Programs, Runtime, and the Abstract Machine (AM)
Runtime
In order to making NEMU support the execution of most programs, you have already implemented a lot of instructions. However we need to do more to run additional programs other than implement all instruction. We mentioned before that "not every program can be run in NEMU", now let's explain the reason behind it.
As an intuition, it is unrealistic to let a TRM that only "computes" to support the execution of a fully functional operating system. Just like computers that also have different level of capability. The more "powerful" a computer is, the more complex programs it can run. In other words, running a program need the compute to met certain requirements. When you run the Hello World program, you type a command (or click the mouse) and the program runs successfully, but behind the scene are the countless hours of operating system developers and system library developers spends. In fact, the execution of the application requires the support of the runtime environment, including loading, destroying the program, and providing various dynamic link libraries when the program is running (the library functions you often use are provided by the runtime environment). For helping client programs to run in NEMU, it is now your turn to provide corresponding runtime environment support.
According to the KISS principal, let's first consider what the simplest runtime environment looks like. In other words, what do we need to provide to run the simplest program? In fact, the answer is already in PA1: Just put the program in the correct memory location, and then let the PC point to the first instruction, and the computer will automatically execute the program and never stop.
However, although the computer can keep executing instructions for ever. In general, programs need to end, so the runtime environment needs to provide a method for the program to end the execution. You may already think about the manually added nemu_trap instruction we mentioned in PA1 which is to let the program end the execution.
Therefore, with memory, a way to terminate the program, and the implementation of correct instructions, it can support the execution of the simplest program. And this can also be treated as the simplest runtime environment.
Encapsulate the runtime environment into library functions
The runtime environment we just discussed is located directly on the computer hardware, so the implementation of the runtime environment is also architecture related. We use the "ISA-platform" pair to represent an architecture, such as mips32-nemu. Taking program termination as an example, NEMU uses a special nemu_trap instruction, and the format of the nemu_trap instruction in different ISAs is different: consider if we use verilog to design a riscv32 CPU, this riscv32-mycpu architecture may terminate the program through a mycpu_trap instruction, which may be different from the nemu_trap instruction. Termination of program is a common requirement. To allow n programs to run on m architectures, do we have to maintain n*m pieces of code? Is there a better way?
For the same program, if we can convert m architect specific code path to a single entry point then we only need to maintain one entry. The way to achieve this goal is by abstraction which you should have learned in programming class! We only need to define an API to terminate the program, such as void halt(), which abstracts the architecture specific termination code. The program can terminate the execution as long as it calls halt(), without caring about which architecture it is running on. After abstracting the termination of a program to a single API entry, the previous m architecture specific versions of the same program now all terminate their execution through halt(). And only left us one version to maintain. Then, different architectures implement their own halt() respectively, which can support the execution of n different programs! In this way, we can decouple the program and the architecture: we only need to maintain n+m pieces of code (n programs and m architecture-related halt()), instead of the previous n*m versions.
This example also shows how runtime environment usually gets implemented: Library. By using libraries, the common elements required to run the program are abstracted into APIs. Each architecture now only need to implement those APIs to provide the runtime. This improves the efficiency of developing: when needed, we only need to call these APIs to use the corresponding functions provided by the runtime environment.
Now what?
Think about it. What are the other benefits of this abstraction? You'll soon realize the benefits..
AM - bare-metal runtime environment
On the one hand, as mentioned above, execution of applications requires the support from the runtime environment; On the other hand, programs that only perform pure computational tasks can be run on TRM. However, complex applications have more requirements on the runtime environment: for example, the Super Mario game you played before needs to interact with the user through the input/output interface provided by the runtime. To run a modern operating system, more advanced features must be added on top of this.
If we collects all the requirements and abstract them into a unified API to provide to the program, then we will get a library that can support various programs running on various architectures! Specifically, each architecture implements this set of APIs according to their characteristics; applications only need to call the same set of APIs, and do not need to worried about which architecture they will be running on in the future. Since this set of unified abstract APIs represents the requirement for executing a program, we call this set of APIs an abstract computer.
