mix_Chunk *chunk)
int Mix_AllocateChannels(int numchans);
int Mix_PlayChannel(int channel, Mix_Chunk *chunk, int loops);
int Mix_Volume(int channel, int volume);
void Mix_Pause(int channel);
void Mix_ChannelFinished(void (*channel_finished)(int channel));
Mix_AllocateChannels() is used to allocate the appropriate number of channels and Mix_ChannelFinished()is used to set a callback function to notify the user that the clip is finished,which is used by ONScripter to realize the auto-reading function of the text adventure game. The rest of the API is very similar to the corresponding API for BGM, but the object is now a channel, please refer to RTFM for the exact behavior.
Finally, you need to implement the mixing in the callback function that fills in the audio data: you need to check if the BGM and the channels are playing. If they are, you should mix the corresponding audio data accordingly..
Play sound effects in ONScripter
Implement the sound playback API and sound mixing functionality. Once implemented correctly, you will be able to run ONS games in ONScripter in a more complete way.
Conversion of sampling frequency and number of channels
ONScripter will initialize the audio device with "44100Hz Dual Channel" by default and ONS games can be played normally if the audio files match this attribute, such as "CLANNAD". However, if the audio files to be played do not have the "44100Hz Dual Channel" attribute, playing them directly will result in distortion. For example, in one of the ONS versions of "Ever 17", the BGM is sampled at 22050Hz, while in "Starscream", a few sound effects are even mono. In order to solve the distortion problem of these audio files, we need to do some conversion operations on the audio data.
The conversion operation is very simple: if the audio file is played with a sample frequency or number of channels smaller than the way the audio device is turned on, the audio file will be "expanded". Specifically, we just need to copy each decoded sample.
+-A-+-B-+-C-+
Before +-+-+-+-+-+-+
convertion |L|R|L|R|L|R|
22050Hz +-+-+-+-+-+-+
+-A-+-A-+-B-+-B-+-C-+-C-+
After +-+-+-+-+-+-+-+-+-+-+-+-+
convertion |L|R|L|R|L|R|L|R|L|R|L|R|
44100Hz +-+-+-+-+-+-+-+-+-+-+-+-+
=====================================
+A+B+C+
Before +-+-+-+
convertion |S|S|S|
mono +-+-+-+
+-A-+-B-+-C-+
After +-+-+-+-+-+-+
convertion |L|R|L|R|L|R|
stereo +-+-+-+-+-+-+
If the sampling frequency or number of channels of the audio file being played is greater than the way the audio device is turned on, the audio file is "truncated". However, most games do not have audio quality higher than "44100Hz Dual Channel", so we can leave this case alone.
One final question: How do we get the attributes of an audio file? It turns out that libvorbis library provides a stb_vorbis_get_info() API, which can be used to read out the properties of an audio file. Please refer to the implementation of NPlayer or RTFM for more detail.
Playing sound effects in ONScripter(2)
Converts audio data so that ONScripter can playback audio of different quality.
Implement disk
With the addition of the above library implementation, ONScripter will run perfectly on Navy native. In order to run ONScripter on AM native or NEMU, we also need to consider the storage space issue. AM native and NEMU both assume that the size of physical memory is 128MB, but ONS game data files generally occupy a lot of space. For example, Starscream's data files are nearly 100MB. Therefore, if we put them on ramdisk, we'll have less than 30MB of physical memory available to the system. (Actually it will be less, because Nanos-lite itself needs to load user processes and perform paging mechanism which also requires physical memory). As ONScripter engages in image and audio decoding, the system may be "running out of physical memory". The "CLANNAD" data file is nearly 1GB which makes it impossible to put into the ramdisk. Therefore, we need a storage device that doesn't use up physical memory, which is the disk.
Unlike ramdisk, the access latency of a actual disk is much higher compared to memory. If the disk can only be accessed to read or write one byte at a time, the efficiency of disk access is intolerably low. Therefore, disk controllers usually access disks in blocks, which are typically 512 bytes or more in size.
