Beyond capacity limits
There is some reason why modern operating systems do not use segmentation. Research shows that 1,000 servers in Google data centers ran thousands of different programs within 7 minutes. Some of them are huge guys (when Google develops programs internally, in order to avoid the problem of incompatibility of dynamic libraries on different computers, All libraries used become part of the program through static linking. The code segment of the program alone is hundreds of MB or even GB in size. Interested students can read this article), some are just some small test programs.
There is no benefit in letting these programs with different characteristics all occupy contiguous storage space: On the one hand, those huge guys will only touch a small part of the code in a run. In fact, there is no need to allocate so much memory to load them all; On the other hand, after the mini program ends, the storage space it occupies is released. It is also easy to become a "fragment hole" - only smaller programs can use the fragment hole. The simplicity of the segmentation mechanism may come at a huge cost in reality.
In fact, we need a virtual memory management mechanism that allocates on demand. The reason why the segmentation mechanism cannot achieve on-demand allocation is because the granularity of the segments is too large. To achieve this, we need to do the opposite: Divide the continuous storage space into small fragments, and organize, allocate and manage these small fragments as units. This is the core idea of the paging mechanism.
Memory Paging
In the paging mechanism, these small fragments are called pages, which are also called virtual pages and physical pages in the virtual address space and physical address space respectively. What the paging mechanism does is to map each virtual page to the corresponding physical page. Obviously, this mapping relationship is not as simple as what can be described by only one segment base address register in the segmentation mechanism. The paging mechanism introduces a structure called "page table". Each entry in the page table records the mapping relationship between a virtual page and a physical page, to reorganize physical pages that are not necessarily contiguous into contiguous virtual address space.
Therefore, in order for the paging mechanism to support the operation of a multi-tasking operating system, the operating system first needs to manage memory in units of physical pages. Whenever a program is loaded, corresponding physical pages are allocated to the program (note that these physical pages do not have to be consecutive). Prepare a new page table for the program, and fill in the mapping relationship between the virtual pages used by the program and these physical pages in the page table. When the program runs, the operating system sets the page table previously filled in for the program into the MMU. The MMU will perform address translation based on the contents of the page table, mapping the program's virtual address space to the physical address space desired by the operating system.
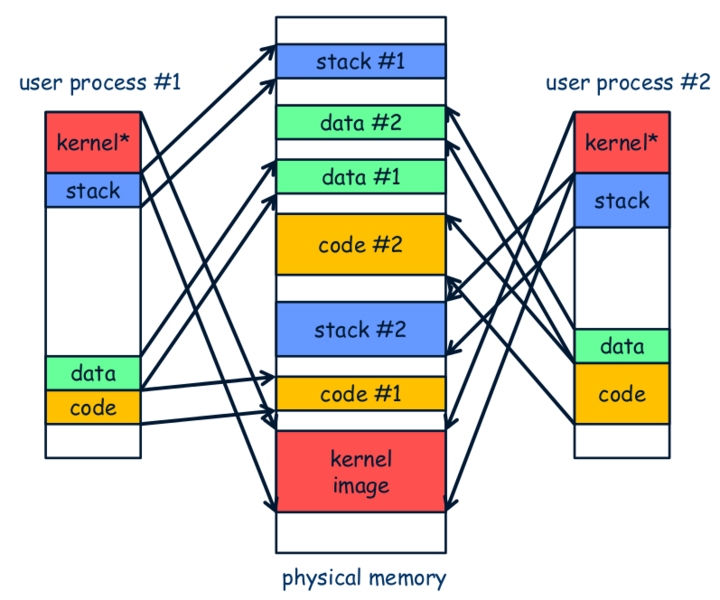
The benefits of PIC in virtual memory management
We mentioned before that one of the benefits of PIC is that code can be loaded into any memory location for execution. If combined with virtual memory management, what new benefits does PIC have? (Hint: Dynamic libraries are already enjoying these benefits)
i386 is the first processor in x86 history to introduce a paging mechanism. It divides physical memory into pages in units of 4KB. At the same time, the structure of the secondary page table is also adopted. In order to facilitate the description, i386 gave the first-level page table a new name called "page directory". Although it sounds amazing, the principle is actually the same. Each page directory and page table has 1024 entries, and the size of each entry is 4 bytes. In addition to containing the base address of the page table (or physical page), it also contains some flag information.
Therefore, the size of a page directory or page table is 4KB, which is impossible to put in a register, so they have to be stored in memory. In order to find the page directory, i386 provides a CR3 (control register 3) register, which is specially used to store the base address of the page directory. In this way, page-level address translation is performed step by step starting from CR3, and finally the virtual address is converted into a real physical address. This process is called a page table walk.
PAGE FRAME
+-----------+-----------+----------+ +---------------+
| DIR | PAGE | OFFSET | | |
+-----+-----+-----+-----+-----+----+ | |
| | | | |
+-------------+ | +------------->| PHYSICAL |
| | | ADDRESS |
| PAGE DIRECTORY | PAGE TABLE | |
| +---------------+ | +---------------+ | |
| | | | | | +---------------+
| | | | |---------------| ^
| | | +-->| PG TBL ENTRY |--------------+
| |---------------| |---------------|
+->| DIR ENTRY |--+ | |
|---------------| | | |
| | | | |
+---------------+ | +---------------+
^ | ^
+-------+ | +---------------+
| CR3 |--------+
+-------+
We are not going to give a detailed explanation of the paging process. Please combine the content of the i386 manual with the knowledge in the classroom. Try to understand the i386 paging mechanism, which is also an exercise in paging mechanism. The i386 manual contains all the information you want to know, including table entry structures not mentioned here, how addresses are divided, etc.