This is how the AM (Abstract machine) project was born. As a library that provides a runtime environment for programs, AM divides the library into the following modules according to the needs of the program:
AM = TRM + IOE + CTE + VME + MPE
- TRM (Turing Machine) - Turing machine, the simplest runtime environment, provides basic computing functionality for programs.
- IOE (I/O Extension) - Input and output extension, providing the program with the ability to input and output.
- CTE (Context Extension) - Context extension, providing context management capabilities for programs.
- VME (Virtual Memory Extension) - Virtual memory extension, providing programs with the ability to manage virtual memory.
- MPE (Multi-Processor Extension) - Multi-processor extension, providing programs with the ability to communicate across multiple processors (MPE is beyond the scope of the ICS course and will not be covered in PA)
AM showed us the relationship between programs and computers: using computer hardware's feature implement AM to provide the runtime environment of guest programs. Thanks to the AM project, the boundaries between NEMU and guest programs have becomes more clear. It also improves the PA process:
(In NEMU) Implement hardware functionality -> (In AM) Provide runtime environment -> (In application layer) Execute programs
(In NEMU) Implement more powerful hardware functionality -> (In AM) Provide a richer runtime environment -> (In application layer) Execute more complex programs
This process echoes the ground-breaking story in PA1: the pioneer hopes to create a world of computers and give it the mission of executing programs. Building the bridge between hardware(NEMU) and software(AM) to support the execution of the program is a good choice for the ultimate goal of "How computer executes a program".
The birth of AM and the story of Project-N
Before the birth of AM, the main components of Project-N already existed:
NEMU - NJU EMUlator (basic computer system lab) Nanos - Nanjing U OS (operating system lab) NOOP - NJU Out-of-Order Processor (computer architecture lab) NCC - NJU C Compiler (compiler principle lab)
But we have never thought about how to integrate these components into a complete teaching ecosystem.
In the computer system course in spring 2017, jyy first proposed the idea of AM to decouple programs and architecture. After decoupling, AM became a key to Project-N: As long as AM is implemented, we can run various AM programs on NEMU and NOOP; as long as Nanos is implemented on AM, we can run Nanos on NEMU and NOOP; as long as NCC compiles the program to AM, we can run the NCC-compiled program on NOOP.
After several months of trying, we soon believed that this was the right path. So we decided to make a major revision of PA in the fall of 2017, and reusing ideas from AM to design NEMU, expecting everyone can better understand "How computer executes a program" Therefore, in 2017 autumn semester NEMU has been officially included as a sub-project in the Project-N teaching ecosystem.
We have formed a team to participate in the computer system design competition "Loongson Cup" for two consecutive years. We demonstrated our unique Project-N ecosystem in the competition and won second place. The competition will also provide valuable feed back to PA to close the loop. These are actually not far away from you. The methods and principles we emphasis in PA are all golden experiences for winning in the competition.
If you are interested in AM and Project-N, please contact jyy or yzh.
Travel through the time
With AM, we can connect the labs between courses and do some interesting things that we couldn't do before: for example, in the operating system class this spring, your seniors wrote their own small games on AM. In the later part of this year’s PA, you will have the opportunity to seamlessly port the games written by your seniors to NEMU as part of the final system demonstration, which is an exciting thing to think about.
Why AM? (It is recommended to think about it in the second cycle)
The operating system also has its own runtime environment. What is the difference between the runtime environment provided by AM and the operating system? Why those differences present?