The IOE in AM has provided the abstraction for disk. Specifically, abstract-machine/am/amdev.h has provided three abstraction registers for disk:
AM_DISK_CONFIG: AM disk controller information, you can read the presence flagpresent, block sizeblkszand disk sizeblkcnt. In addition, AM assumes that the block size and disk size will not change while the system is running.AM_DISK_STATUS: AM Disk Status Register, reads whether the disk is currently in a ready state ready .AM_DISK_BLKIO: AM Disk Status Register, reads whether the disk is currently in a ready state ready . ifwriteis1, you can write theblkcntdisk block starting atbufto the diskblknolocation ifwriteis0, you can read theblkcntdisk block starting at theblknodisk block tobuf.
We start by implementing the disk on AM native. Since AM native can use the Linux runtime environment, we can easily access files on Linux, we just need a way for the AM native to know the path of disk image. Environment variables can make it:
const char *diskpath = getenv("diskimg");
After that, we could specify diskimg argument for make:
make ARCH=native run diskimg=$NAVY_HOME/build/ramdisk.img
You need to implement the above abstract register operations on the AM native's IOE:
AM_DISK_CONFIG- If the image indicated by
diskimgexists, set the flagpresentto1, otherwise set it to0. - Block size
blkszis set to512(bytes) - Disk size
blkcnti.e. the size of the image file is calculated in units ofblksz.
- If the image indicated by
AM_DISK_STATUS- We always assume the disk is ready.AM_DISK_BLKIO- This can be achieved by reading and writing files, but you need to pay attention to the unit conversion.
After implementing disks on AM native, we need to add disk support to Nanos-lite. Specifically, you need to implement the following API.
size_t disk_read(void *buf, size_t offset, size_t len);
size_t disk_write(const void *buf, size_t offset, size_t len);
void init_disk();
These APIs are very similar to the ramdisk API. You should also be aware that the file system sees sequences of bytes, whereas the disk can only be accessed in blocks. Therefore, you still need to do some unit conversion. To implement this, change the code at fs.c to replace ramdisk access with disk access. You also need to remove the ramdisk code from resources.S .
Implementing disks for AM native
Based on the above, add disk support to AM native and Nanos-lite. In addition, in order to make AM native support bigger screen, you need to add corresponding code accroding to this. Then, define a macro MODE_800x600.
If implementing correctly, you can run ONScripter in AM native.
Finally, In order to run ONScripter in NEMU, we need to add disk device support to NEMU(nemu/src/device/disk.c). First of all, let's make NEMU's disk device get the path to the image file by means of the following environment variable.
// Attention, below is the presudo code.
diskpath = getenv("NAVY_HOME") + "/build/ramdisk.img";
Then we need to add some device registers to allow the program to communicate with the disk device and access these device registers to implement the disk-related abstract registers in AM. For disk read/write operations, we can agree that the program writes other information to the device registers first, then writes the read/write command to a command register called CMD. When the disk device finds out that the command register has been written to, it will perform the specified read/write operation.
NEMU disk device read and write operations can also be achieved through file operations, but what is the buf address the program gives really means? It should be noted that this address may be passed all the way from the Navy application. However, Navy application can only understand virtual address but disk device can not . This is because the virtual address is the concept of the virtual memory mechanism provided by the MMU in the CPU If the device directly use this address for disk operations, it will lead to errors.
Devices that can understand virtual addresses
In fact, some complex modern devices can also understand virtual addresses. Inside these devices, there is a module called IOMMU, which is used to convert the virtual address issued by the device into the physical address before accessing the memory. In this way, the operating system can write the virtual address provided by the application directly to the device.
However, we need to face a problem: How can we ensure that the translation by the MMU in the CPU? If this translation is not consistent, the device will access the wrong physical memory location To solve this problem, the operating system also needs to maintain consistency between the CPU MMU and the IOMMU. Well, this topic is a little beyond the scope the PA. Let's not make it so complicated.
