B2 SoC计算机系统
总线讲义更新
我们在2023年11月29日在总线部分的讲义中追加了UART和CLINT的练习, 完成它们有利于接下来SoC的接入.
实现总线之后, 我们就可以将NPC接入到"一生一芯"的SoC环境中, 为流片做好准备! SoC是System On Chip的缩写, 这意味着SoC不仅仅只包含一个处理器, 还有诸多的外围设备, 以及连接处理器和外围设备之间的总线. 在这里, 我们把存储器也看成一种广义的设备, 毕竟对于SoC来说, 存储器和其他狭义的设备没有区别, 都是一段可以访问的地址空间.
ysyxSoC
我们提供一个可以在verilator上运行的SoC环境, 称为ysyxSoC. 我们提前让大家接入ysyxSoC, 一方面是为了让大家学习其中的细节, 另一方面也是尽早在SoC环境中测试你的NPC, 从而帮助你缩短从完成流片考核到提交代码之间的时间. 当然, 在接入ysyxSoC后你还需要完成一些优化工作, 才能达成B阶段的流片指标.
ysyxSoC介绍
我们先给出ysyxSoC包含的外围设备和相应的地址空间.
| 设备 | 地址空间 |
|---|---|
| CLINT | 0x0200_0000~0x0200_ffff |
| SRAM | 0x0f00_0000~0x0fff_ffff |
| UART16550 | 0x1000_0000~0x1000_0fff |
| SPI master | 0x1000_1000~0x1000_1fff |
| GPIO | 0x1000_2000~0x1000_200f |
| PS2 | 0x1001_1000~0x1001_1007 |
| MROM | 0x2000_0000~0x2000_0fff |
| VGA | 0x2100_0000~0x211f_ffff |
| Flash | 0x3000_0000~0x3fff_ffff |
| ChipLink MMIO | 0x4000_0000~0x7fff_ffff |
| PSRAM | 0x8000_0000~0x9fff_ffff |
| SDRAM | 0xa000_0000~0xbfff_ffff |
| ChipLink MEM | 0xc000_0000~0xffff_ffff |
| Reserved | 其他 |
图中除了AXI以外, 还有APB, wishbone和SPI这些总线. 不过这些总线都比AXI简单, 甚至比AXI4-Lite还简单. 你已经了解AXI4-Lite了, 因此学习这些总线协议也并不难, 需要时可查阅相关手册.
一些设备和地址空间在将来可能会产生变化
为了获得更好的展示效果, “一生一芯”项目组正在重新设计SoC, 一些设备和地址空间可能会在将来发生变化, 最终的设备地址空间分配情况以流片版本为准. 不过这并不影响目前的学习, 你可以安全地忽略这一情况.
获取ysyxSoC的代码
你需要克隆ysyxSoC项目:
cd ysyx-workbench
git clone git@github.com:OSCPU/ysyxSoC.git
接下来你将会使用ysyxSoC提供的设备进行仿真, 来验证NPC可以正确访问SoC中的设备. 我们将在下文介绍具体如何接入.
需要注意的是, ysyxSoC与最终流片使用的SoC仍有一定差异. 因此, 通过ysyxSoC的测试并不代表最终也能通过流片SoC仿真环境的测试. 但即使这样, 也可以借助ysyxSoC项目提前暴露一部分问题, 若将来接入流片SoC时仍有问题, 则可重点关注两者差异带来的影响.
对大家来说, ysyxSoC项目有两部分值得大家关注. 第一部分是ysyxSoC的总线部分, 我们主要借助开源社区rocket-chip项目的diplomacy框架来实现它, 相关代码在ysyxSoC/src/目录下. 借助diplomacy, 我们可以很容易地将一个具备总线接口的设备接入ysyxSoC. 例如, 我们只需要改动以下两行Chisel代码, 即可实例化一个AXI接口的MROM设备, 同时指定其地址空间为0x2000_0000~0x2000_0fff, 并将其连接到AXI Xbar的下游. 如果采用传统的Verilog方式来接入, 仅仅是端口声明就要添加将近100行代码, 这还没计算对AXI Xbar的修改.
diff --git a/src/SoC.scala b/src/SoC.scala
index dd84776c..758fb8d1 100644
--- a/src/SoC.scala
+++ b/src/SoC.scala
@@ -39,9 +39,10 @@ class ysyxSoCASIC(implicit p: Parameters) extends LazyModule {
AddressSet.misaligned(0x10001000, 0x1000) ++ // SPI controller
AddressSet.misaligned(0x30000000, 0x10000000) // XIP flash
))
+ val lmrom = LazyModule(new AXI4MROM(AddressSet.misaligned(0x20000000, 0x1000)))
List(lspi.node, luart.node).map(_ := apbxbar)
- List(chiplinkNode, apbxbar := AXI4ToAPB()).map(_ := xbar)
+ List(chiplinkNode, apbxbar := AXI4ToAPB(), lmrom.node).map(_ := xbar)
xbar := cpu.masterNode
override lazy val module = new Impl
第二部分是ysyxSoC的设备部分, 我们收集了一些设备控制器的开源项目, 相关代码在ysyxSoC/perip/目录下. 部分设备通过直接实例化rocket-chip项目中的IP来实现, 这部分设备并不在ysyxSoC/perip/目录下, 具体可以参考ysyxSoC/src/中的相关代码.
接入ysyxSoC
由于SoC中包含多个设备, 这些设备的属性可能有所不同, 这将会带来一些新问题. 例如, ysyxSoC/perip/uart16550/rtl/uart_defines.v中有如下代码:
// Register addresses
`define UART_REG_RB `UART_ADDR_WIDTH'd0 // receiver buffer
`define UART_REG_IE `UART_ADDR_WIDTH'd1 // Interrupt enable
`define UART_REG_II `UART_ADDR_WIDTH'd2 // Interrupt identification
`define UART_REG_LC `UART_ADDR_WIDTH'd3 // Line Control
上述代码定义了UART中一些设备寄存器的地址, 由于UART位于0x1000_0000, 因此上述4个寄存器的地址分别是0x1000_0000, 0x1000_0001, 0x1000_0002, 0x1000_0003. 假设UART通过AXI4-Lite总线连接Xbar, 考虑通过AXI4-Lite读取receiver buffer中的内容. 显然, araddr信号应为0x1000_0000, 但如果要读取4字节, 是否会同时读出后面3个设备寄存器的内容呢?
我们之前没有考虑"读多长"的问题, 是因为对内存进行读操作时, 并不会改变内存中存储数据的状态, 因此无论CPU期望读出多少字节, 总线都可以一次读出4字节或8字节, 让CPU从中选出目标数据. 这甚至有助于一些带有缓存的CPU提高性能: 从内存中读取一次数据一般需要较长时间, 如果能充分利用总线的带宽, 一次多读出一些数据, 就有可能减少将来真正访问内存的次数.
不过对于设备的访问, 上述前提不再成立: 访问设备寄存器可能会改变设备的状态! 这意味着, 对于设备来说, 读出1字节和读出4字节, 最终导致的行为可能不同. 如果我们没有按照设备寄存器的约定来访问它们, 可能会导致设备进入不可预测的状态. 因此在通过总线访问设备时, 我们需要仔细地处理这个问题.
但是, AXI4-Lite总线并不能解决上述问题, 其AR通道中没有足够的信号用于编码读取长度信息, 设备只能认为实际访问的数据位宽与AXI4-Lite总线的数据位宽相同. 因此, 若AXI4-Lite总线上的单个读请求覆盖多个设备寄存器, 则可能导致设备状态出错. 也正因为这个原因, 并非所有设备都适合通过AXI4-Lite总线接入.
例如, 上述UART就不能通过数据位宽为32位的AXI4-Lite总线接入, 因为UART中设备寄存器的间隔只有1字节, 这意味着通过AXI4-Lite读出其中的一个设备寄存器, 也会影响相应的设备寄存器的状态, 这并不是我们期望的. 对于另一款设备寄存器地址空间如下的UART, 则可以通过数据位宽为32位的AXI4-Lite总线接入, 因为这些寄存器的间隔为4字节, 正好能在不影响相邻寄存器状态的情况下读出其中某个寄存器.
// Register addresses
`define UART_REG_RB `UART_ADDR_WIDTH'd0 // receiver buffer
`define UART_REG_IE `UART_ADDR_WIDTH'd4 // Interrupt enable
`define UART_REG_II `UART_ADDR_WIDTH'd8 // Interrupt identification
`define UART_REG_LC `UART_ADDR_WIDTH'd12 // Line Control
为了解决AXI4-Lite的上述问题, 完整的AXI总线协议通过arsize/awsize信号来指示实际访问的数据位宽, 同时引入"窄传输"的概念, 用于指示"实际数据位宽小于总线数据位宽"的情况. 这两个"数据位宽"的概念并非完全一致, 具体地, 总线数据位宽是在硬件设计时静态决定的, 它表示一次总线传输的最大数据位宽, 也用于计算总线的理论带宽; 而实际数据位宽(即arsize/awsize信号的值)则由软件访存指令中的位宽信息动态决定, 它表示一次总线传输的实际数据位宽, 例如, lb指令只访问1字节, 而lw指令则访问4字节.