RTFSC(3)
You have obtained the AM sub-project abstract-machine at the end of PA0. Let's briefly introduce the code of the AM project. The source files in the abstract-machine/ directory in the code are organized as follows (the files in some directories are not listed):
abstract-machine
├── am # AM related
│ ├── include
│ │ ├── amdev.h
│ │ ├── am.h
│ │ └── arch # arch specific headers
│ ├── Makefile
│ └── src
│ ├── mips
│ │ ├── mips32.h
│ │ └── nemu # mips32-nemu related implementation
│ ├── native
│ ├── platform
│ │ └── nemu # AM implementation targeting NEMU
│ │ ├── include
│ │ │ └── nemu.h
│ │ ├── ioe # IOE
│ │ │ ├── audio.c
│ │ │ ├── disk.c
│ │ │ ├── gpu.c
│ │ │ ├── input.c
│ │ │ ├── ioe.c
│ │ │ └── timer.c
│ │ ├── mpe.c # MPE, currently empty
│ │ └── trm.c # TRM
│ ├── riscv
│ │ ├── nemu # riscv32(64) implementation
│ │ │ ├── cte.c # CTE
│ │ │ ├── start.S # program entry point
│ │ │ ├── trap.S
│ │ │ └── vme.c # VME
│ │ └── riscv.h
│ └── x86
│ ├── nemu # x86-nemu implementation
│ └── x86.h
├── klib # common function library
├── Makefile # public makefile rules
└── scripts # Makefile for build/execute/mirroring
├── isa
│ ├── mips32.mk
│ ├── riscv32.mk
│ ├── riscv64.mk
│ └── x86.mk
├── linker.ld # linker script
├── mips32-nemu.mk
├── native.mk
├── platform
│ └── nemu.mk
├── riscv32-nemu.mk
├── riscv64-nemu.mk
└── x86-nemu.mk
The entire AM project is divided into two parts:
abstract-machine/am/- AM API implementations targeting different architectures. Currently we only need to focus on NEMU-related content. In addition, abstract-machine/am/include/am.h lists all APIs in AM, we will introduce them one by one later.abstract-machine/klib/- Some architecture-independent library functions to facilitate application development
By reading the code in abstract-machine/am/src/platform/nemu/trm.c, you will find that only a few APIs need to be implemented to support the program running on TRM:
Area heapstruct is used to indicate the start and end of the heap areavoid putch(char ch)is used to print a charactervoid halt(int code)is used to end the running of the programvoid _trm_init()is used for TRM-related initialization work
The heap area is a memory block that can be freely used by the program, providing the program with the ability of dynamically allocating memory. The API of TRM only provides the start and end address of the heap area, the program is required to maintain all the allocations. Of course, programs can also choose not use the heap area, such as dummy. Using putch() as an API for TRM is a very interesting consideration. We will discuss it later. For now, we are not planning to run programs that need to call putch().
Finally, let’s take a look at halt(). The nemu_trap() macro (defined in abstract-machine/am/src/platform/nemu/include/nemu.h) is called in halt(). The macro expands to an inline asm statement. Inline assembly statements allow us to embed assembly statements in C code. Taking riscv32 as an example, after macro expansion, we will get:
asm volatile("mv a0, %0; ebreak" : :"r"(code));
Obviously, the definition of this macro is ISA related. If you look at nemu/src/isa/$ISA/inst.c, you will find that this instruction is the special nemu_trap! The nemu_trap() macro will also put an end code that marks the end of program execution into to a general purpose register. Now the asm instruction and nemu_trap in nemu/src/isa/$ISA/inst.c are linked together: the value in the general register will be passed to set_nemu_state() as a parameter, and the end code in halt() will be set to the NEMU monitor. The monitor will report the reason for the end of the program based on the end code. In addition, volatile is a keyword in C language. If you want to know more about volatile, please check the relevant information.
The am-kernels subproject is a collection of test sets and simple programs that can be run on AM:
am-kernels
├── benchmarks # Benchmarking program that can be used to measure performance
│ ├── coremark
│ ├── dhrystone
│ └── microbench
├── kernels # Sample application
│ ├── hello
│ ├── litenes # Simple NES Emulator
│ ├── nemu # NEMU
│ ├── slider # Simple Image Browser
│ ├── thread-os # kernel-threaded operating system
│ └── typing-game # Typing games
└── tests # Test sets
├── am-tests # Test set for AM API implementation
└── cpu-tests # Test set for CPU instruction implementations
Before letting NEMU run the client program, we need to compile the code of the client program into an executable file. It should be noted that we cannot use the default options of gcc to compile directly, because the default options will compile the code into an executable file running under GNU/Linux according to the GNU/Linux runtime environment. However, NEMU at this time cannot provide a GNU/Linux runtime environment for client programs. The above executable file cannot be run correctly in NEMU, so we cannot use the default options of gcc to compile user programs.