To solve this problem, we can add a small cache dedicated to disk reads and writes for Nanos-lite's disk support:
uint8_t blkbuf[blksz];
To read data from disk, first read the data block to blkbuf, then copy it to buf provided by application. To write data to disk, first write data to blkbuf, then write the from blkbuf to disk. It should be noted that blkbuf locates inside Nanos-lite. When paging is enabled, it is in a identity mapping of the address space, therefore, its virtual address can be used directly as a physical address. By this means, we solve the problem of the disk device not understanding the virtual address by using blkbuf as a relay.
Disk and cache
In previous section, we have just used a one-block sized cache. However, the cache for disk is mouch bigger in read operating system. In this case, the role of the disk cache is very similar to that of the CPU cache, both of which takes advantage of program locality to improve the performance of disk accesses.
Finally, although NEMU's disk device gets the physical address, the physical address is the pmem address that the client program sees. In order to call fread()/fwrite(), we also need to convert this physical address into a virtual address that NEMU can understand as a user process.
guest_to_host(addr - PMEM_BASE)
In this way, NEMU will be able to read and write images files via native glibc.
Implementing NEMU disks
Based on the above sections, add disk support for NEMU and corresponding AM. When compiling NEMU, you need to select the disk-related options in menuconfig It is up to you to decide which device registers are supported by NEMU's disk devices and where they are located.
In addition, in order for NEMU to support larger screens, you need to select the screen size of 800 x 600 in the menuconfig.
[*] Devices --->
[*] Enable VGA --->
Screen Size (800 x 600) --->
Once implemented correctly, you can run ONScripter on NEMU.
DMA and CPU cache
Among all the devices in NEMU, the disk is the most special, for it can access the physical memory directly. The way device works is called DMA. Modern CPUs are usually equipped with a cache, if the latest data that the disk wants to access is in the cache, then how should DMA access them? Please try STFW for this problem.
Next Semester Preview - Operating Systems Course Padding
ICS and PA serve as a precursor to the operating systems course which serves an important purpose to make you understand two concepts:
- The program is a state machine
- The computer is a layer of abstraction
The operating system is a very important abstraction layer in computers. I believe you know a little bit about it in the process of completing PA. As a emasculated OS, Nanos-lite can support quite a few complicated Navy apps such as "PAL". Then you might wonder, how far is the Nanos-lite from the actual operating system? We can experience some missing functionality of Nanos-lite in the computer system, PA, which makes your guys wonder what other questions need to be solved to be an actual operating system? This also serves as a foundation for the Operating Systems course in the next semester.
NWM Experience - Windows Manager NWM
We know that the hardware has limited physical resources. In order to facilitate the execution of multiple user processes, the operating system must contemplate how to allocate and manage these resources effectively.
In fact, you have already have a brief understanding of virtualization.
- NEMU imitates a phyical CPU but Nanos-lite can support multiple processes to access their own memory without overwriting each other. This is because Nanos-lite virtualizes the physical memory in NEMU, allocates a segment of virtual memory address space for each process and then maps the virtual address space of the process to the physical memory through a paging mechanism. The change in mapping is implemented via the context switch.
- NEMU simulates a segment of physical memory, but Nanos-lite can support multiple processes to access their own memory without overwriting each other. This is because Nanos-lite virtualizes the physical memory in NEMU, allocates a segment of virtual memory address space for each process and then maps the virtual address space of the process to the physical memory. The change in mapping is implemented via the MMU operation.
The concept of "process" in the operating system is implemented by means of virtualization (that's why we can't explain what a process is until PA4). User processes running on Nanos-lite can be reset to the initial state of the program by means of SYS_execve or exited by means of SYS_exit. However there is no way to create processes for user processes (if we create two processes in init_proc() , there will be no process using a third PCB in any case during the system operation).
In Unix-like operating systems, the creation of a process is realized by the system call SYS_fork which has a very special functionality that clones the current state of process which we consider as a state machine in its entirety, so that an "almost identical" (except for the difference in the return value of the system call) process is running in the system.