有了arsize/awsize信号, 设备就可以得知软件需要访问的实际数据位宽, 从而在若干设备寄存器的地址紧密排布时, 亦可仅访问其中的某个寄存器, 避免意外改变设备的状态.
生成ysyxSoC的Verilog代码
首先你需要进行一些配置和初始化工作:
- 根据mill的文档介绍安装mill
- 可通过
mill --version检查安装是否成功; 此外,rocket-chip项目要求mill的版本不低于0.11, 如果你发现mill的版本不符合要求, 请安装最新版本的mill
- 可通过
- 在
ysyxSoC/目录下运行make dev-init命令, 拉取rocket-chip项目
以上两个步骤只需要进行一次即可. 完成上述配置后, 在ysyxSoC/目录下运行make verilog, 生成的Verilog文件位于ysyxSoC/build/ysyxSoCFull.v.
接入ysyxSoC
依次按照以下步骤将NPC接入ysyxSoC:
- 依照
ysyxSoC/spec/cpu-interface.md中的master总线, 将之前实现的AXI4Lite协议扩展到完整的AXI4 - 调整NPC顶层接口, 使其与
ysyxSoC/spec/cpu-interface.md中的接口命名规范完全一致, 包括信号方向, 命名和数据位宽- 对于不使用的顶层输出端口, 需要将其赋值为常数
0 - 对于不使用的顶层输入端口, 悬空即可
- 对于不使用的顶层输出端口, 需要将其赋值为常数
- 将
ysyxSoC/perip目录及其子目录下的所有.v文件加入verilator的Verilog文件列表 - 将
ysyxSoC/perip/uart16550/rtl和ysyxSoC/perip/spi/rtl两个目录加入verilator的include搜索路径中- 具体如何加入, 请RTFM(
man verilator或verilator的官方手册)- 如果你从来没有查阅过verilator有哪些选项, 我们建议你趁这次机会认真阅读一下手册中的
argument summary, 你很可能会发现一些新的宝藏
- 如果你从来没有查阅过verilator有哪些选项, 我们建议你趁这次机会认真阅读一下手册中的
- 具体如何加入, 请RTFM(
- 在verilator编译选项中添加
--timescale "1ns/1ns"和--no-timing - 将
ysyxSoC/build/ysyxSoCFull.v加入verilator的Verilog文件列表 - 将
ysyxSoCFull模块(在ysyxSoC/build/ysyxSoCFull.v中定义)设置为verilator仿真的顶层模块 - 将
ysyxSoC/build/ysyxSoCFull.v中的ysyx_00000000模块名修改为你的处理器的模块名- 注意, 你的处理器模块不应该包含之前作为习题的AXI4-Lite接口的SRAM和UART, 我们将使用ysyxSoC中的存储器和UART替代它们
- 但你的处理器模块应该包含CLINT, 它将作为流片工程中的一个模块, ysyxSoC不包含它
- 在仿真的cpp文件中加入如下内容, 用于解决链接时找不到
flash_read和mrom_read的问题extern "C" void flash_read(int32_t addr, int32_t *data) { assert(0); } extern "C" void mrom_read(int32_t addr, int32_t *data) { assert(0); } - 在仿真环境的
main函数中仿真开始前的位置加入语句Verilated::commandArgs(argc, argv);, 用于解决运行时plusargs功能报错的问题 - 通过verilator编译出仿真可执行文件
- 如果你遇到了组合回环的错误, 请自行修改你的RTL代码
- 尝试开始仿真, 你将观察到代码进入了仿真的主循环, 但NPC无有效输出. 我们将在接下来解决这个问题
ysyxSoC中还有一些代码检查相关的步骤说明, 但你后续还要改进NPC, 因此我们将要求你在考核前再进行代码检查. 如果你感兴趣, 目前开展代码检查的工作亦可, 我们不做强制要求.
接下来我们会依次介绍ysyxSoC中的设备, 以及如何让程序使用它们. 一些任务会要求你在RTL层面对一些设备模块进行实现或增强, 对于这些任务的大部分, 你都可以选择采用Chisel或者Verilog来完成. 特别地, 如果你选择使用Chisel, 你仍然需要阅读一些Verilog代码来帮助你完成任务.
最简单的SoC
回想TRM的其中两个要素, 有程序可以执行, 并且可以输出. 在之前的仿真过程中, 这两点都是通过仿真环境来实现的: 仿真环境将程序的镜像文件放到存储器中, NPC取第一条指令的时候, 程序已经位于存储器中了; 为了输出, 我们借助DPI-C函数pmem_read()调用仿真环境的功能, 并通过仿真环境的putchar()函数来实现输出. 但在真实的SoC中, 板卡上电后并没有仿真环境或运行时环境提供上述功能, 因此需要通过硬件来实现这些基本功能.
程序的存放
首先需要考虑程序放在哪里. 一般的存储器是易失存储器(volatile memory), 例如SRAM和DRAM, 它们在上电时并没有存放有效数据. 如果上电后CPU直接从内存中读取指令执行, 存储器读出什么数据是未定义的, 因此整个系统的行为也是未定义的, 从而无法让CPU执行预期的程序.
因此, 需要使用一种非易失存储器(non-volatile memory)来存放最初的程序, 使其内容能在断电时保持, 并在上电时能让CPU马上从中取出指令. 一个最简单的解决方案就是ROM(Read-Only Memory), 每次从ROM中相同位置读出的内容都是相同的.
ROM的实现有很多种, 总体上都是通过某种方式来将信息(在这里也是程序)存储在ROM中, 而且这种存储方式不会受到断电的影响, 从而具备非易失的属性. 如果考虑在ysyxSoC中的易用性, 最合适的就是mask ROM(掩膜ROM), 简称MROM, 其本质是将信息"硬编码"在门电路中, 因此对NPC来说访问方式非常直接.
不过因为MROM的某些问题, 我们并不打算在流片的时候使用它. 但MROM作为ysyxSoC中的第一个简单的非易失存储器来存放程序, 对我们测试ysyxSoC的接入还是非常合适的. 我们已经在ysyxSoC中添加了一个AXI4接口的MROM控制器, 其地址空间是0x2000_0000~0x2000_0fff.
测试MROM的访问
修改NPC的复位PC值, 使其从MROM中取出第一条指令, 并修改mrom_read()函数, 使其总是返回一条ebreak指令. 如果你的实现正确, NPC取到的第一条指令即是ebreak指令, 从而结束仿真.
因为NEMU还没有添加MROM的支持, 而NPC此时需要从MROM中取指, 故此时DiffTest机制不能正确工作. 不过目前的测试程序规模还很小, 你可以先关闭DiffTest功能, 后面我们再回过头来处理DiffTest的问题.
输出第一个字符
可以存放程序之后, 我们就需要考虑如何输出了. 为此, SoC中还需要提供一个最基本的输出设备. 真实的SoC中通常使用UART16550, 它包含一些设备寄存器, 用于设置字符长度, 波特率等信息. 在发送队列未满时, 即可通过写入对应的设备寄存器来发送字符.
ysyxSoC中已经集成了一个UART16550控制器. 为了测试它, 我们先编写一个最简单的程序char-test, 它直接输出一个字符之后就陷入死循环:
#define UART_BASE 0x?L
#define UART_TX ?
void _start() {
*(volatile char *)(UART_BASE + UART_TX) = 'A';
*(volatile char *)(UART_BASE + UART_TX) = '\n';
while (1);
}
在ysyxSoC中输出第一个字符
你需要:
- 根据ysyxSoC中的设备地址空间约定, 以及UART手册(在
ysyxSoC/perip/下的相关子目录中)中输出寄存器的地址, 来填写上述C代码中的?处, 使代码可以正确访问输出寄存器来输出一个字符 - 通过
gcc和objcopy命令编译char-test, 并将ELF文件中的代码节单独抽取到char-test.bin中 - 修改仿真环境的相关代码, 读入
char-test.bin并将其作为MROM的内容, 然后正确实现mrom_read()函数, 使其根据参数addr返回MROM中相应位置的内容
如果你的实现正确, 仿真过程将会在终端输出一个字符A.
Hint: 如果你不知道如何通过gcc和objcopy命令实现上述功能, 你可以参考"一生一芯"某节课的视频或课件. 如果你不知道应该参考哪一节课, 我们建议你把所有视频和课件都查看一遍, 相信这能帮助你补上很多你还不了解的知识点.
RTFM理解总线协议
如果你发现仿真过程中发现总线的行为难以理解, 先尝试RTFM尽可能理解手册中的所有细节. 随着项目复杂度的增加, 你将要为不仔细RTFM付出越来越大的代价.
如果你通过objdump等工具查看生成的ELF文件, 你会发现代码节的地址位于地址0附近, 与MROM的地址空间不一致. 实际上, 这个程序很小, 我们很容易确认, 无论将它放在哪个地址, 都能正确地按预期执行. 对于更复杂的程序, 上述条件不一定能满足, 我们需要显式地将程序链接到一个正确的位置, 使得NPC复位后可以正确地执行程序. 我们将在后面解决这个问题.