The way to solve this problem is to cross-compile. We need to compile an executable file under GNU/Linux based of AM runtime environment that can run under $ISA-nemu environment. In order to prevent the linker ld from using the default linking method, we also need to provide a linker script describing the runtime environment of $ISA-nemu. The framework code of AM has prepared the corresponding configuration. The above compilation and linking options are mainly located in the abstract-machine/Makefile and the relevant .mk files in the abstract-machine/scripts/ directory. The steps of compiling and linking an executable that can run under the NEMU runtime environment is listed below:
gcccompiles the AM source codes of$ISA-nemuinto object files, and then usesarto pack these object files as a static library archieveabstract-machine/am/build/am-$ISA-nemu.agcccompiles guest program source code (such asam-kernels/tests/cpu-tests/tests/dummy.c) into object files- Using
gccandarto compile and archive all the dependency library (such asabstract-machine/klib/) - Based on the rules defined in the Makefile
abstract-machine/scripts/$ISA-nemu.mk, letldlink all the object files and static library into an executable using the linker scriptabstract-machine/scripts/linker.ld
Based on the linker script provided, the sections of the executable program after relocation starts from 0x100000 or 0x80000000 (depending on the values of _pmem_start and _entry_offset). The first is the .text section, which starts with the customized entry section defined in abstract-machine/am/src/$ISA/nemu/start.S, and then follows the .text section of all other object files. In this way, the code of start.S is always placed at the beginning of the executable program, this ensures the correct start from start.S for all guest programs. The linker script also defines the link order of other sections (including .rodata, .data, .bss), it also defines some symbols for location information, including the end of each section, the top of the stack, and the beginning and end of the heap area.
Let’s briefly sort out the behavior of the compiled executable file:
- The first instruction starts from
abstract-machine/am/src/$ISA/nemu/start.S. After setting the top of the stack, jump to the_trm_init()function ofabstract-machine/am/src/platform/nemu/trm.cto start the execution. - The
main()function is called in_trm_init()to execute the main function of the program. Themain()function also takes a parameter, which we are not using currently and will be introduced later. - After returning from the
main()function, callhalt()to end the execution.
With TRM - a simple runtime environment, we can easily run various "simple" programs on it. Of course, we can also run "not simple" programs: we can implement arbitrarily complex algorithms, and even various theoretically computable problems can be solved on TRM.
Read Makefile
The Makefiles of the abstract-machine project are very cleverly designed. You need to RTFSC them as some kind of code to understand how they work. With AM makefile as an example, you will know how to write decent Makefiles. At the same time, if the Makefile behaves unexpectedly one day, you can try to debug the Makefile yourself. Of course, this requires RTFM.RTFM.
Run NEMU via batch mode
We know that most students are likely to think this way: Even if I don’t read the Makefile, the teacher and teaching assistant don’t know about it, It’s doesn’t matter if I don’t read it.
So here we add a required question: when we started NEMU before, we had to manually type c every time to execute the guest program. However this is purely for using sdb in NEMU. NEMU implements a batch mode, which can execute the guest program directly after starting NEMU. Please read the source code of NEMU and modify the Makefile appropriately so that NEMU in batch mode can be started by default through AM's Makefile.
You can still skip this mandatory question for now, but soon you'll find it less convenient.
Implement Library for common functions
We have already run many simple programs on TRM, but if we want to write some slightly more complex programs on TRM, we will find it a bit inconvenient. Currently, the simplest runtime environment TRM only provides the heap area and halt(), but the library functions we often use like memcpy() are not provided. Since they are not provided, let us implement them.