How to implement `fork()` in the operating system?
Think about how we could implement fork() in our operating system based the above introduction?
In fact, we can't implement this system call perfectly in Nanos-lite, so you are not required to do it in PA. However, we can still experience process creation in Navy's native. We provide an application called NWM (NJU Window Manager) in Navy. As the name suggests, NWM is a special application which can manage the window, so we can use it to create a new window, create a new process associated with this new window. Then let this new process execute execve() and we can achieve the effect of "executing a new program in a new window".
NWM support running 7 programs in default (see innavy-apps/apps/nwm/include/winimpl.h), If you do not accomplish optional tasks, you may not able to run some of the programs. However, There are three programs (NTerm, NSlider and PAL) that are ganrantee to work as long as you accomplish the required assignment. Because NWM needs more support from system call, we cannot run it in Nanos-lite. If you want to experience NWM, you are required to replace the program in navy-apps/fsimg/ to native in Navy:
cd navy-apps
make ISA=native fsimg # dummy can not compile to native, please remove it mannuly
Then you are able to run NWM in Navy native.
Experience window manager NWM (NJU Window Manager)
After launching NWM, there will be a menu bar showing below. You can use arrow keys to choose programs and enter to run. The keybindings to manage windows is listed below:
A-up(ALT + Arrow keys) - Move current window upA-down- Move current window downA-left- Move current window leftA-right- Move current window rightA-key that locates above the</code>(<code>tab) - Switch windowsA-R- Call the menu bar
Apart from the composite keys listed above, all other keys will be forwarded to the current window.
Keystroke buffering support
When implementing NDL in PA3, we assumed that at most one event would be read from /dev/events. However, if we press a key too fast in NWM, The NDL_PollEvent() in NDL might read out more than one key event at a time, which NDL may not be able to handle at the moment (resulting in a lost key or an assertion fail). In order to solve this problem perfectly, we can implement an event buffer in NDL_PollEvent(), if there is still an event in the buffer, it will return the event in the buffer, otherwise it will read the event into the buffer first.
How to implement NWM?
NWM is visually very similar to the GUI operating systems we normally use, but we implemented it in less than 1000 lines of code. You could investigate the source code of NWM if interested. If encountering any unfamiliar system call, there is no need to worry and believe you can understand it by RTFM. This also might serve as a preview for the operating system course in the next semester: You might encounter these system calls in class.
Experience concurency - Bug in drawing
Operating systems can support concurrent execution of multiple processes through virtualization. If these processes do things independently of each other, this is not a big problem. However, if these processes need to access the same resources, things can become problematic. For example, if multiple user processes write to the same file, it is possible to expect data loss. These problems are called concurrency bugs.
Experience concurrency bug in PA
In fact, there is a concurrency bug hidden in PA and we can expose it by doing the following. Let Nanos-lite load PAL and NTerm, then quickly type F1 and F2 to switch back and forth between PAL and NTerm. After a while, you may observe that the drawing is not correct: 
Think about why the bug occurs?
From the above experience, you should be able to appreciate the following characteristics of concurrency bugs:
- Difficult to observe - The behavior caused by concurrency is UB, anything can happen. Here we choose an example that is easier to observe: mapping. Imagine if the concurrency bug occurred elsewhere (e.g., access to a data structure in memory), how could we effectively observe it?
- Hard to repreduce - the behavior of the processes is correct when they are run individually, but can be wrong when they are run concurrently. Moreover, concurrency bugs are not reproducible for every operation, but depend on the order of execution between two (or more) processes: if the processes switch at the wrong time, the concurrency bug may not be reproducible. This directly increases the difficulty of debugging concurrency bugs.
- Difficult to understand - Even if we can observe and reproduce a concurrency bug, its cause is more difficult to understand than a normal bug. Normal bugs are better understood by understanding the behavior of a single process, but concurrency bugs are better understood by understanding not only the behavior of individual processes, but also by finding some kind of intertwining of the execution of multiple processes. There are many possibilities for such intertwining, which makes understanding concurrency bugs very challenging.