Understanding paging details
- Isn't i386 a 32-bit processor? Why does the base address information in the table entry only have 20 bits instead of 32 bits?
- The manual mentions that the base addresses in the entries (including CR3) are physical addresses. Is the physical address necessary? Can I use a virtual address?
- Why not use a first-level page table? Or what are the disadvantages of using a first-level page table?
The process of page-level conversion is not always successful, because i386 also provides a page-level protection mechanism, and the protection function depends on the flag bit in the table entry. We give a brief explanation of some flags:
- The present bit indicates whether the physical page is available. When it is not available, there are two situations:
- The physical page is swapped to the disk due to swapping technology. This is one of the Page fault situations you are most familiar with in class. At this time, you can notify the operating system kernel to change the target page back, so that execution can continue.
- The process attempts to access an unmapped linear address. There is no actual physical page corresponding to it, so this is an illegal operation.
- The R/W bit indicates whether the physical page is writable. If a read-only page is written, it will be judged as an illegal operation.
- The U/S bit indicates the permissions required to access the physical page. If a ring 3 process attempts to access a ring 0 page, it will of course be judged as an illegal operation.
Understand the paging mechanism
The above only introduces the paging mechanism of i386. In fact, the paging mechanisms of other ISAs are also similar. After understanding the i386 paging mechanism, the paging mechanisms of mips32 and riscv32 are not difficult to understand.
Of course, the specific details still need to be RTFM.
riscv64 needs to implement a three-level page table
The Sv32 mechanism of riscv32 can only perform address translation on 32-bit virtual addresses, but the longest virtual address of riscv64 is 64 bits. Therefore, another mechanism is needed to support address translation for longer virtual addresses. In PA, if you choose riscv64, you only need to implement the paging mechanism of Sv39 three-level page table. Moreover, PA will only use 4KB small pages and will not use 2MB large pages, so you do not need to implement the large page function of Sv39. Please RTFM for specific details.
Is a null pointer really "null"?
The teacher in the programming class told you that when the value of a pointer variable is equal to NULL, it means empty and does not point to anything. Think about it carefully, is this really the case? When the program dereferences the null pointer, what exactly is done inside the computer? What new insights do you have about the nature of null pointers?
Compared with the segmentation mechanism, the paging mechanism is more flexible and can even use virtual addresses that exceed the upper limit of physical addresses. Now we understand these two points from a mathematical perspective. Leaving aside the storage protection mechanism, we can abstract the segmentation and paging processes into two mathematical functions:
y = seg(x) = seg.base + x
y = page(x)
As you can see, the seg() function just does addition. If only the segmentation mechanism is used, we also require that the result of segment-level address translation cannot exceed the upper limit of the physical address:
y = seg(x) = seg.base + x < PMEM_MAX
=> x < PMEM_MAX - seg.base
=> x <= PMEM_MAX
We can draw this conclusion: using only the segmentation mechanism, the virtual address cannot exceed the physical address limit. The paging mechanism is different. We cannot give a specific parsing formula for page(). This is because filling in the page directory and page table is actually defining the page() function by enumerating independent variables. This is the fundamental reason why the paging mechanism is more flexible than the segmentation mechanism.
Although the constraint that "the page-level address translation result cannot exceed the upper limit of the physical address" still exists, But we only need to ensure that each function value does not exceed the upper limit of the physical address. There is no obvious restriction on the value of the independent variable. Of course, the independent variable itself can be larger than the function value. This has already demonstrated the two characteristics of "flexibility" of paging and "allowing the use of more than the upper limit of the physical address".
i386 adopts segment page storage management mechanism. But if you think about it carefully, this is just a combination of segmentation and paging. If you use a mathematical function to understand it, it is just a composite function:
paddr = page(seg(vaddr))
"Virtual address space" and "physical address space" are two extremely important concepts in operating systems. It is nothing more than the domain and value range of this composite function.
Finally, can a processor that supports paging recognize what a page table is? Let’s understand this problem with an example of address translation of a first-level page table with a page size of 1KB:
pa = (pg_table[va >> 10] & ~0x3ff) | (va & 0x3ff);
It can be seen that the processor does not have the concept of a table: the process of address translation is nothing more than some memory access and bit operations. This again shows us the nature of computers: A bunch of wonderful gates and circuits that contain profound mathematical wisdom and engineering principles! However, these small gate operations have become the foundation of today's multi-tasking operating systems. Supporting the operation of thousands of programs, in the final analysis, it is still inseparable from the core idea of computer system abstraction.
Virtual memory management mechanism from the perspective of state machine
From a state machine perspective, what is the virtual memory management mechanism?
In order to describe the behavior of the virtual memory management mechanism from the state machine perspective, we need to extend the memory access behavior of the state machine S = <R, M>. Specifically, we need to add a function fvm: M -> M, which is the mapping of the address translation we discussed above. Then replace all accesses to M in the state machine M[addr] with M[fvm(addr)], which is the behavior of the virtual memory management mechanism. For example, the instruction mov $1, addr, when the virtual memory mechanism is turned off, its behavior is defined by TRM:
M[addr] <- 1
When the virtual memory mechanism is turned on, its behavior is:
M[fvm(addr)] <- 1
We have just discussed that the process of address translation can be achieved through memory access and bit operations. This shows that the behavior of the fvm() function can also be described from a state machine perspective.