此外, 在真实的硬件场景下, 串口还需要根据波特率来将字符转换成串行的输出信号, 通过线缆传送到串口的接收端, 因此发送端在发送字符前, 软件还需要在串口的配置寄存器中设置正确的除数. 但当前的ysyxSoC仿真环境中并没有串口的接收端, 因此我们在串口控制器的RTL代码中添加了若干打印语句, 直接将串口发送队列中的字符打印出来, 这样软件也无需设置除数. 也因此, 上述代码在真实的硬件场景中并不一定能正常工作, 但作为前期测试, 这可以方便我们快速检查字符是否被正确写入串口发送队列. 我们将在成功运行足够多程序后, 再添加除数的设置, 使得代码可以在真实的硬件场景中工作.
去掉换行也能输出
上述char-test在输出字符A之后, 还输出一个换行符. 尝试仅仅输出字符A而不输出换行符, 你应该会观察到仿真过程连字符A都不输出了. 但如果每次输出一个字符之后都紧接着输出一个换行符, 打印出的信息将很难阅读.
为了解决这个问题, 你只需要给verilator传递一个选项. 尝试根据你对这个问题的理解, 通过RTFM找到并添加这个选项. 如果你添加了正确的选项, 你将会看到即使上述程序仅输出单个字符A, 也能成功输出.
Hint: PA讲义已经在好几处讨论过相关问题了. 如果你对此没有任何印象, 我们建议你重新仔细阅读讲义的每一处细节来查缺补漏.
更实用的SoC
确认ysyxSoC可以输出一个字符之后, 我们认为NPC访问设备的数据通路基本上打通. 不过, MROM虽然可以很好地实现程序的存放, 但它有一个很大的问题: 不支持写入操作. 但大多数程序都需要向存储器写入数据, 例如, C语言的调用约定允许被调用函数在栈上创建栈桢, 并通过栈桢存取数据. 因此, 一个仅包含MROM作为存储器的SoC可能无法支持那些需要调用函数的程序, 显然这并不实用. 为了支持写入操作, 我们需要添加RAM作为存储器, 并将程序的数据分配在RAM中.
最简单的RAM就是我们之前提到的SRAM, 我们可以在SoC中集成SRAM存储器. SRAM能够使用与处理器制造相同的工艺进行生产, 同时读写延迟只有1周期, 因此速度很快. 但SRAM的存储密度较低, 需要占用一定的芯片面积, 因此从流片价格的角度来计算, 成本是十分昂贵的. 考虑到流片成本, 我们只在SoC中提供8KB的SRAM. 我们已经在ysyxSoC中添加了一个AXI4接口的SRAM控制器, 其地址空间是0x0f00_0000~0x0f00_1fff. 注意到在前文的介绍中, SRAM的地址空间是0x0f00_0000~0x0fff_ffff, 共16MB, 这只是说明ysyxSoC中给SRAM预留了16MB的地址空间, 但考虑到实际的成本, 只使用了其中的8KB, 剩余的地址空间是空闲的, NPC不应该访问这部分空闲的地址空间.
有了这部分SRAM的空间, 我们就可以考虑将栈分配在SRAM空间, 从而支持一些AM程序的执行了.
为ysyxSoC添加AM运行时环境
为了运行更多程序, 我们需要基于ysyxSoC提供向程序提供相应的运行时环境. 噢, 这不就是实现一个新的AM吗? 这对你来说已经很熟悉了. 不过我们还是需要考虑ysyxSoC的一些属性对于运行时环境带来的影响.
首先我们来看TRM. 回顾TRM的内容, 我们需要考虑如何在ysyxSoC上实现TRM的API:
- 可以用来自由计算的内存区间 - 堆区
- 堆区需要分配在可写的内存区间, 因此可以分配在SRAM中
- 程序 "入口" -
main(const char *args)main()函数由AM上的程序提供, 但我们需要考虑整个运行时环境的入口, 即需要将程序链接到MROM的地址空间, 并保证TRM的第一条指令与NPC复位后的PC值一致
- "退出"程序的方式 -
halt()- ysyxSoC不支持"关机"等功能, 为方便起见, 可借助
ebreak指令让仿真环境结束仿真
- ysyxSoC不支持"关机"等功能, 为方便起见, 可借助
- 打印字符 -
putch()- 可通过ysyxSoC中的UART16550进行输出
由于NPC复位后从MROM开始执行, 而MROM不支持写入操作, 因此我们需要额外注意:
- 程序中不能包含对全局变量的写入操作
- 栈区需要分配在可写的SRAM中
为ysyxSoC添加AM运行时环境
添加一个riscv32e-ysyxsoc的新AM, 并按照上述方式提供TRM的API. 添加后, 将cpu-tests中的dummy测试编译到riscv32e-ysyxsoc, 并尝试在ysyxSoC的仿真环境中运行它.
Hint: 为了完成这个任务, 你需要一些链接的知识. 如果你不熟悉, 可以参考"一生一芯"相关的视频和课件.
无法运行的测试
尝试在ysyxSoC中运行cpu-tests中的fib, 你将发现运行失败. 尝试阅读提示信息, 你觉得应该如何解决这个问题?
重新添加DiffTest
我们新增了MROM和SRAM, 接下来一段时间我们都会在MROM和SRAM上运行程序. 但目前NEMU并没有MROM和SRAM, 如果我们在DiffTest的时候跳过MROM和SRAM和访问, 将会跳过所有指令的执行, 使得DiffTest将无法起到预期的作用.
为了重新添加DiffTest, 你需要在NEMU中添加MROM和SRAM, 并在NPC的仿真环境初始化DiffTest时, 将MROM中的内容同步到NEMU中, 然后检查在MROM中执行的每一条指令.
你可以按照你的想法修改NEMU的代码, 但我们还是建议你尽量不添加新的DiffTest API, 框架代码提供的DiffTest API已经足够实现上述功能了.
让NPC抛出Access Fault异常
尽管这不是必须的, 我们建议你在NPC中添加Access Fault的实现. 在系统运行发生意外导致访问了未分配的地址空间, 或者设备返回错误时, ysyxSoC可以通过AXI的resp信号传递相关的错误信息. 即使程序未启动CTE, 也可以让NPC在发生这些事件时跳转到地址0, 让你感觉到程序运行不正常. 相比于放过这些错误事件让NPC继续运行, 这也许能帮助你节省大量的调试时间.
内存访问测试
可以执行dummy测试后, 我们认为NPC基本上能成功访问ysyxSoC的SRAM了. 我们知道, 访存是程序运行的基础. 为了对访存行为进行更充分的测试, 我们需要编写一个程序mem-test来测试更大范围的内存.
从范围上看, mem-test希望能测试所有可写内存区域. 但mem-test本身的运行需要栈区的支持, 而栈区需要分配在可写内存区域, 因此在测试时需要绕开栈区, 避免栈区内容被覆盖, 导致mem-test本身运行出错. 我们可以把栈区放在SRAM的末尾, 并把堆区的起始地址设置在SRAM的开始, 堆区的结束地址设置在栈区的起始地址(即栈顶的初值). 设置好堆区的范围之后, 就可以把堆区作为mem-test的测试范围.
从测试方式上看, 我们采用一种最直观的方式: 先往内存区间写入若干数据, 再读出并检查. 我们可以让写入的数据与内存的地址相关, 从而方便检查, 例如data = addr & len_mask. 以下示意图展示了通过8位, 16位, 32位, 64位的写入数据和地址之间的关系.
SRAM_BASE SRAM_BASE + 0x10
| |
V V
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
8-bit |00|01|02|03|04|05|06|07|08|09|0a|0b|0c|0d|0e|0f|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
16-bit |00|00|02|00|04|00|06|00|08|00|0a|00|0c|00|0e|00|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
32-bit |00|00|00|0f|04|00|00|0f|08|00|00|0f|0c|00|00|0f|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
64-bit |00|00|00|0f|00|00|00|00|08|00|00|0f|00|00|00|00|
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
测试分两步, 第一步是依次向各个内存区间写入相应数据, 第二步是依次从各个内存区间中读出数据, 并检查是否与之前写入的数据一致. 可分别通过8位, 16位, 32位, 64位的写入方式重复上述过程.
通过mem-test测试内存访问
在am-kernels中编写一个新的程序mem-test, 完成上述内存测试功能. 如果检查数据时发现不一致, 就通过halt()结束mem-test的运行.
一些提示:
- 目前程序的全局变量分配在MROM中, 因此你的程序不能包含对全局变量的写入操作
printf()的代码较复杂, 调用printf()可能会使程序大小超过MROM空间, 而且其中还包含不少访存操作, 甚至有可能包含对全局变量的写入, 因此目前我们不推荐通过printf()打印信息, 不过DiffTest, trace和波形应该足够帮助你排除bug- 为了避免编译优化带来的影响, 你需要想办法确认程序在运行过程中确实执行了预期的访存操作
智能的链接过程
你已经在klib中实现了printf(), 但如果没有在mem-test中调用printf(), 链接后的可执行文件确实不包含printf()的代码. 这种智能的链接方式能够在存储器空间有限的情况下避免生成不必要的代码,
你知道目前的链接流程中有哪些相关的步骤或选项来实现上述功能吗?