In order to solve the problem of concurrency, the operating system needs to provide the following mechanisms.
- Mutual exclusion - prevents multiple processes from accessing certain critical shared resources at the same time, thus avoiding the loss of data
- Synchronization - allows multiple processes to execute sequentially in a safe order.
Based on these mechanisms, an operating system can provide mechanisms for processes to communicate with each other. The ability of processes to work together on modern operating systems is also based on communication mechanisms. Window management in NWM is also realized through communication between parent and child processes.
Experience Persistence - Disk and Game Archives
The operating system, as the manager of computer system resources, needs to manage a class of devices directly related to data: storage devices. Data is the object of a program's processing, and the storage device is the carrier on which the data is stored, and the operating system must provide additional support to ensure that the program can access the data on the storage device correctly. For a storage device, the problem is the same as "how to get the data to be stored correctly and persistently".
If we take the abstraction layer related to storage device data access and discuss it separately, we get a "storage stack" that is very similar to the "system stack". It is not difficult to draw this "storage stack", which is equivalent to answering the following question:
How does "PAL" read pixel information from a file through layers of abstraction in a computer system??
Actually, you have already answered that in PA3.
In PA, we actually minimized the persistence problem: applications hardly ever write to the ramdisk (only when "PAL" archives). Therefore, the sfs we introduced in PA3 works very well and we can support the application's need for ramdisk access with a small amount of code.
But in a real computer system there cannot be no writes. The first problem when we considering writes is to redesign the file system: it is no longer a good idea to keep files sequentially on the storage device because this makes the operating system carry files of changing size back and forth across the storage device. The solution to this problem is very similar to the one we introduced in PA4 for virtual memory management. Recall how we solved the flaws in the segmentation mechanism of virtual memory management.
Now that we have write operations, the second question we need to consider is how to ensure that the write is successful. This may seem like a silly question. How can a write fail? Well, it does. First of all, we know that disks are accessed in blocks, so if a file is larger than a block, it has to be written several times, and if the system suddenly loses power in the middle of writing a file, the file will be damaged; furthermore, even when writing a block to a disk, it doesn't always succeed. For example, it may encounter a bad disk. Therefore, Windows will remind you not to turn off your computer during automatic updates, so that important system files are not damaged and the operating system does not boot. You might think as long as you don't force a shutdown, the probability of these events occurring is so low that you'll just have to resign yourself to them, but operating system designers can't think that way. They need to assume that their customers' data is incredibly valuable. While the OS has no way of preventing power- downs and bad sectors from occurring, it still needs to do what it can to keep the data from surviving these disasters or at least to avoid showing the user that a file is only half-written, which is called "crash consistency" in nature.
Experiencing "crash inconsistency" in PA
The archive architecture in "PAL" SAVEDGAME_COMMON is defined innavy-apps/apps/pal/repo/src/global/global.c. Modify the code of ramdisk_write() of Nanos-lite so that it writes to N bytes and returns directly to it in order to simulate a system power-down. You can carefully calculate N according to the definition of the archive structure so that only part of the data is written to the archive. For example, if you archive after a battle and then read the archive right away, you may see that the money is updated, but the character's experience is not.
If you implement the optional contents of the disk, it's even easier: you just need to trigger assert(0) randomly at the write code of the NEMU disk device. That way, you're likely to read a corrupted archive next time. You don't have to worry about not getting the right archive back because we can make a new image of the right disk.
VMs and crash consistency
If you're doing labs in vitural machine, you may have encountered a situation where a virtual machine is running but the real machine crashes. And the virtual machine is corrupted after a reboot. This problem is related to crash consistency. For applications inside a virtual machine, the storage stack to which they write data is actually very deep: the data passes through the storage stack of the client machine before reaching the file management module of the virtual machine software (VMWare or VirtualBox), then the data passes through the storage stack of the real machine before reaching the real storage device. Therefore, the crash consistency of a virtual machine is more difficult to ensure than a normal program. From this perspective, forcing a virtual machine to shut down is more likely to cause problems than forcing a real machine to shut down.