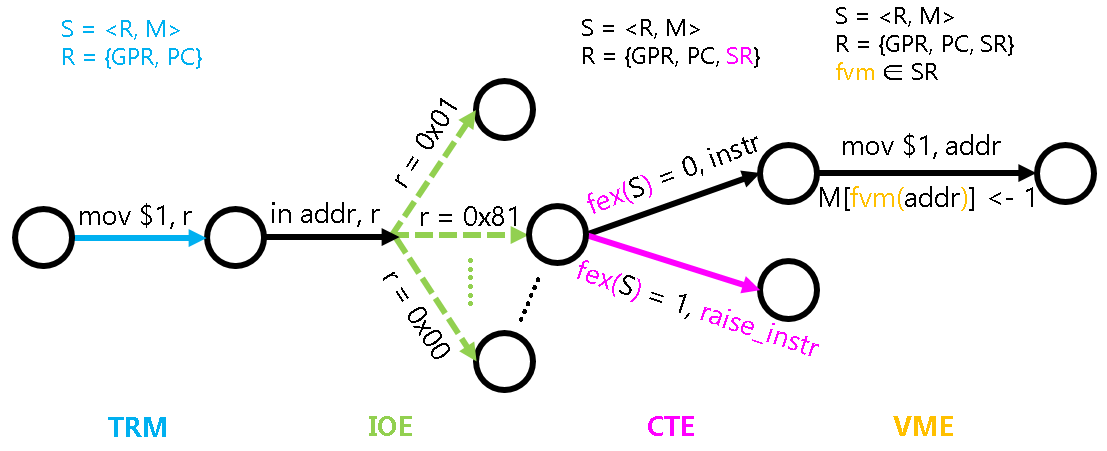
What is more special is the function fvm(). Looking back at the fex() function introduced in the state machine model introduced in PA3, It is not actually part of the state machine, because the way to judge whether an exception is thrown has nothing to do with the specific state of the state machine. The fvm() function is different. It can be regarded as part of the state machine. This is because the fvm() function is programmable: the operating system can decide how to establish the mapping between virtual addresses and physical addresses. Specifically, the fvm() function can be considered as part of the system register SR, and the operating system manages virtual memory by modifying SR.
TLB - Acceleration of address translation
If you are careful, you will find that without changing the page directory base address, page directory and page table, the contents of the same virtual page are accessed continuously, the results of page-level address translation will be the same. In fact, this situation is too common. For example, when a program needs to fetch instructions, The execution of instructions generally follows the principle of locality, and in most cases is executed in the same virtual page. But performing a page table walk requires accessing memory. If there is a way to avoid these unnecessary page table walks, This can improve the performance of the processor.
A natural idea is to store the results of page-level address translation. Before performing the next page-level address translation, check whether the virtual page has been translated. If so, just retrieve the previous results directly, thus saving unnecessary page table walks. Isn't this exactly the idea of cache? Such a special cache is called TLB. We can understand the organization of TLB from the knowledge of CPU cache:
- The basic unit of TLB is an item, which stores the result of a page-level address translation. (In fact, it is a page table entry, including the physical page number and some flags related to the physical page), which is functionally equivalent to a cache block.
- The tag of the TLB item is acted by the virtual page number, indicating which virtual page number this item corresponds to.
- The number of TLB entries is generally small. In order to improve the hit rate, TLB generally adopts a fully associative or group associative organization method.
- Since once the page directory and page table are established, the entries in them are generally not modified at will, so the TLB does not have problems with write strategy and write allocation methods.
Practice has shown that the hit rate of a TLB of 64 entries can be as high as 90%. With the TLB, unnecessary page table walks are greatly saved.
Sounds really good! However, in modern multi-tasking operating systems, simply using the TLB in the above manner will lead to fatal consequences. We know that the operating system will allocate different page directories and page tables to each process, although both processes may start executing from 0x8048000. However, the paging mechanism will map them to different physical pages to achieve storage space isolation. Of course, the operating system also needs to update the contents of CR3 when switching processes. Make the CR3 register point to the page directory of the new process, so as to ensure that the paging mechanism maps the virtual address to the physical storage space of the new process.
Here comes the problem, assuming there are two processes, for the same virtual address 0x8048000, The operating system has set up the correct page directory and page table, allowing process No. 1 to be mapped to physical address 0x1234000. Process No. 2 is mapped to physical address 0x5678000, and it is assumed that all entries in the TLB are invalidated at the beginning. At this time, process No. 1 runs first, accesses the virtual address 0x8048000, checks the TLB and finds a miss, so the page table walk is performed. Perform page-level address translation based on the page directory and page table of process No. 1, obtain the physical address 0x1234000, and fill the TLB. Assume that a process switch occurs at this time, and it is the turn of process No. 2 to execute. It also needs to access the virtual address 0x8048000 and check the TLB. A hit is found, so instead of performing a page table walk, the physical page number in the TLB is used directly to obtain the physical address 0x1234000. Process No. 2 actually accessed the storage space of Process No. 1, but neither Process No. 2 nor the operating system knew about it!