真实的内存访问测试程序
事实上, 上述测试方法并不能较为全面地测试各种访存问题. 真实的内存测试程序通常会采用更复杂的模式来测试内存的读写, 可以覆盖多种故障, 例如memtest86. 还有实现在硬件的内存测试单元, 它们能进行更深入的测试, 感兴趣的同学可以了解一下MBIST(Memory Build-In Self Test).
支持全局变量的写入操作
很多程序都会写入全局变量, 因此我们还需要寻找一个解决方案来支持全局变量的写入操作. 由于全局变量位于数据段中, 为了方便叙述, 下文用"数据段"来代替"全局变量". 一个直接的想法是, 既然MROM不支持写操作, 我们就把数据段分配在SRAM中. 但在系统启动时, SRAM中并不包含有效的数据, 因此只能把数据段放到MROM中, 才能在系统启动时访问. 为了解决这个问题, 我们可以在程序真正开始执行前, 将数据段从MROM加载到SRAM中, 并让接下来的代码访问加载到SRAM中的数据段, 通过SRAM的可写特性支持全局变量的写入操作.
事实上, 真实的操作系统也需要把程序加载到存储器中运行, 其中还需要进行很多复杂的操作. 因此执行上述加载操作的代码也可以看成一个加载器, 只不过目前其功能还很简单, 它只负责将程序的数据段从MROM加载到SRAM. 但由于这个加载器的工作时刻是在系统启动时, 因此我们将其称为bootloader.
简单来说, 我们需要实现以下三点:
- 得到数据段在MROM中的地址MA(mrom address)和在SRAM中的地址SA(sram address), 以及数据段的长度LEN
- 将数据段从MA复制到SA
- 让程序代码通过SA访问数据段
对于第2点, 我们只需要调用memcpy()即可实现. 对于MA, 我们可以在链接脚本的数据段开始前定义一个符号, 即可在运行时刻让bootloader获得该符号的地址; 而对于LEN, 在链接脚本的数据段结束后定义一个符号, 与上述符号相减即可. 一个需要考虑的问题是, 如何获得SA. 一方面, 由于SA是一个地址, 而程序中的地址需要在链接中的重定位阶段才能确定, 因此SA最早也要在链接阶段才能确定. 另一方面, 由于第3点要求后续代码需要通过SA访问数据段, 而运行时刻的bootloader很难修改相应指令中的访问地址, 因此SA必须在运行前确定. 综合考虑上述两点, 我们可以得出结论: SA只能在链接阶段确定, 我们需要在链接脚本中定义SA.
为此, 我们需要用到链接脚本中的两种符号地址. 一种是虚拟内存地址(virtual memory address, VMA), 它表示程序运行时对象所在的地址; 另一种是加载内存地址(load memory address, LMA), 它表示程序运行前对象所在的地址. 通常情况下, 这两种地址相同. 但在上述需求中, 这两种地址有所不同: 数据段存放在MROM中, 但需要让程序代码访问加载到SRAM中的数据段, 即MA是LMA, SA是VMA.
为了区分两种地址, 我们需要对链接脚本稍作修改. 首先, 我们需要定义两种存储器区间:
MEMORY {
mrom : ORIGIN = 0x20000000, LENGTH = 4K
sram : ORIGIN = 0x0f000000, LENGTH = 8K
}
然后在描述节和段的映射关系时, 显式地说明段的VMA和LMA. 例如:
SECTIONS {
. = ORIGIN(mrom);
.text : {
/* ... */
} > mrom AT> mrom
/* ... */
}
其中>后表示VMA在的存储器区间, AT>后表示LMA所在的存储器区间. 上述链接脚本表示, 代码段将链接到MROM空间, 同时也位于MROM空间.
通过bootloader将数据段加载到内存
根据上述内容, 在TRM调用main()函数前, 将数据段加载到SRAM, 从而支持后续代码写入全局变量. 如果你的实现正确, 你应该能成功运行cpu-tests中除hello-str外的所有测试.
一些提示:
- bootloader的加载过程可以通过汇编代码编写一些简单循环来实现, 也可以在C代码中调用
memcpy()等函数 - 链接脚本的编写可以参考官方文档
- 为了强迫大家仔细RTFM, 我们在上述介绍中忽略了一个你有可能已经想到的小细节, 这个细节已经在官方文档中提到, 即使你真的没想到, 也可以通过仔细阅读文档来得知
- 可以通过
--print-map选项查看ld如何进行链接
通过串口输出
支持全局变量的写入操作后, 只要MROM和SRAM能装下的可计算程序, 理论上都能运行. 最后我们来讨论putch()的实现.
实现putch()
仿照上文的char-test, 通过向UART16550写入字符, 实现putch()的功能. 实现后运行hello程序, 如果你的实现正确, 你将看到NPC输出若干字符.
不过你发现NPC并没有输出全部字符, 尽管这并不是我们所期望的, 但目前来说这是预期行为, 我们接下来将会修复这个问题.
观察NPC输出的行为
尝试修改hello.c的代码, 增加或减少字符串的长度, 观察NPC输出字符串的行为. 根据你的观察, 你猜测原因可能是什么?
这个问题更本质的提问方式是: 你是否了解"程序在ysyxSoC中输出一个字符"的每一处细节? 尽管我们接下来就会公布答案, 愿意挑战的同学可以先暂停往下阅读, 尝试RTFSC梳理其中的每一处细节, 毕竟通过自己的探索获得答案能收获更大的成就感.
你也许已经观察到这个奇怪的现象: NPC输出了一部分字符, 也通过ebreak指令成功结束仿真, 说明程序本身没有致命问题, 但有一些字符却消失了: 程序本应该将它们写入到串口, 但在终端上却看不到它们. 如果你仔细观察, 你会发现, 无论程序中的字符串有多长, 终端上最多只输出16个字符. 16作为2的幂, 看起来并不是巧合, 很可能预示着某种配置.
当然, 无论猜想多么精彩, 最终都要RTFSC去验证猜想, 这里我们还是把RTFSC的过程留给大家. 认真RTFSC之后, 你会发现导致上述问题的原因, 竟然是软件没有对串口初始化! 因为没有初始化, 串口的发送功能并没有工作, 因此写入串口的字符一直占用串口的发送队列, 队列满后就无法写入更多字符.
事实上, 在往串口输出字符之前, 软件需要进行以下初始化:
- 设置串口收发参数, 具体包括波特率, 字符长度, 是否带校验位, 停止位的位宽等
- 波特率指每秒传送的字符数. 不过通常并非直接在寄存器中设置波特率, 而是设置一个与波特率成反比的除数: 除数越小, 波特率越大, 传输速率越快, 但受电气特性的影响, 误码率也越高, 字符传送成功的概率越低; 相反, 除数越大, 波特率越小, 传输速率越慢, 软件等待的时间也越长. 除数的值还与串口控制器的工作频率有关, 后者即串口每秒传送的比特数, 可RTFM了解两者的具体关系.
- 串口收发端的参数配置要完全一致, 才能正确发送和接收字符. 通常用形如
115200 8N1等方式来描述一组参数配置, 它表示波特率是115200, 字符长度是8位, 不带校验位, 1位停止位.
- 按需设置中断, 不过NPC目前不支持中断, 因此可不设置
正确实现串口的初始化
你需要在TRM中添加代码, 设置串口的除数寄存器. 由于ysyxSoC本质上还是一个仿真环境, 没有串口接收端, 也没有电气特性的概念, 因此目前可随意设置上述除数, 不必担心误码率的问题. 当然, 在真实的芯片中, 除数寄存器的设置是需要仔细考量的. 此外, 我们也会在后续实验内容中接入一个串口终端来进行更多的测试.
具体如何设置除数, 你可以RTFM了解UART IP的功能, 也可以RTFSC, 结合UART16550寄存器的RTL实现, 帮助你理解设置的除数如何工作.
如果除数寄存器设置得足够小, 你会观察到hello程序多输出了一些字符, 但仍然会出现字符丢失的情况. 为了解决这个问题, 我们需要在向串口写入字符之前, 保证其发送队列一定有空闲位置可以写入. 这可以通过查询串口的状态寄存器实现: 软件可以轮询相关寄存器, 直到确保写入的字符不会丢失为止.
输出前轮询串口的状态寄存器
你需要修改putch()的代码, 在输出前先查询串口发送队列的情况. 具体如何查询, 同样地, 你可以RTFM了解UART IP的功能, 也可以RTFSC, 结合UART16550寄存器的RTL实现, 帮助你理解相关的功能.
串口能正常工作后, TRM就可以运行更多程序了. 不过目前程序的规模还是受限于MROM和SRAM的大小. 受制造工艺的影响, 如果要在成本可接受的情况下使用更大的存储器, 我们就需要使用一些更慢的存储器.