Since they can be called library functions, it means that many programs can use them, so we can organize them into a library like AM. However, unlike AM, the specific implementation of these library functions can be architecture-independent: unlike halt(), memcpy() can be implemented in the same way on NEMU, or on the CPU you will implement using verilog in the future, or even other architectures. Therefore, if these commonly used functions are implemented in AM Library functions will introduce unnecessary duplication of code.
A good approach is to divide the runtime environment into two parts: one is the architecture-related runtime environment, which is the AM we introduced before; the other is the architecture-independent runtime environment, such as commonly used functions like memcpy(). abstract-machine/klib/ directory contains those architecture-independent library functions. klib means kernel library and is used to provide some basic functions compatible with libc. The framework code lists library functions that may be used in the future in abstract-machine/klib/src/string.c and abstract-machine/klib/src/stdio.c, but does not provide corresponding implementations.
Implement string processing functions
Implement the string processing functions listed in abstract-machine/klib/src/string.c as needed so that the test case string in cpu-tests can run successfully. Please be sure to RTFM about the specific behavior of these library functions.
Rules and undefined behavior in computer system
The ubiquitous manual reflects a basic principle of computer system work: follow rules.
What will happen if rules are violated? The most common thing is that the program cannot yield the correct result. For example, if the strcpy() you implemented did not copy the \0 at the end, which violates the convention of the manual. According to the convention of the C language standard, calling this wrong strcpy() is likely to get a very long target string. Of course, it is also possible that there is just happened to be a lot of '\0' near the end of target string, and you will be lucky enough to get the correct result. In short, program behaivor after violating rules is undefined and what exactly will happen depends on implementation.
Since it’s not defined, let’s don't try to figure out what exactly may happen, so there is the concept of Undefined Behavior (UB, Undefined Behavior): if you follow rules, you can ensure that the program has the characteristics of rules; if it violates rules, then there is no guarantee what will happen
This is how computer systems work: The interface between abstraction layers of a computer system is a convention. For example, instructions are the interface between software and hardware, so there is an ISA manual to standardize the behavior of each instruction.
- On the one hand, the compiler needs to generate code that can be executed correctly according to the rules in the ISA manual. If the compiler does not generate code according to the manual rules, then the behavior of the compiled program is undefined.
- On the other hand, hardware developers also need to design a processor that can correctly execute instructions according to the rules in the ISA manual. If the processor does not execute instructions according to the rules in the manual, the behavior of the processor running the program is undefined.
Another benefit of introducing undefined behavior is that it brings a certain degree of freedom to implementations. For example, the C language standard states that when the divisor of integer division is 0, the result is undefined. When the x86 division instruction detects that the divisor is 0, it will throw an exception signal to the CPU. The MIPS division instructions are simpler and more brute force: First, it is stated in the MIPS instruction set manual that when the divider is 0, the result is undefined, then when implementing the divider circuit on hardware, the division by 0 operation can be ignored. However, given a divider circuit, even if the divisor is 0, the output of the circuit will always have a value. But what value would that be? We don't really know nor care. Anyway, the C language standard states that the behavior of division by 0 itself is undefined. So whatever value been returned will be acceptable.
Undefined behavior is all around you. For example, when wild pointers are dereferenced, what will happen is completely unpredictable. And memcpy(), which you often use, how will it behave if the source range and destination range overlap? If you have never thought about this problem, you should go to man and think about why this is the case. Another trick that some people like and some people worry about is compilation optimization based on undefined behavior: since the behavior of the source code is undefined, it certainly does not violate the rules if the compiler performs various weird optimizations based on this. This article lists some eye-opening examples of fancy compilation optimization. After reading this, you will refresh your understanding of program behavior.