The reason for this fatal error is that the TLB does not maintain the consistency between the virtual address mapping relationship and processes: The TLB only knows that there is a mapping relationship from virtual address 0x8048000 to physical address 0x1234000. But it doesn't know which process this mapping relationship belongs to. After finding the cause of the problem, it is easy to solve it. Just add a domain ASID (address space ID) to the TLB entry. It can be used to indicate the process to which the mapping relationship belongs. This is what mips32 does. The x86 approach is more "barbaric", forcing the contents of the TLB to be flushed every time CR3 is updated. Since process switching must be accompanied by CR3 updates, when one process is running, there will be no mapping relationship for other processes in the TLB. Of course, in order to prevent excessive flushing, there is a Global bit in the page table entry, and those mapping relationships with a Global bit of 1 will not be flushed. For example, you can set the Global bit of the page where do_syscall() is located in the kernel to 1, In this way, TLB misses will not occur during system call processing.
Software managed TLB
For x86 and riscv32, TLB is generally managed by hardware: When the TLB misses, the hardware logic will automatically perform a page table walk and fill the address translation result into the TLB. The software does not know and does not need to know the details of this process. This is good news for PA: since it is transparent to the software, it can be simplified. So if you choose x86 or riscv32, you don't have to implement the TLB in NEMU.
But mips32 is different. In order to reduce the complexity of hardware design, Mips32 stipulates that both page table walk and TLB filling are responsible for software. Naturally, in mips32, TLB miss is designed as an exception: When the TLB misses, the CPU will throw an exception, and the software will perform page table walk and TLB filling.
Therefore, mips32 needs to expose the status of the TLB to the software so that the software can manage the TLB. In order to achieve this, mips32 needs to add at least the following:
- CP0 register, including entryhi, entrylo0, entrylo1, index. The entryhi register stores information related to the virtual page number, and the entrylo0 register and entrylo1 register store information related to the physical page number.
- CP0 instruction
- tlbp, used to find the TLB entry matching the entryhi register. If found, the index register is set to the serial number of the TLB entry.
- tlbwi, used to write the contents of the three registers entryhi, entrylo0 and entrylo1 to the TLB entry indicated by the index sequence number
- tlbwr, used to write the contents of the three registers entryhi, entrylo0 and entrylo1 to a random TLB entry
- Let mtc0 and mfc0 support access to the above four CP0 registers
Is TLB management simpler for MIPS32?
Some argue that the paging mechanism of MIPS32 is simpler. Do you agree? Try to answer this question both now and after completing this part of the content.
TLB management is a typical example of the tradeoff between software and hardware considerations. MIPS32 delegates this task to software, undoubtedly introducing additional performance overhead. In some embedded scenarios where performance is not crucial, this might not pose significant issues. However, in high-performance-oriented environments, this seemingly simple mechanism becomes a source of performance bottlenecks. For instance, in data center scenarios where programs access a vast amount of data with poor locality, TLB misses are common. In such cases, the performance overhead of software-managed TLB is further amplified.
In MIPS32, to further reduce the performance overhead caused by page table walks, each TLB entry actually manages the mapping relationship between two contiguous virtual pages. Consequently, there are two registers related to physical page numbers: entrylo0 and entrylo1. They respectively represent the physical page numbers corresponding to these two virtual pages. Specifically, assuming both virtual and physical addresses are 32 bits long, and utilizing a 4KB page size, the virtual page number in the entryhi register is 19 bits, while the physical page numbers in the entrylo0 and entrylo1 registers are each 20 bits. The advantage of this arrangement is that during a single page table walk, the address translation results for two virtual pages can be simultaneously filled, with the expectation of gaining some performance benefits through program locality. However, in the face of data center scenarios, these optimizations are merely drops in the bucket.
Abstracting Virtual Memory Management into VME
The specific implementation of virtual memory management naturally varies depending on the architecture. For instance, in x86, the control register CR3 is used to store the base address of the page directory, while on RISC-V32, it has a different name, and the instruction to access this register is also different. Furthermore, different architectures may have varying page sizes and page table entry structures, not to mention that some architectures may even have more than two levels of page table structures. Therefore, we can categorize the functionality of virtual memory management into a new API under the umbrella of AM (Architecture Abstraction Layer), named VME (Virtual Memory Extension).
As usual, let's consider how to abstract the functionality of virtual memory management into a unified API. In other words, what is the essence of the virtual memory mechanism? We have already discussed this issue earlier: the virtual memory mechanism, simply put, is a mapping (or function). That is to say, the fundamental task of virtual memory management is to maintain this mapping. However, this mapping should be maintained separately by each process, so we need the following two APIs:
// Create a default address space
void protect(AddrSpace *as);
// Destroy a default address space
void unprotect(AddrSpace *as);
AddrSpace is a struct type that defines the structure of the address space descriptor (defined in abstract-machine/am/include/am.h):
typedef struct AddrSpace {
int pgsize;
Area area;
void *ptr;
} AddrSpace;
The pgsize is used to indicate the size of the page, area represents the range of user mode in the virtual address space, and ptr is an ISA-specific pointer to the address space descriptor, used to indicate the specific mapping.
With the address space established, we naturally need corresponding APIs to maintain them. Therefore, the following APIs are introduced:
void map(AddrSpace *as, void *va, void *pa, int prot);
It is used to map the virtual page at the virtual address va within the address space as, to the physical page at pa, with the permissions specified by prot. When the present bit in prot is 0, it means that the mapping for va is invalidated. Since we do not plan to implement a protection mechanism, the prot permissions will not be used for now.
The main functions of Virtual Memory Environment (VME) have already been abstracted through the three APIs mentioned above. Finally, there are two more unified APIs:
bool vme_init(void *(*pgalloc_f)(int), void (*pgfree_f)(void *))
Used for VME-related initialization operations. It also accepts two pointers to page allocation callback functions from the operating system, allowing the Abstract Machine (AM) to request/release a physical page when necessary through these two callback functions.