可重复编程的非易失存储器
首先我们来解决程序存放的问题. MROM除了成本高之外, 另一个缺点就是可编程性很弱. 事实上, MROM只支持制造时编程, 即MROM的内容是在RTL设计时决定的, 经过后端物理设计后, 晶圆厂将根据版图制作用于光刻的掩膜(mask), 然后用这个掩膜来制造芯片, 这也是mask ROM中mask的含义. 但在芯片制造完成后, MROM中存储的内容无法进行更改. 如果要通过重新流片的方式来更换芯片运行的程序, 代价是不可接受的.
随着存储技术的发展, 人们发明了可重复编程和擦除的ROM, 目前广泛使用的flash存储器就是其中一种. 用户能够在某些条件下擦除flash存储器中存放的内容, 并重新进行写入. 通常来说, 用户只需要购买一个数十元的烧录器, 即可通过烧录软件更新flash中的内容. 通过这种方式, 更换flash中存放的程序的代价变得可以接受.
U盘的流行甚至使得用户无需购买专门的烧录器. U盘的本质就是一块USB接口的flash存储器, 外加一个MCU. 如今操作系统都内置USB协议的flash驱动程序, 因此用户只需要将U盘插入计算机, 即可往其中写入数据. 不过这对当前的NPC来说有点复杂了, 不仅需要配备一个USB控制器, 还需要运行相应的驱动程序才能完成烧录操作, 因此"一生一芯"还是采用烧录器的方案.
flash的存储单元
建设中
本小节无编程任务, 感兴趣的同学可以先阅读课件或观看B站录播.
flash颗粒的内部结构
为了让大家进一步了解flash存储器, 我们介绍型号为W25Q128JV的flash颗粒的内部结构. 这种型号的flash颗粒有24根地址线, 可以存储16MB的数据, 这足够我们存放绝大部分的测试程序了. 整个flash颗粒的存储阵列划分成256个块(Block), 每个块的大小是64KB; 每个块的内部又划分成16个扇区(Sector), 每个扇区的大小是4KB; 每个扇区的内部又划分成16个页(Page), 每个页的大小是256B.
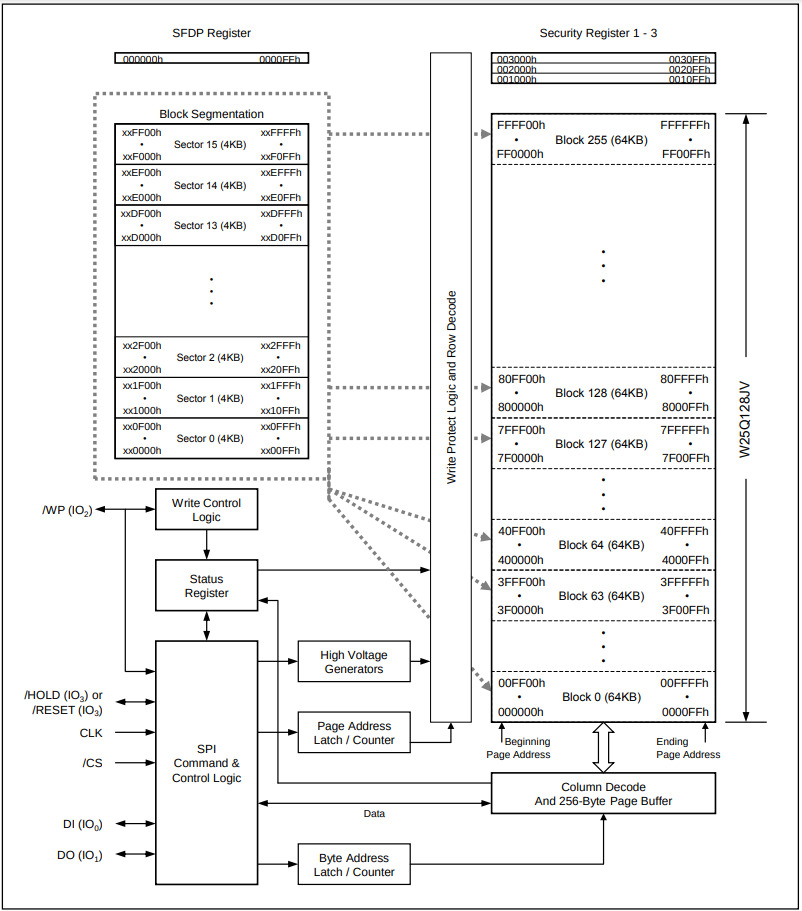
在flash颗粒中, 字节是最小的读取单位, 支持随机读取. 对于写入操作, 就比较复杂了, 如果要写入0, 只需要对相应的存储单元进行编程操作即可; 但如果要写入1, 就要先进行擦除操作, 而由于flash存储单元的物理特性, 扇区是最小的擦除, 也即, 我们需要将所在扇区的存储内容全部读出, 然后擦除该扇区, 再按照新数据对该扇区进行编程. 可见, flash的写入开销比读取大得多.
除了存储阵列外, flash颗粒中还包含若干寄存器, 包括一些地址寄存器用于控制读写flash颗粒的地址, 控制寄存器用于控制颗粒的行为(如写保护, 访问权限等), 状态寄存器用于存放flash颗粒当前读写的状态. 可以看到, flash颗粒的内部就是一个设备控制器!
为了访问flash颗粒, 外部需要向其发送命令. flash颗粒接收到外部的命令后, 将会对命令进行解析, 然后执行命令的具体功能. 这与CPU执行指令的过程是很类似的, CPU的指令周期包括取指, 译码, 执行, 更新PC, 而对包括flash颗粒在内的大部分设备来说, 其处理过程包括接收命令, 解析, 执行, 等待新命令. 至于命令的格式和功能, 当然是由相应的手册来定义了. 例如, 8位命令03h表示从flash颗粒中读出数据, 命令后紧跟24位的存储单元地址. 因此, 如果你学会了CPU设计, 你完全有能力根据flash颗粒的手册设计出flash颗粒的核心逻辑.
借助总线, 我们很容易将CPU的访存请求翻译成flash颗粒的读写命令. 以目标地址为flash空间的load请求为例, CPU的LSU在执行load指令时, 将在总线上发起一个读事务, 该读事务经过Xbar最终传到flash控制器, flash控制器检查该事务的属性, 发现是读事务, 则生成相应的读命令, 并根据总线事务中的地址生成读命令的地址, 将该命令发往flash颗粒. 一段时间后, flash控制器得到从flash颗粒中读出的数据, 便将这些数据作为总线事务的回复传送给CPU, CPU的LSU接收到读结果后, load指令继续执行.
RTFSC理解从flash中读出数据的过程
ysyxSoC包含了上述过程的代码实现, 并且将flash存储空间映射到CPU的地址空间0x3000_0000~0x3fff_ffff. 你需要先在ysyxSoC/perip/spi/rtl/spi_top_apb.v中定义宏FAST_FLASH, 然后尝试结合代码理解上述过程.
至于flash的写入, 由于flash的写入需要先擦除一整个扇区, 再重新写入整片的数据, 因此需要向flash颗粒发送多次命令. 不过当前我们只是期望用flash替代MROM, 使得NPC在复位时能从flash中取出有效的指令, 因此我们暂时不会对flash颗粒进行写操作, ysyxSoC的flash颗粒代码中也仅支持读操作.
从flash中读出数据
理解从flash中读出数据的过程后, 接下来就可以通过代码测试这一过程了:
- 在仿真环境中定义一个代表flash存储空间的数组
- 在仿真环境初始化时, 往上述数组写入若干内容
- 此操作可以看作是模拟了往flash颗粒中烧录数据的过程
- 正确实现
flash_read()函数, 使其根据参数addr返回flash中相应位置的内容 - 在
am-kernels中编写一个简单的测试程序, 从flash存储空间中读出内容, 并检查是否与仿真环境初始化时设置的内容一致
通过SPI总线协议访问flash颗粒
因为flash颗粒的制造工艺与处理器的制造工艺不同, 因此处理器芯片和flash颗粒芯片要单独制造生产, 然后再焊接到板卡上, 通过板卡上的走线来通信. 也因为这样, 引脚数量就成了一个需要考虑的问题. 一方面, 如果引脚数量太多, 就不利于将芯片做小, 这对板卡的布局和面积都会产生负面影响; 另一方面, 板卡上的走线距离通常比芯片内部的走线要长, 信号也更容易受到干扰, 故引脚数量太多也会导致板卡上走线密集, 这些走线之间也很容易相互干扰, 影响信号的稳定性.
以上文提到的读命令为例, 一次读操作至少涉及8位的命令, 24位的地址, 以及8位的数据, 这就已经占用40比特的信号了. 因此把这些信号全部通过引脚通到flash颗粒外部, 并不是一个好的方案.
为了降低flash颗粒的引脚数量, 一般会在flash颗粒中添加一个SPI总线接口. SPI的全称是Serial Peripheral Interface, 是一种串行总线协议, 通过少数几根信号线在master和slave之间进行通信.