So, this is why we emphasize RTFM. RTFM is the process of understanding interface behavior and rules: What is the meaning of each input? What is the exact behavior of the object? What is the output? What constraints must be obeyed? What errors will be reported under which circumstances? Which behaviors are UB? We can use the feature correctly only if we fully understand the behavior and obey all the rules. From system design principles to as small as the behavior of a memcpy(), they all contain certain rules. Understanding these rules is an important way to understand computer systems.
UB, compilation optimization and datalab
The lab1 (datalab) once had massive issues because it used the new version of gcc of debian10. Later we learned that it was because the reference code of datalab contained a UB with int integer overflow, and Debian 10's gcc used this UB for compilation optimization, causing the reference code to generate wrong reference answers.
The C language standard states that the behavior of signed int overflow is undefined, but most programmers do not know this rule. Even popular C language textbooks on the market believe that the result of int integer overflow is wrap around. Datalab is an experiment designed by CMU, but the original author will also write code containing UB, which shows that the original author's understanding of UB is not in place. In the old version of the compiler, these UBs were not triggered. But UB is UB after all, which only shows that the author did not fully understand the C language standard when writing the code.
This paper sorts out different kinds of integer overflow and finds many examples of integer overflow in practical applications for analysis. It is recommended that everyone read it. The paper mentions that SafeInt, a widely used library (including Office and Windows), is designed to avoid integer overflows. However, this library itself also contains UB caused by integer overflows. It can be said that SafeInt is not safe.
What these examples give us is that: we not only need to write code that passes tests, but also write well-defined code that conforms to language specifications. To take a step back, everyone makes mistakes, but we must at least know what is right when we make a mistake.
In order to run the test case hello-str, you also need to implement the library function sprintf(). Compared with other library functions, sprintf() is special because its number of parameters is variable. In order to obtain a variable number of parameters, you can use the macros provided in the C library stdarg.h. For specific usage, please refer to man stdarg.
Implement sprintf
Implement sprintf() in abstract-machine/klib/src/stdio.c. For exact behavior, please refer to man 3 printf. At present, you only need to implement %s and %d to pass the hello-str test. Other features (including bit width, precision, etc.) can be implemented by yourself when needed in the future.
How is stdarg implemented?
stdarg.h contains some macros for obtaining function parameters. They can be treat as the abstraction layer of the parameter passing convention. The ABI specifications of different ISAs will define different methods of passing function parameters. If you were asked to implement these macros, how would you implement them?
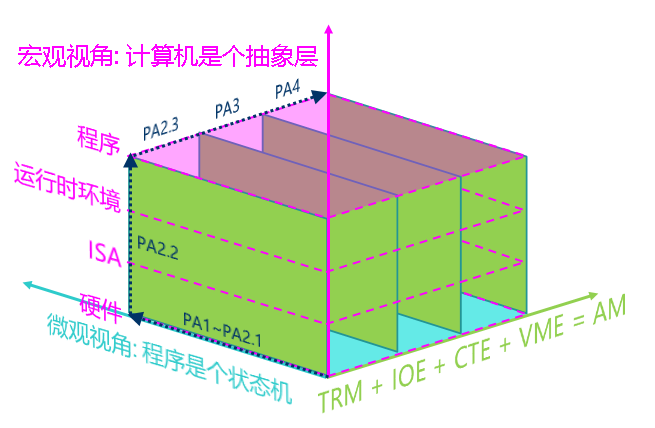
Know computers once again: Computer is an abstraction layer
We introduced the micro perspective of "program running on a computer" in PA1: the program is a state machine. The state machine perspective can accurately describe every detail of the program running from the instruction level, but this loses the semantics of the program. For some simple programs, you can even draw the state machine, but for some complex programs, the state machine perspective cannot help us. To better understand complex programs, we need to approach it from a new perspective.