Even if the data is successfully written, there is a third issue to consider: what if the data is read incorrectly? Storage devices are not 100% reliable and as they age, this problem may become more apparent. If you store a file on a bad USB flash drive today, you may be prompted with a "corrupted file" message when you open the file tomorrow. You've probably heard of the solution to this problem, which is multi-copy backups + checksum/error correction, but how to do it efficiently is another question.
Finally, in order to improve the performance of accessing the storage device, the operating system typically adds a cache at some level of the storage stack so that instead of writing data directly to the storage device every time, the operating system finds a way to keep the data in the cache for as long as possible. But this is a clear conflict with the goal of persistence, which is to write data to disk as quickly as possible. The trade off between performance and persistence is a major challenge in operating system design.
If you find that you never have to think about these issues when you write your application, that's a good sign that the operating system has solved them so well that we, as users of the operating system, don't perceive them.
What is operating system?
We've given you a brief overview of the challenges of virtualization, concurrency, and persistence in operating systems. But the most complex problem for a system comes from the interaction between the various mechanisms: what happens when multiple processes execute fork() and then concurrently read and write the same file on disk via mmap()?
This question is not intended to be difficult: real problems are likely to arise from the interaction of multiple modules and mechanisms, To solve real problems you need to learn to think systematically from multiple perspectives. The operating system is one of the most complex pieces of software in the world and I'm sure you'll come to appreciate the complexity of the system in your next semester of study.
OSlab has come!
course website see here.
From one to infinity
In fact, computer systems work by doing only two things.
- make things work
- make things work better
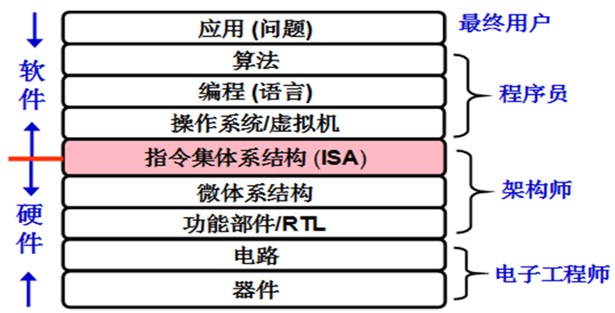
PA allows you to experience the whole process of making things work. Specifically, PA demonstrates the synchronized evolution of hardware, runtime environment (OS) and application from scratch, using AM as the main thread.
- TRM - Hardware with instructions and memory to run all computable algorithms with virtually no runtime environment.
- IOE - Hardware adds inputs and outputs, the runtime environment provides an abstraction for device access to run a single interactive program.
- CTE - Add exception handling to the hardware and context management to the runtime environment to support a batch system that allows user programs to run sequentially and automatically.
- VME - Hardware add virtual memory mechanism, runtime environment add virtual memory management, can support time-sharing multitasking, let multiple users program running time-sharing.
Required Questions
The exact process of time-sharing multitasking Please explain how the paging mechanism and hardware interrupts support the time-sharing of the PAL and hello programs on our computer system (Nanos-lite, AM, NEMU) with code examples.
Understanding Computer Systems Try writing and running the following programs in Linux:
int main() {
char *p = "abc";
p[0] = 'A';
return 0;
}
You will see that the program triggers a segmentation error when writing to a read-only string. Please analyze "how the write-protection mechanism for strings is implemented" from the point of view of the program, compiler, linker, runtime environment, operating system and hardware. In other words, what happens to the computer system that triggers a segmentation error when the above program executes p[0] = 'A' ? How does the computer system guarantee that a segmentation error will occur? How can you use the right tools to prove your idea?
Friendly Notice
This is the end of PA4. Please prepare a lab report (don't forget to answer the mandatory questions in the lab report), then place the lab report file named 学号.pdf in the project directory. Then place the lab report file named 学号.pdf in the project directory and execute make submit to package the project, and finally submit the compressed package to the specified website.