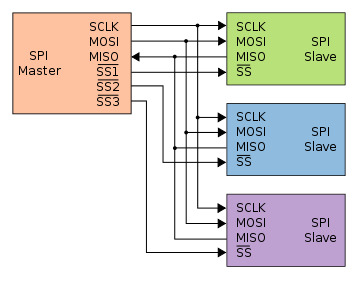
SPI总线总共只有4种信号:
SCK- master发出的时钟信号, 只有1位SS- slave select, master发出的选择信号, 用于指定通信对象, 每个slave对应1位MOSI- master output slave input, master向slave通信的数据线, 只有1位MISO- master input slave output, slave向master通信的数据线, 只有1位
为了基于SPI总线进行通信, master通常先通过SS信号选择目标slave, 然后通过SCK信号向slave发出SPI的时钟脉冲, 同时将需要发送的信息转化成串行信号, 逐个比特通过MOSI信号传输给slave; 然后监听MISO信号, 并将通过MISO接收到的串行信号转化成并行信息, 从而获得slave的回复.
slave的工作方式是类似的, 如果slave在SS信号有效的情况下收到SCK时钟脉冲, 则监听MOSI信号, 并将通过MOSI接收到的串行信号转化成并行信息, 从而获得master的传来的命令; 处理完命令后, 将需要回复的信息转化成串行信号, 逐个比特通过MISO信号传输给master.
可以看到, 除了状态机之外, 实现SPI总线协议的核心就是串行/并行信号之间的转换, 具体来说就是发送方如何将信号发送出去, 以及接收方如何采样并接收信号. 一方面需要考虑发送的尾端(endianness): 是从高位到低位发送, 还是从低位到高位发送; 另一方面需要考虑发送和采样的时机(时钟相位, clock phase): 是在SCK上升沿时发送/采样, 还是在SCK下降沿时发送/采样. 有时还会约定时钟空闲时的电平(时钟极性, clock polarity): 是高电平空闲还是低电平空闲. 在发送和采样的过程中, SCK起到了同步的作用, 双方共同约定发送/采样的尾端和时机, 并在RTL层次正确地实现约定. 在真实场景中, 不同的slave可能有不同的约定, 这意味着在与不同slave通信的时候, master需要配合slave的约定来进行发送和采样.
不过, 上层软件并不希望关心这些信号层次的行为, 因此SPI master还需要将这些信号层次的行为抽象成设备寄存器, 上层软件只要访问这些设备寄存器, 就可以查询或控制SPI master. 事实上, 在总线架构中, SPI master有两重身份, 它一方面是AXI(或其他AMBA协议, 如APB)的slave, 负责接收来自CPU的命令, 另一方面又是SPI的master, 负责给SPI的slave发送命令. 因此我们也可以将SPI master看成是AXI和SPI之间的一个桥接模块, 用于将AXI请求转换成SPI请求, 从而与SPI的slave进行通信.
ysyxSoC集成了SPI master的实现, 并将其设备寄存器映射到CPU的地址空间0x1000_1000~0x1000_1fff, 相关代码和手册在ysyxSoC/perip/spi/下的相应子目录中. 有了设备寄存器的抽象, 我们就可以梳理上层软件的行为了. 为了与不同的slave通信, master一般需要支持多种约定, 具体设置成哪一种约定, 是通过配置设备寄存器来实现的. SPI驱动程序在与slave通信之前, 先设置SS寄存器来选择目标slave, 并按照slave的约定配置SPI master的控制寄存器, 然后再将需要传输的数据写入发送数据寄存器, 最后往某控制寄存器写入表示"开始传输"的命令. SPI驱动程序可以轮询SPI master的状态寄存器, 当状态标志为"忙碌"时则等待, 直到状态标志为"空闲"为止, 此时可从接收数据寄存器中读出slave的回复.
实现基于SPI协议的位翻转模块
为了熟悉并测试SPI的基本流程, 我们来编写一个简单的位翻转模块bitrev. 该模块接收一个8位的数据, 然后输出该数据的位翻转结果, 也即, 将输入数据的第0位与第7位交换, 第1位与第6位交换...
具体地, 如果你选择Verilog, 你需要在ysyxSoC/perip/bitrev/bitrev.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/BitRev.scala的bitrevChisel模块中实现相应代码, 并将ysyxSoC/src/SoC.scala中的Module(new bitrev)修改为实例化bitrevChisel模块.
如果这个bitrev模块的输入信号和输出信号是8位的, 那将是一个简单的数字电路作业; 不过bitrev模块是通过SPI总线来通信的, 因此你还需要实现串行/并行信号之间的转换 (但这也不难, 我们的Chisel参考代码只需添加5行). 一些提示如下:
- SPI master输出的
SS信号是低电平有效的, 而且要求slave空闲时, 将MISO信号设置为高电平 - 由于
SCK只在SPI传输过程中产生脉冲, 你可能需要用到异步复位的功能, 不过这个bitrev模块并不参与流片, 在其中使用异步复位并不影响流片的流程- 如果你使用Chisel, 你可以参考Chisel文档中关于Reset的说明
- 如果你使用Chisel, 并且希望使用时钟下降沿触发, 你可以参考这个帖子
- 你还需要取消
ysyxSoC/perip/spi/rtl/spi_top_apb.v中定义的宏FAST_FLASH, 使得APB请求可以访问SPI master的设备寄存器
在硬件上实现bitrev模块后, 你还需要编写一个程序来测试它. 尝试编写一个AM程序, 通过驱动SPI master往bitrev模块中输入一个8位数据, 然后读出其处理后的结果, 检查结果是否符合预期. 具体地:
- 将需要发送的数据设置到SPI master的TX寄存器中
- 设置除数寄存器, 它用于指示SPI master传送时
SCK频率与当前SPI master时钟频率的比例. 由于verilator中没有频率的概念, 因此可以设置一个使得SCK频率尽量高的除数.- 在真实芯片中,
SCK频率过高可能会导致slave无法正确工作, 因此除数寄存器的设置需要符合slave工作频率的要求
- 在真实芯片中,
- 设置
SS寄存器, 选择bitrev模块作为slave- ysyxSoC已经将bitrev作为一个SPI slave与SPI master相连, 其slave编号为7
- 设置控制寄存器, 具体地, 你需要设置好其中的每一个字段, 其中一些字段的说明如下:
CHAR_LEN- 由于输入数据和输出数据的长度均为8位, 因此传输长度应为16位Rx_NEG,Tx_NEG和LSB- 由于bitrev只是一个测试模块, 并不参与最终的流片, 因此我们不规定bitrev模块的这些细节, 具体交给你来约定, 你需要在选择一种约定后, 按照这种约定来实现bitrev模块, 设置SPI的控制寄存器并编写软件, 使得三者可以按照相同的约定来进行通信IE- 目前我们不使用中断功能ASS- 是否设置均可, 但需要与软件协同考虑
- 轮询控制寄存器中的完成标志, 直到SPI master完成数据传输
- 从SPI master的RX寄存器中读出slave返回的数据
我们给出一次数据传输的示例, 注意这只是一个效果示意图, 你的实现不必与其完全相同:
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
SCK | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
--------+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ +------------
--------+ +--------
SS | |
+-------------------------------------------------------------------------------------------------------------------------------+
+-------+-------+-------+-------+-------+-------+-------+-------+-------+------------------------------------------------------------------------
MOSI | b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
+-------+-------+-------+-------+-------+-------+-------+-------+
+-----------------------------------------------------------------------+-------+-------+-------+-------+-------+-------+-------+-------+--------
MISO | b0 | b1 | b2 | b3 | b4 | b5 | b6 | b7 |
+-------+-------+-------+-------+-------+-------+-------+-------+
SPI传输过程的细节较多, 你很可能需要RTFM和RTFSC帮助你理解其中的细节.
通过SPI总线从flash中读出数据
尝试编写一个AM程序, 在其中实现一个原型为uint32_t flash_read(uint32_t addr)的函数, 注意这个flash_read()函数和上文中提到的同名的DPI-C接口函数不同. 此处的flash_read()函数通过驱动SPI master, 读出flash颗粒中起始地址为addr的32位内容. 这个过程和上文的bitrev例子类似:
- 将需要发送给flash颗粒的命令设置到SPI master的TX寄存器中
- 设置除数寄存器
- 设置
SS寄存器, 选择flash颗粒作为slave, 其slave编号为0 - 设置控制寄存器:
CHAR_LEN- 由于读命令的长度共32位, 且需要读出32位数据, 因此传输长度应为64位Rx_NEG和Tx_NEG- 需要根据slave的相关文档进行设置- 在真实芯片中,
Rx_NEG和Tx_NEG设置错误可能会导致电路工作时的保持时间(hold)违例, 从而无法采样到正确的数据. 不过在verilator中没有时序的概念, 因此某些不正确的设置可能也会得到正确的结果, 但我们还是建议你在RTFM后严格按照约定来设置
- 在真实芯片中,
LSB- 需要根据slave的相关文档进行设置, 在必要情况下, 读出的数据可通过软件调整其尾端IE- 目前我们不使用中断功能ASS- 是否设置均可, 但需要与软件协同考虑
- 轮询控制寄存器中的完成标志, 直到SPI master完成数据传输
- 从SPI master的RX寄存器中读出slave返回的数据
实现flash_read()后, 通过该函数从flash存储空间中读出内容, 并检查是否与仿真环境初始化时设置的内容一致.