Context* ucontext(AddrSpace *as, Area kstack, void *entry)
Used to create user process contexts. We have previously introduced this API, but with the addition of virtual memory management, some modifications need to be made to the implementation of this API, which will be detailed later.
Next we will introduce how Nanos-lite uses the mechanism provided by VME.
Run Nanos-lite based on the paging mechanism
Since the page table is located in memory, and at the time of computer startup, there is no valid data in memory, it is not possible to enable the paging mechanism right at startup. In order to start the paging mechanism, the operating system first needs to prepare some kernel page tables. The framework code has already implemented this functionality for us (see the vme_init() function in abstract-machine/am/src/$ISA/nemu/vme.c). You just need to define the macro HAS_VME in nanos-lite/include/common.h, and Nanos-lite will first call the init_mm() function (defined in nanos-lite/src/mm.c) to initialize MM during its initialization. Here, MM refers to the Memory Manager module, which is specifically responsible for paging-related storage management.
The initialization of the Memory Manager (MM) currently involves two main tasks. The first task is to use the heap start address provided by the TRM (Terminal Resource Manager) as the starting address for free physical pages. This setup allows the system to allocate free physical pages later through the new_page() function. To simplify the implementation, MM can sequentially allocate physical pages and does not require recycling after allocation. The second task involves calling the vme_init() function from the Abstract Machine (AM). Taking riscv32 as an example, vme_init() sets up the callback functions for page allocation and release, then calls the map() function to populate the page directory and page tables for the kernel virtual address space (kas). Finally, it sets a CSR (Control and Status Register) called satp (Supervisor Address Translation and Protection) to enable the paging mechanism. With these settings, Nanos-lite then operates on top of the paging system, which facilitates better management and protection of memory resources.
The map() function is a core API within the Virtual Memory Environment (VME), and it plays a crucial role in setting up the virtual memory system. Its main function is to populate the page directory and page tables of the virtual address space as with the correct entries. This ensures that when a virtual page (specified by the parameter va) is accessed under paging mode, the hardware's page table walk will resolve to the exact physical page (specified by the parameter pa) that was defined during the map() call. This underscores the collaborative nature of paging between software and hardware: if map() does not correctly populate the page tables and directory, the hardware will be unable to retrieve the correct physical page during the page table walk.
For x86 and riscv32, vme_init() uses map() to establish mappings in the kernel's virtual address space. These mappings are special because their virtual addresses (va) and physical addresses (pa) are the same, which are referred to as "identical mappings". After the hardware paging mechanism is activated, the physical addresses accessed by the CPU are the same as when the paging mechanism is disabled, allowing Nanos-lite to appear as if it is running directly on physical memory without needing to modify other code. Establishing such a mapping also facilitates memory management for Nanos-lite: even in paging mode, Nanos-lite can treat physical addresses as virtual addresses, and the addresses accessed will correspond exactly to the respective physical addresses.
To ensure that the mappings created by map() are effective, we also need to implement the paging mechanism in NEMU. Specifically, we need to address the following two points:
- How to determine if the CPU is currently in paging mode?
- How should the address translation process of paging be implemented?
But these two points are related to ISA, so NEMU abstracts them into corresponding APIs:
// Check whether memory access for the current system state within the range [vaddr, vaddr + len) and of type 'type' requires address translation.
int isa_mmu_check(vaddr_t vaddr, int len, int type);
// Perform address translation for memory access within the range [vaddr, vaddr + len) and of type 'type'.
paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type);
To use these APIs, you need to modify the functions that handle virtual address access in NEMU. Specifically, you first need to use isa_mmu_check() to determine how the virtual address access should proceed based on the current system state:
- If
isa_mmu_check()returnsMMU_DIRECT, it means that the address can be directly used as a physical address. In this case, simply callpaddr_read()orpaddr_write(). - If
isa_mmu_check()returnsMMU_TRANSLATE, it indicates that the access requires address translation through the MMU. You should first callisa_mmu_translate()to perform the address translation, then use the translated physical address to callpaddr_read()orpaddr_write(). - According to the API definition,
isa_mmu_check()can also returnMMU_FAIL, which means the access has failed and an exception should be thrown, although this situation will not occur in PA.
If you choose x86, you need to add the CR3 and CR0 registers, along with the instructions to operate them. For the CR0 register, we only need to implement the PG bit. If the PG bit of CR0 is set to 1, it indicates that the CPU is in paging mode, and from then on, all virtual address accesses must go through page address translation.
The Sv32 paging mechanism in RISCV32 is very similar to that of x86, with only differences in the names of the registers and the structure of the page table entries: In RISC-V32, both the page directory base address and the paging enable bit are located in the satp register. As for the differences in the structure of the page table entries, these are not detailed here; it is best to RTFM.
The situation with MIPS32 is quite different. MIPS32 simply specifies the division of the virtual address space. In PA, we will only use the following three segments of address space, and MIPS32 also specifies the characteristics of the remaining spaces, which can be consulted in the manual:
[0x80000000, 0xa0000000)belongs to kernel space, no address translation is performed.[0xa0000000, 0xb0000000)belongs to I/O space, no address translation is performed.[0x00000000, 0x80000000)belongs to user space, address translation is required.