Welcome Second playthrough
What have you learned in the first playthrough? You will understand in the second playthrough: It is what you find easy to implement that you have learned.
This is the end for PA4.
And various principles and Methodology of course
In addition to "how a program is executed in a computer", PA also demonstrates many principles and ways of doing things. Which ones do you recall now?
If you can't remember, or recall every detail of "how a program is executed in a computer", then maybe you should try to complete the second cycle on your own. Stick with it, and you'll get a whole new understanding of these issues.
But in order to make things work better, various technologies have been developed.
Interactive era
As far as hardware is concerned, Moore's Law predicts that integrated circuits will become more and more integrated. This was a free lunch for computers: even if the hardware architects and software designers did nothing, the circuits in the chips get smaller, faster and more power efficient. This development in circuitry led directly to the creation of workstations and PCs, and PCs with small chips began to be available to the general public. This meant that computers were no longer limited to military tasks such as nuclear bomb simulations and code-breaking as they had been in the 40s and 60s, but needed to interact with the average user which needed an interactive operating system, the most famous of which were Unix and DOS. Along with Unix came another program that has survived to this day, the C language. With the C compiler, some professional users could develop their own programs. Office and programming were the most common applications of that era.
Witnessing the rapid growth of Moore's Law, it's clear that hardware architects are not immune to it. Circuits are getting smaller and smaller, meaning that more components can fit on the same size chip, enabling more complex control logic. In terms of hardware microarchitecture, one route to increased performance is to increase parallelism, from multi-stage pipelining, superscalar, to out of order execution, SIMD, hyperthreading et al. Another route to improve performance is to utilize locality, thus cache, TLB, branch prediction, and replacement algorithms and prefetching algorithms et al. With these techniques, CPUs spend much less time waiting for but more time doing computation. Every time a new term is used, it pushes the performance of computers upwards. As computers get faster, they can do more complex things. An example of this is the GUIs that have lowered the barriers to using computers, as time-sharing and multitasking operating systems on PCs have become more common. Therefore, recreational applications such as music, video, and game begin to appear on a large scale.
PC's Footprints
PC's Footprints series of blog posts provides a brief introduction to the history of the PC, covering most of the terminology mentioned above. This a great reading material for people who are interested in PC, especially suitable for reading in leisure time. In addition, there is a timeline of the x86 family, so it's good to know the background to the various technologies as well as the context in which they were developed.
The aforementioned microarchitecture techniques all aim to enhance the performance of a single processor (scale up). However, mainframes and supercomputers have long employed these technologies, boosting their performance in another dimension: by using on-chip interconnect technology (interconnect) to link more processors together and enable them to work collaboratively (scale out). This has led to the development of SMP, ccNUMA, MPP, and various interconnect topologies. To efficiently address the data-sharing challenges in multiprocessor architectures, cache coherence and memory consistency have gradually come into focus. To accommodate on-chip interconnect technology, centralized operating systems capable of managing numerous processor resources have been designed. Along with this, new programming models have emerged, enabling the development and execution of applications on these powerful computers. Previously, scientific computing applications such as atmospheric simulations and physical modeling could now run faster and more efficiently on these supercomputers. However, scaling on-chip interconnect technology remains challenging; the cost of large-scale processor interconnects is prohibitively high, making it feasible primarily for supercomputers.
Interconnect era
Without the widespread adoption of the internet, the development of computers might have plateaued. The standardization of the TCP/IP protocol solved the transmission control issues of the internet, allowing it to expand from local area networks to a global scale, thus giving birth to the true Internet. The Internet transformed people into global villagers; with just a single network cable, anyone could easily access computers in any corner of the world. On the other hand, the emergence of HTTP and URL made the Internet widely known to the public. Web browsing, email, file transfer, and instant voice communication became popular network applications, allowing users to see the entire world through their PC screens.