从flash中加载程序并执行
尝试将上文提到的char-test程序存放到flash颗粒中, 编写测试程序, 通过flash_read()将char-test从flash读入到SRAM的某个地址中, 然后跳转到该地址执行char-test.
从flash中取指
可以从flash中正确读出数据后, 我们就可以考虑将需要执行的程序放到flash中, 让NPC从flash中取出第一条指令了.
等等, 好像哪里不太对... 我们刚才是通过flash_read()这个函数从flash中读出内容, 这个函数也是程序的一部分, 它被编译成指令序列放在MROM中, NPC从MROM中取出指令并执行. 但如果将flash_read()的指令序列也一同烧录到flash中, 谁来取出flash_read()的指令并执行呢? 这变成了一个"鸡和蛋"的循环依赖问题.
再深入分析, 产生这个问题的根源是, 我们尝试通过软件函数来实现硬件上的取指操作, 这并不合理, 因为取指操作是一个硬件层次的行为. 因此, 我们应该尝试在硬件层次实现"从flash中取指"的功能,
要在硬件层次实现flash_read()的功能, 也就是要按照一定的顺序在硬件上访问SPI master的寄存器. 你也许想到了, 那就是用状态机实现flash_read()的功能! 与上文从flash中加载程序并执行的方式不同, 这种从flash颗粒中取指的方式并不需要在执行程序之前将程序读入到内存(对应上文的SRAM)中, 因此也称"就地执行"(XIP, eXecute In Place)方式.
为了区分正常访问SPI master的情况, 我们需要将通过XIP方式访问flash 的功能映射到与SPI master设备寄存器不同的地址空间. 事实上, 我们可以对之前访问的flash存储空间0x3000_0000~0x3fff_ffff稍作调整, 将其定义为通过XIP方式访问的flash存储空间. ysyxSoC中的Xbar已经将SPI master的地址空间0x1000_1000~0x1000_1fff和 flash存储空间0x3000_0000~0x3fff_ffff都映射到 ysyxSoC/perip/spi/rtl/spi_top_apb.v模块中的APB端口, 也即, spi_top_apb.v模块中的APB端口能接收上述两段地址空间的请求, 你可以通过检查APB的目标地址区分它们.
通过XIP方式访问flash
综上所述, 实现XIP方式的大致过程如下:
- 检查APB请求的目标地址, 若目标地址落在SPI master的地址空间, 则正常访问并回复
- 若目标地址落在flash存储空间, 则进入XIP模式. 在XIP模式中, SPI master的输入信号由相应状态机决定
- 状态机依次往SPI master的设备寄存器中写入相应的值, 写入的值与
flash_read()基本一致 - 状态机轮询SPI master的完成标志, 等待SPI master完成数据传输
- 状态机从SPI master的RX寄存器中读出flash返回的数据, 处理后通过APB返回, 并退出XIP模式
- 状态机依次往SPI master的设备寄存器中写入相应的值, 写入的值与
具体地, 如果你选择Verilog, 你需要在ysyxSoC/perip/spi/rtl/spi_top_apb.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/SPI.scala的Impl类中实现相应代码.
在通过XIP方式取指之前, 我们先测试是否能通过XIP方式完成CPU发出的读请求. 编写测试程序, 直接通过指针从flash存储空间中读出内容 并检查是否与仿真环境初始化时设置的内容一致.
同样地, 目前我们不考虑通过XIP方式支持flash的写入操作, 因此你最好想个办法在检测到写操作时报告错误, 来帮助你及时诊断问题的原因.
通过XIP方式执行flash中的程序
将上文提到的char-test程序存放到flash颗粒中, 编写测试程序, 跳转到flash中执行char-test.
用flash替代MROM
确认可以从flash中取指执行后, 我们就可以用flash完全替代MROM来存放第一个程序了. 修改PC的复位值, 使NPC复位后从flash中取出第一条指令. 你还需要进行一系列修改来适配这一改动, 包括... 还是交给你来判断吧, 这也是测试你是否了解这个过程中的每一个细节.
因为flash的大小比之前使用的MROM大得多, 因此我们可以存放并执行更大的程序了, 尝试运行coremark等包含printf()的程序. 如果你运行microbench, 你会发现有不少子项会因为堆区大小不足而无法运行.
coremark要跑好久啊
如果允许你动手, 你会如何减少coremark的运行时间呢?
Hint: RTFSC
尝试在flash上执行flash_read()函数
你可能会发现错误, 请尝试分析为什么会出现这个错误.
添加学号CSR并输出学号
为了标识不同同学的NPC, 我们可以在CSR的标识寄存器中设置自己的学号. 具体地, 你可以在NPC中添加如下两个CSR:
mvendorid- 从中读出ysyx的ASCII码, 即0x79737978marchid- 从中读出学号数字部分的十进制表示, 假设你的学号为ysyx_22068888, 则读出22068888, 即0x150be98
实现后, 可在riscv32e-ysyxsoc的TRM进入main()函数前读出上述两个CSR的值并输出.
通过中断等待SPI master传输完成
我们刚才的XIP实现是通过轮询的方式不断查询SPI master的传输是否完成, 事实上, SPI master还支持中断通知模式, 设置控制寄存器的IE位后, SPI master在传输结束后将会发出中断信号, XIP模式的状态机可以通过等待这个中断信号来等待SPI master传输完成. 感兴趣的同学可以实现上述的中断查询方式.
尽管这不会带来显著的性能提升, 但在实际的系统中, 等待中断的实现可以节省能耗, 因为轮询方式发起的请求和回复并没有对系统的运行带来实际的贡献.
存储密度更大的随机存储器
通过flash解决了MROM只能存放小程序的问题后, 我们还需要考虑数据的存放. 如果程序需要写入的数据过多, 超过SRAM能提供的8KB, 那这个程序还无法在ysyxSoC上运行. 为此, 我们需要一个更大的, 而且可以支持CPU执行store指令的存储器.
DRAM的存储单元
DRAM(Dynamic Random Access Memory)是一种目前广泛使用的存储器, 和SRAM相比, DRAM具有容量大, 成本低的特点. DRAM的存储单元通过一根晶体管和一个电容来存储1 bit, 其中晶体管充当开关的作用, 功能上相当于读写使能; 电容用于存储1 bit的信息, 当电容的电量大于一定的阈值, 就认为是1, 否则就认为是0. 可见, DRAM通过电的特性来存储信息, 因此属于易失存储器, 断电后DRAM中存储的信息将全部丢失. 反过来说, 系统上电时, DRAM中也不存在任何有效的数据.
不过, 电容具有漏电的特性, 如果不进行任何操作, 电容中的电量将不断下降, 1最终会变成0, 从而无法识别原来存储的数据是1还是0, 导致数据丢失. 为了避免这种情况, 必须对DRAM的存储单元定时进行刷新: DRAM控制器读出每一个存储单元中存放的信息, 若为1, 则重新写入该存储单元. 写入操作将使存储单元的电容重新恢复到高电量的状态, 使得在接下来的一段时间内, 都可以从该存储单元中读出1, 从而保持信息的存储.
可以看到, 写入DRAM存储单元的本质是对电容的充电和放电, 因此, 虽然DRAM的写入操作不如SRAM的写入那么快, 但综合考虑成本和容量等因素, DRAM的写入操作仍然适合用于支持CPU执行store指令.
如果不考虑存储阵列的组织结构, 读写的物理过程, 从功能上来说, DRAM颗粒和上文介绍的flash颗粒非常类似: 除了各种寄存器之外, 还能接收外部输入的命令进行操作.
与flash控制器类似, 向DRAM颗粒发送命令以驱动其工作的模块称为DRAM控制器. DRAM控制器需要将来自总线的事务请求翻译成DRAM颗粒的操作命令, 通过存储器总线将这些信息传递给DRAM颗粒. 此外, DRAM控制器还需要定期向DRAM颗粒发送刷新命令. 不过这也增加了DRAM控制器的设计复杂度: DRAM控制器必须精确地计算需要刷新的时机, 过多的刷新操作会降低读写命令的执行效率, 而过少的刷新操作将会导致数据丢失.
PSRAM颗粒
有一类DRAM颗粒在内部集成了刷新的逻辑, 称为PSRAM(Pseudo Static Random Access Memory)颗粒. PSRAM控制器无需实现刷新的功能, 也无需关心PSRAM颗粒的内部结构, 因此这种颗粒使用起来与SRAM很类似: 只需给出地址, 数据和读写命令, 就可以访问颗粒中的数据. 一个例子是型号为IS66WVS4M8ALL的PSRAM颗粒, 它能提供4MB的存储空间, 更多信息可参考相关的手册.
有了PSRAM, 我们就可以尝试让ysyxSoC向程序提供更大的可写内存区间. 与通过SPI协议访问flash颗粒类似, PSRAM颗粒也提供了SPI接口. 不过, 和flash不同, PSRAM一般作为系统的内存, 因此有必要提供更高效的访问方式.
通过SPI总线协议的升级版访问PSRAM颗粒
事实上, SPI协议存在一些升级版本, 可以提升master和slave间的通信效率. 基础的SPI协议是全双工的, 即master和slave可以同时分别通过MOSI和MISO发送消息. 但通常来说, master先向slave发送命令, slave在收到命令后才能处理, 然后才能把处理结果回复给master, 这个过程只需要半双工的信道即可满足.