Since the kernel space in MIPS32 does not require address translation, there is no need to maintain what is called a kernel mapping. Moreover, in MIPS32, whether address translation is needed is determined by the address space itself, thus there is no "paging mechanism enabled" state, and therefore, MIPS32 does not have a status bit like CR0.PG. As a result, the vme_init() in mips32-nemu is very simple, only requiring the registration of callback functions for page management.
You need to understand the process of page address translation, then implement isa_mmu_check() (defined in nemu/src/isa/$ISA/include/isa-def.h) and isa_mmu_translate() (defined in nemu/src/isa/$ISA/system/mmu.c). You can refer to the NEMU ISA-related API documentation to understand their behavior. Additionally, since we do not plan to implement a protection mechanism, in the implementation of isa_mmu_translate(), you must use assertions to check the present/valid bits of the page directory entry and page table entry. If an invalid entry is found, terminate the execution of NEMU immediately, otherwise debugging will be very difficult. This is usually caused by errors in your implementation, please check the correctness of your implementation.
A final reminder about a special case that occurs with x86 page-level address translation. Since x86 does not strictly require data alignment, data may cross virtual page boundaries. For example, the first byte of a long instruction might be at the end of one virtual page, with the remaining bytes at the beginning of another virtual page. If these two virtual pages are mapped to two non-contiguous physical pages, two page-level address translations are required, to read the necessary bytes from each physical page and then concatenate them to form a complete data return. However, according to the KISS principle, you can initially forego implementing this special case handling, and use assert(0) to terminate NEMU upon detecting data crossing virtual page boundaries, and handle it when such a situation actually arises. In contrast, MIPS32 and RISC-V32, as RISC architectures, strictly align instructions and data to 4 bytes, so such scenarios do not occur, otherwise, the CPU would throw an exception, illustrating yet another tradeoff between software flexibility and hardware complexity in computer systems.
Run Nanos-lite on a paging mechanism
Implement the following:
- Nanos-lite's
pg_alloc(). The parameter forpg_alloc()is the number of bytes to allocate, but we ensure that AM callspg_alloc()via callback function in multiples of page size, thus, it can be implemented by callingnew_page(). Additionally,pg_alloc()needs to zero out the allocated pages. - VME's
map(). You can obtain the base address of the page directory throughas->ptr. If a new page table is needed, you can get a free physical page from Nanos-lite via the callback functionpgalloc_usr(). - Implement the paging mechanism in NEMU.
Since Nanos-lite runs in the kernel's virtual address space and these mappings are identity mappings, the address translation result pa must be the same as va. You can use this condition as an assertion in the NEMU code to help catch implementation bugs.
If your implementation is correct, you will see that the game Legend of Sword and Fairy can also run successfully. If you have questions about the details of the paging mechanism, please RTFM.
For x86 and riscv32, you do not need to implement TLB.
For mips32, at this point, you cannot check if your implementation is correct because in mips32, the process of address translation is only triggered when accessing user space. Therefore, if you have chosen mips32, you will need to complete the following content to test your implementation.
Enable DiffTest to support paging mechanism
To make the DiffTest mechanism work correctly, you need:
- For x86:
- In the
restart()function, we need to initialize the CR0 register to0x60000011, but we do not need to concern ourselves with its meaning. - Implement the functionality of the accessed and dirty bits in the paging mechanism.
- In the
- When handling the
attachcommand, synchronize the paging-related registers with REF. - Update the snapshot functionality.
This is, after all, an optional exercise, and implementation details are not provided. If you encounter difficulties, consider solutions on your own.
However, for mips32, the introduced TLB is also part of the machine state. Therefore, to perfectly perform DiffTest, it is necessary to consider how to synchronize the TLB with REF. This is indeed not an easy task, and you can think about how to solve it, though giving up on performing DiffTest could also be a viable solution.
RISC-V Paging Mechanism
If you carefully RTFM, you will discover that the standard RISC-V paging mechanism can only be enabled in S-mode and U-mode, and memory access in M-mode does not undergo MMU address translation. However, in NEMU, we have simplified this by allowing address translation even in M-mode accesses, thus avoiding the introduction of S-mode related details and allowing everyone to focus on the paging mechanism itself.
Run user processes on a paging mechanism
After successfully implementing the paging mechanism, you may have noticed that the game "Chinese Paladin" also appears to run successfully. However, upon closer inspection, something seems off: In vme_init(), we created a virtual address space for the kernel and never switched from it afterward. This means that "Chinese Paladin" is also running on top of the kernel's virtual address space! This is quite unreasonable since user processes should have their own set of virtual address spaces. Furthermore, previously in Navy-apps, user programs were linked to positions at 0x3000000/0x83000000 because Nanos-lite did not manage free physical memory. Now with the introduction of the paging mechanism, the Memory Manager (MM) is responsible for allocating all physical pages. This means that if MM later allocates the physical pages at 0x3000000/0x83000000, the content of "Chinese Paladin" will be overwritten (you have already encountered this issue while running the exec-test). Therefore, although it seems like "Chinese Paladin" is running successfully, there are hidden dangers lurking within.
The correct approach is to run the user process on the virtual address space allocated by the operating system. To achieve this, we need to make some changes to the project. First, when compiling the Navy application, you need to add the parameter VME=1 to make. This will change the link address of the application to 0x40000000. This is to avoid unexpected errors caused by the overlap between the virtual address space of the user process and the kernel. At this point, the advantage of "virtual addresses as an abstraction of physical addresses" is already evident: in principle, the user process can run at any virtual address, regardless of the physical memory capacity. We set the user process code to start near 0x40000000. This address is already outside the physical memory address space (NEMU provides 128MB of physical memory), but the paging mechanism ensures that the process can run correctly. Thus, neither the linker nor the program needs to worry about which physical address is actually used at runtime. They can simply use virtual addresses, and the mapping between virtual and physical addresses is entirely managed by the operating system's memory manager (MM).