Besides personal computers, the advent of the internet also made interconnectivity between machines possible, leading to the development of clusters. Clusters require a distributed operating system to manage numerous computing resources, and corresponding distributed programming models began to emerge. Tasks that used to run on a single computer can now be written in distributed versions to run across a cluster. The emergence of clusters addressed the cost issue of system scalability. With just a few inexpensive computers and some network cables, a cluster could be formed. Consequently, internet companies began to spring up like mushrooms after a rain, marking the beginning of the interconnected era for humanity.
As clusters expanded further, they evolved into data centers. Since clusters were so easy to build, there was an abundance of machines but a shortage of programs to run on them. Meanwhile, Moore's Law continued to advance, and to further exploit processor parallelism, multicore architectures emerged. The combination of clusters and multicore architectures led to an oversupply of computing resources, resulting in very low utilization rates in data centers. This gave rise to virtualization technology. With the support of a hypervisor, a single computer could run multiple different operating systems simultaneously. But this was not enough. To further improve the utilization of clusters, internet companies began renting out virtual machines to customers, allowing them to run their own systems and applications freely. Later on, hardware manufacturers added virtualization support to their chips, reducing the performance overhead of virtualization. As a result, the performance of virtual machines increasingly approached that of physical machines. This opened the door to cloud computing, leading to a growing number of applications moving to the cloud.
Moreover, the birth of the iPhone redefined the concept of the phone, transforming it from a communication tool into a bona fide computer. Thus, mobile processors and mobile operating systems came back into focus. Unlike PCs, mobile processors and operating systems have to tackle the severe challenge of power consumption. A plethora of mobile applications began to emerge, and various apps, including instant messaging and mobile payments, have significantly changed user habits. Many applications started adopting a hybrid model of edge and cloud computing. Now, when we tap the WeChat app icon on our phone, the login request is transmitted over the network to the cloud, where it is processed by hundreds of servers in a data center, before we finally see the login screen.
Convergence era
The internet connected people and computers, but that was not the end. Moore's Law continued to progress, reducing the size of processors further. What used to be devices connected to computers can now have computers embedded within them. Consequently, various small devices and objects can also connect to the internet, leading to the advent of the Internet of Things (IoT).
As more people, machines, and things connect to the internet, the amount of data generated by these endpoints is increasing exponentially, ushering in the era of big data. According to IBM, in 2012, approximately 2.5 exabytes (1EB = 10^6TB) of data were produced daily. To handle this vast amount of data, the concepts of artificial intelligence (AI) and machine learning (ML) have regained popularity. However, this brought about a massive data processing challenge, prompting GPUs and FPGAs to join the prolonged battle of big data processing. Another formidable force is the ASIC, which differs from CPUs in that it is a specialized circuit optimized for a specific application. For instance, AI chips, compared to CPUs, can improve performance-to-power ratios by thousands of times. The emergence of AlphaGo showcased the immense power of artificial intelligence. Nowadays, AI chips have begun to be integrated into smartphones, making photos more beautiful and applications smarter with use.
In this era, it seems like nothing is impossible. The boundaries between computers, users, networks, devices, cloud, data, and intelligence are becoming increasingly blurred. Users who directly interact with applications are increasingly unaware of the underlying operating systems and hardware. This, in turn, highlights that the fundamental principles of computing have left an indelible mark on the evolution of technology.
The Monarch of Changes - Computers Revisited
What is a computer? How can seemingly ordinary machinery build such a colorful computer world? What do cool game graphics have to do with cold circuits?
"Where did the One originate? "Where does infinity lead us? Ponder these questions and you will realize that there is so much to explore in the world of CS.
The Story of the Birth of the World - Final Chapter
Thank you for helping the Herald create this wonderful world! As well as writing a monumental saga for yourself! Hope you can share the success with us! ^_^
This is the end of the story. PA is also coming to an end, but there is no end to the exploration of computers. If you want to know what this wonderful world has become, look in the IA-32 manual. Or perhaps, with the creativity you've learned from the pioneers, you can change the course of this wonderful world and write a new chapter in the story.