Let's first discuss the programs can run on TRM, classify the requirements of these programs, and see how our computer system supports these requirements.
| TRM | compute | memory allocation | terminate | |
|---|---|---|---|---|
| Runtime | - | malloc()/free() | - | printf() |
| AM API | - | heap | halt() | putch() |
| ISA Interface | Instructions | Physical memory address space | nemu_trapinstruction | I/O |
| Hardware module | Processors | Physical memory | Monitor | serial port |
| Circuit implementation | cpu_exec() | pmem[] | nemu_state | serial_io_handler() |
- Compute. This is the most basic requirement of the program, so much so that it does not even belong to the scope of the runtime environment and AM. All calculation-related codes (sequential statements, branches, loops, function calls, etc.) will be compiled by the compiler into functionally equivalent instruction sequences, and finally executed on the CPU. In NEMU, we implement the "CPU execution instruction" function through the
cpu_exec()function. - Memory allocation. Some programs need to dynamically allocate memory at runtime. Similar to libc,
klibprovidesmalloc()andfree()via the memory manager (you will implement them in the future), they will use the APIheapprovided in TRM to obtain the start and end of the heap area. The heap range is determined by the physical memory address space corresponding to the specificISA-platformpair. This address space corresponds to the size of the physical memory. In NEMU, it is the size of the large arraypmem[]. - Terminate. Generally, when a program ends, TRM provides a
halt()API to implement this function. Since this requirement is too simple, there is no need for the runtime environment to provide a more complex interface. The specific implementation ofhalt()is related to ISA. We use the artificially addednemu_trapinstruction to achieve this. Executing thenemu_trapinstruction will cause NEMU to jump out of the loop of CPU execution instructions and return to the Monitor. This is achieved by setting a state variablenemu_statein the Monitor. - Print information. Output is another basic requirement of the program. The program can call
printf()inklibto output information to the user, and it will output characters through TRM's APIputch(). DifferentISA-platformshave different character output methods. In$ISA-nemu,putch()writes characters to the serial port through I/O related instructions, then characters are printed to the terminal throughserial_io_handler()in NEMU. More details about input and output will be introduced in the final part of PA2.
A macro perspective of "programs running on computers": the computer is an abstraction laye
In previous PAs, we have been emphasizing the micro perspective that "the program is a state machine" from the base level. Now we finally can look at the higher level and understand how the computer provide multiple layer of abstraction to support program execution.
Each level of abstraction has a reason for existing:
- A hardware module under the same concept can be implemented differently. For example, the processor can be implemented through a simple interpretation method in NEMU, or through a high-performance binary translation method like QEMU, or even through a hardware description language such as Verilog to implement a real processor.
- ISA is an interface provided by hardware to software for minipulate the hardware.
- AM's API abstracts the interfaces of different ISAs (such as x86/mips32/riscv32), hiding ISA-related details for more abstracted programs above this layer.
- The runtime environment wraps AM's API and provide convenitent feature for programs.
These abstractions are all to facilitate us in writing and running various programs in various computer systems. The Xian Jian Qi Xia Zhuan that you are going to run in PA3 is also decomposed into the most basic hardware operations through layers of abstraction, and finally runs in the form of a state machine.
What exactly is PA doing?
So far, we have introduced the two most important perspectives of "program running on the computer" in PA:
- Micro perspective: The program is a state machine
- Macro perspective: Computer is an abstraction layer
The remaining content of PA is to draw inspiration from AM, add various new features to computer hardware in the order of computer development history, strengthen the functions of the runtime environment, and finally run more complex programs. PA will use the process of adding new features as a case study, helping everyone to continuously understand "how the program runs on the computer" from these two perspectives. Specifically, at the end of PA2, we will add IOE to implement a von-Neumann computer system; in PA3, we will add CTE to support the operation of the batch system; in the final PA4, we will add VME to run a simple and cool time-sharing multitasking system.
Here we give a global concept diagram of PA (the "runtime environment" in the diagram includes AM, klib, and even OS and libc). The three-dimensional coordinate axis of this figure summarizes the three most important conclusions in PA, and shows you the entire process of building a computer system in PA. You can also think more about it when doing the lab: Which abstraction layer is the code I am writing now located? What is the specific behavior of the code?