Additionally, we need to make significant changes to the process of creating user processes. We first need to create an address space for the user process before loading it. Since the address space is process-related, we include the AddrSpace structure as part of the PCB. This way, we only need to call protect() at the beginning of context_uload() to create the address space. Currently, this address space contains nothing but the kernel mapping. For details, refer to abstract-machine/am/src/$ISA/nemu/vme.c.
However, at this point, loader() cannot directly load the user process near the memory location 0x40000000, because this address is not in the kernel's virtual address space, and the kernel cannot directly access it. What loader() needs to do is to load the program in pages after determining its size:
- Allocate a free physical page.
- Use
map()to map this physical page into the user process's virtual address space. Since AM native implements permission checks, to ensure the program can run correctly on AM native, you need to setprotto be readable, writable, and executable when callingmap(). - Read one page of content from the file into this physical page.
All of this is to ensure that the user process can run correctly in the future: the user process accesses memory using virtual addresses. Under the mapping maintained by the loader for the user process, virtual addresses are converted to physical addresses. The physical memory accessed through these physical addresses is exactly the data that the user process wants to access.
Another issue to consider is the user stack. Similar to loader(), we need to map the physical page obtained by new_page() into the user process's virtual address space using map(). We place the virtual address of the user stack at the end of the user process's virtual address space. You can get the end position through as.area.end, and then map the physical page of the user stack to the virtual address space [as.area.end - 32KB, as.area.end).
Finally, to make this address space effective, we need to apply it to the MMU. Specifically, we want to switch the address space when the CTE restores the process context. To do this, we need to add the process's address space descriptor pointer as->ptr to the context. The framework code has already implemented this feature (see abstract-machine/am/include/arch/$ISA-nemu.h). In x86, this member is cr3, while in mips32/riscv32 it is pdir. You also need to:
- Modify the implementation of
ucontext()to set the address space descriptor pointer in the created user process context. - Call
__am_get_cur_as()at the beginning of__am_irq_handle()(defined inabstract-machine/am/src/$ISA/nemu/vme.c) to save the current address space descriptor pointer into the context. - Call
__am_switch()before__am_irq_handle()returns (defined inabstract-machine/am/src/$ISA/nemu/vme.c) to switch the address space, applying the address space of the scheduled process to the MMU.
Implement the Real Paging Mechanism for mips32
If you chose mips32, now you need to implement the real paging mechanism; if not, you can ignore this task.
When the CPU tries to perform address translation and a TLB miss occurs, the hardware will set the current virtual page number in entryhi and then throw a TLB refill exception. This exception will be caught by the CTE, which will then call the __am_tlb_refill() function:
- Read the page directory base address of the current process (think about how to obtain it).
- Read the virtual page number from
entryhi. - Perform a page table walk based on the virtual page number.
- Set the physical page numbers corresponding to two consecutive virtual pages into
entrylo0andentrylo1. - Execute the relevant TLB management instructions to update the TLB entries.
After returning from the TLB refill exception, the CPU will re-execute the same instruction, and the address translation should succeed this time. To allow software to perform the page table walk, you need to implement __am_tlb_refill() (defined in abstract-machine/am/src/mips32/nemu/vme.c).
According to the content above, we also need to maintain the relationship between TLB entries and processes, which should be done through ASID. However, we can simplify here by clearing the entire TLB when switching address spaces, similar to x86. For this, you also need to implement __am_tlb_clear() (defined in abstract-machine/am/src/mips32/nemu/vme.c).
Run User Processes on the Paging Mechanism
According to the content of the lecture above, make corresponding changes to the process of creating user processes to allow them to run successfully on the paging mechanism. If you chose mips32 or riscv32, pay attention to the position of the address space descriptor in the context structure. If you are not sure about this position, check your code implementation according to the lecture content from PA3.
To test the correctness of the implementation, we first run the dummy program alone (don't forget to modify the scheduling code), and call halt() in the exit implementation to terminate the system. This is because running other programs successfully requires some additional changes. If your implementation is correct, you will see the dummy program output GOOD TRAP at the end, indicating that it has successfully run on the paging mechanism.
Enable DiffTest to Support Paging Mechanism (2)
If you chose riscv32, to allow the DiffTest mechanism to correctly support the operation of user processes, you also need to:
- Implement
MandUprivilege modes, specifically:- Implement the functionality of the
mstatus.MPPbit in NEMU - When executing the
ecallinstruction, throw different exceptions based on the current privilege level, but handle them uniformly in the CTE - When creating the kernel thread context, additionally set
mstatus.MPPtoMmode - When creating the user process context, additionally set
mstatus.MPPtoUmode
- Implement the functionality of the
- When filling the page table, additionally set the
R,W,X,U,A, andDbits - When creating the user process context, additionally set the
MXRandSUMbits inmstatus
Role of Kernel Mapping
For x86 and riscv32, when creating an address space in protect(), there is a piece of code used to copy the kernel mapping:
// map kernel space
memcpy(updir, kas.ptr, PGSIZE);
Try commenting out this code, recompile, and run the program. You will see an error occurs. Please explain why this error occurs.
To run Chinese Paladin on the paging mechanism, we also need to consider the heap area. Previously, we let the mm_brk() function return 0 directly, indicating that the size modification of the user process's heap area was always successful. This was because before implementing the paging mechanism, memory above 0x3000000/0x83000000 could be freely used by the user process. Now that the user process is running on the paging mechanism, we need to map the newly allocated heap area into the virtual address space in mm_brk(). This ensures that the user process running on the paging mechanism can correctly access the newly allocated heap area.
To identify which space in the heap area is newly allocated, we also need to record the position of the heap area. Since each process's heap usage is independent, we need to maintain the heap position separately for each process. Therefore, we add a member max_brk in the PCB to record the maximum position that the program break has ever reached. Introducing max_brk simplifies the implementation: we can avoid implementing the heap reclamation function and instead only allocate physical pages for the virtual address space portion where the new program break exceeds max_brk.
Run Chinese Paladin on the Paging Mechanism
Based on the content above, implement the mm_brk() function in nanos-lite/src/mm.c. You need to pay attention to whether the parameters of map() need to be page-aligned (this depends on your map() implementation).
Once implemented correctly, Chinese Paladin will be able to run correctly on the paging mechanism.
Consistency Issues - The Nightmare of mips32
We've almost covered the principles of paging, but if you chose mips32, you might encounter various strange issues while running Chinese Paladin, many of which could be due to consistency problems. Here, the contents of the TLB can be considered as copies of the memory page table entries...
Oh, since you have the determination to choose mips32, we won't reveal too much. Try to figure out this issue on your own and think about the corresponding solutions. Only after solving the consistency issue can you truly understand the paging mechanism of mips32.
Support Sound
If you have previously implemented sound card-related functions, you might encounter errors at this point. Try to RTFSC (Read The Fabulous Source Code) and solve this error.
Native VME Implementation
Try to read the VME implementation of native. How does native implement VME? Why can it be done this way?
Can User Process Contexts Be Created in the User Stack?
The behavior of ucontext() is to create the user process context in the kernel stack kstack. Can we modify the behavior of ucontext() to create the user process context in the user stack? Why or why not?
Multi-programming with Virtual Memory Management
After a long detour to introduce virtual memory management, we finally come back: we can now support the concurrent execution of multiple user processes. However, let's first allow user processes running on the paging mechanism to concurrently execute with kernel threads to further test the paging mechanism.
To do this, we need to consider how the scheduling of kernel threads will affect the paging mechanism. The biggest difference between kernel threads and user processes is that kernel threads do not have a user-mode address space: the code, data, and stack of kernel threads are all located in the kernel's address space. So, after enabling the paging mechanism, if __am_irq_handle() needs to return to a kernel thread's context, do we need to consider switching to the kernel thread's virtual address space using __am_switch()?
The answer is no. This is because all virtual address spaces created by AM will include the kernel mapping. Regardless of which virtual address space was active before the switch, the kernel thread can run correctly in that virtual address space. Therefore, we only need to set the address space descriptor pointer of the context to NULL in kcontext() as a special marker. Later, when __am_irq_handle() calls __am_switch(), if it finds that the address space descriptor pointer is NULL, it will not perform the virtual address space switch.
Multi-programming with Virtual Memory Management
Enable Nanos-lite to load and run Chinese Paladin and the kernel thread hello. The running result should be the same as in the previous stage, but this time the entire system will be running on the paging mechanism.
However, we will find that compared to before, the performance of Chinese Paladin running on the paging mechanism has significantly decreased. Although NEMU serially simulates the MMU function and cannot fully represent the real operation of a hardware MMU, this also indicates that the virtual memory mechanism indeed incurs additional runtime overhead. For this reason, engineers in the 1960s were generally cautious about the virtual memory mechanism and did not easily implement it in their systems. However, the advantage of "allowing multiple programs to run concurrently without modifying the programs" became increasingly evident, leading to the virtual memory mechanism becoming a standard feature of modern computer systems.
Concurrent Execution of Multiple User Processes
Let Nanos-lite load both Chinese Paladin and the hello user process; or load NTerm and the hello kernel thread, and then start Chinese Paladin from NTerm. You are likely to observe errors during execution. Try to analyze the cause of these errors and summarize the conditions we need to meet to support this functionality.
This can be considered the most challenging question in the first round. Although we will provide an analysis at the end of PA4, those who enjoy challenges can try to think independently here: if you can solve this problem on your own, it shows that your understanding of computer systems is quite remarkable.
Hint: A program is a state machine.
This stage of the content is considered the most difficult in the entire PA, and even the difficulty of optional tasks is not on the same level as before. This also demonstrates the challenge of building systems: as a system becomes more complete, the interactions between modules become increasingly complex. The code may seem simplified, but every word is crucial, and a small change can affect the entire system. However, this is an inevitable rule of rising project complexity. When the codebase reaches a certain size, even developing an application can face similar difficulties. So how should we understand and manage increasingly complex project code?
The answer is abstraction. That’s why you see various APIs in the PA; we do not define them arbitrarily. They indeed encapsulate the essence of module behavior, helping us understand the behavior of the entire system from a macro perspective more easily. Even when debugging, these APIs greatly assist us in organizing the behavior of the code. As you understand, implement, and debug these APIs, your understanding of the entire system will become more profound. If you indeed complete this independently, you will not be intimidated by more complex projects in the future.
Tips
Stage 2 of PA4 ends here.