Dual SPI协议利用了这一点, 可以将基础SPI协议中的MOSI和MISO同时用于其中一个方向的传输, 也即, Dual SPI协议可以在一个SCK时钟内单向传输2 bit. 因为MOSI和MISO的含义发生了变化, 因此在Dual SPI协议中, 它们的名称分别改为SIO0(Serial I/O 0)和SIO1.
为了与基础SPI协议的传输方式区别开来, slave通常会提供不同的命令来让master选择通过何种协议进行传输. 例如, 上文提到的型号为W25Q128JV的flash颗粒提供多种读命令:
- 提供
03h命令, 使用基础SPI协议进行读操作, 其命令, 地址, 数据都按1 bit传输. 通常把这三者的传输位宽用一个三元组(命令传输位宽-地址传输位宽-数据传输位宽)来表示, 例如, 基础SPI协议也记为(1-1-1). 以读出32位数据为例,03h命令需要执行8 + 24 + 32 = 64个SCK时钟. - 还提供
3Bh命令, 使用Dual SPI协议进行读操作, 其命令和地址按1 bit传输, 但数据按2 bit传输, 记为(1-1-2). 以读出32位数据为例,3Bh命令需要执行8 + 24 + 32/2 = 48个SCK时钟, 不过无论数据按多少位进行传输, 从flash存储阵列上读出数据总是需要一定的延迟, 因此3Bh命令在传输数据之前还需要额外等待8个SCK时钟, 即3Bh命令需要执行8 + 24 + 8(读延迟) + 32/2 = 56个SCK时钟. - 还提供
BBh命令, 使用Dual SPI协议进行读操作, 其命令按1 bit传输, 但地址和数据按2 bit传输, 记为(1-2-2). 以读出32位数据为例,BBh命令需要执行8 + 24/2 + 4(读延迟) + 32/2 = 40个SCK时钟.
进一步地, 还有Quad SPI协议(简称QSPI), 通过添加SIO2和SIO3两位新信号, 可以在一个SCK时钟内单向传输4 bit. 例如, 上文提到的型号为W25Q128JV的flash颗粒还提供另外两种基于QSPI协议的读命令:
- 提供
6Bh命令, 其命令和地址按1 bit传输, 但数据按4 bit传输, 记为(1-1-4). 以读出32位数据为例,6Bh命令需要执行8 + 24 + 8(读延迟) + 32/4 = 48个SCK时钟. - 还提供
EBh命令, 其命令按1 bit传输, 但地址和数据按4 bit传输, 记为(1-4-4). 以读出32位数据为例,EBh命令需要执行8 + 24/4 + 6(读延迟) + 32/4 = 28个SCK时钟.
不过, 上面的读命令中, 无论地址和数据部分按多少位进行传输, 命令部分都是按1 bit传输. 这是因为slave在解析出命令之后, 才知道后续的地址和数据应该使用何种协议进行传输, 因此命令部分仍然按照基础SPI协议来逐位进行传输. 此外, 虽然上述型号的flash颗粒支持多种传输方式, 但与flash颗粒相连的SPI master只能以基础SPI协议进行传输, 因此无法发出其他读命令.
ysyxSoC集成了PSRAM控制器的实现, 并将PSRAM存储空间映射到CPU的地址空间0x8000_0000~0x9fff_ffff. PSRAM控制器的代码位于ysyxSoC/perip/psram/efabless/目录下, 采用wishbone总线协议, 我们已经将其封装成APB总线协议 (见ysyxSoC/perip/psram/psram_top_apb.v), 并将其接入到ysyxSoC的APB Xbar中. PSRAM控制器会将接收到的总线事务翻译成发往PSRAM颗粒的命令. 我们选择模拟型号为IS66WVS4M8ALL的PSRAM颗粒, 它支持QSPI协议, 因此ysyxSoC集成的PSRAM控制器可以通过QSPI协议与PSRAM颗粒进行通信, 从而可以使用更高效的命令访问PSRAM. ysyxSoC已经将PSRAM颗粒与PSRAM控制器相连, 但未提供PSRAM颗粒相关的代码, 为了在ysyxSoC中使用PSRAM, 你还需要实现PSRAM颗粒的仿真行为模型.
实现PSRAM颗粒的仿真行为模型
你需要实现IS66WVS4M8ALL颗粒的仿真行为模型. 你只需要实现SPI Mode的Quad IO Read和Quad IO Write两种命令即可, 它们的命令编码分别为EBh和38h, PSRAM控制器也只会向PSRAM颗粒发送这两种命令.
具体地, 如果你选择Verilog, 你需要在ysyxSoC/perip/psram/psram.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/PSRAM.scala的psramChisel模块中实现相应代码, 并将ysyxSoC/src/SoC.scala中的Module(new psram)修改为实例化psramChisel模块.
一些说明如下:
- 端口
ce_n的含义与SPI总线协议中的SS相同, 低电平有效 - 端口
dio声明为inout类型, 再配合一个用于输出使能信号, 可实现三态逻辑, 在同一时刻可用于输入或输出, 用于实现信号的半双工传输- 在ASIC流程中, 需要显式实例化标准单元库中的三态逻辑单元, 不过此处我们仅在仿真环境中测试, 因此无需调用标准单元库
- 如果你使用Verilog, 可参考
ysyxSoC/perip/psram/psram_top_apb.v中qspi_dio的相关代码 - 如果你使用Chisel, 由于目前Chisel还不支持
Analog类型除连接外的其他操作, 因此我们已经在框架代码中实例化了一个TriStateBuf子模块, 它可以将dio分解成din和dout两个方向的UInt信号供后续使用
- 存储阵列只需要实现成一个字长为8 bit的二维数组, 无需关心其物理组织结构, 重点关注QSPI协议的实现即可. 此外, 因为PSRAM不是非易失存储器, 无需在仿真环境初始化时设置其内容, 因此可直接在Verilog代码中定义存储阵列, 亦可通过DPI-C访问在C++代码中定义的数组, 从而方便被mtrace追踪
- 手册中还有一个QPI Mode, 其含义与上文提到的QSPI不同, 目前可忽略
- 关于尾端和时钟相位等细节, 可RTFM参考相关手册, 或RTFSC参考PSRAM控制器的代码
- 为了正确实现PSRAM控制器和PSRAM颗粒的通信, 你无需修改PSRAM控制器的代码
实现后, 通过mem-test测试一小段PSRAM的访问(如4KB), 检查你的实现是否正确. 注意到目前flash已经提供了更大的存储空间来存放程序, 因此你可以在mem-test中调用printf()来帮助你输出调试信息, 尤其是可以输出一些和测试进度相关的信息, 从而得知测试是否正常进行中.
事实上, 在QSPI之上还有一种称为QPI的协议, 它还能进一步提升命令部分的传输效率, 即命令, 地址和数据都按4 bit传输, 记为(4-4-4). 不过为了兼容旧的SPI master, slave上电时一般处于基础SPI模式, 此时通过基础SPI协议通信. 如果slave支持QPI协议, 它将提供一个切换到QPI模式的命令, master可以发送该命令将slave切换到QPI模式, 然后使用QPI协议与其通信.
使用QPI协议访问PSRAM颗粒
尝试为PSRAM颗粒添加QPI模式以及进入QPI模式的命令, 然后修改PSRAM控制器的代码, 使其复位后先通过电路逻辑向PSRAM颗粒发送进入QPI模式的命令, 后续则使用QPI模式与PSRAM颗粒进行通信.
注意这个功能的添加对上层软件是透明的, 上层软件无需进行任何改动, 就能提升访问PSRAM的效率.
运行更大的程序
有了PSRAM的支持, 我们就可以尝试把数据段分配在PSRAM, 从而支持运行更大的程序.
在ysyxSoC上运行microbench
之前我们把数据段和堆区分配在8KB的SRAM中, 而运行microbench所需要的内存大于8KB, 因此有不少子项无法运行. 将数据段和堆区分配在4MB的PSRAM后, 你应该能看到microbench可以成功运行test规模的所有测试.
我们刚才运行microbench只是从流程上说明把数据段分配在PSRAM并无大碍, 但在运行更多程序之前, 我们最好先通过mem-test对4MB的PSRAM进行完整的测试. 不过, 如果要在仿真环境中通过mem-test完整测试这4MB存储空间的读写, 则需要花费很长的时间.
这是因为目前我们在flash上执行mem-test: 从flash中取出一条指令, 至少需要花费64个SCK时钟周期; 而SPI master又是通过分频的方式生成SCK时钟信号, 即使采用效率最高的二分频, 光是SPI传输过程, 就要花费至少128个CPU时钟周期; 再加上XIP状态机的控制开销, 从flash中取出一条指令, 前后需要花费大约150个CPU时钟周期.
由于循环和函数调用的存在, 程序中的大部分代码都要重复执行. 相比于让程序一直在flash中执行, 提前花一些时间将代码加载到一个访问效率比flash更高的存储器中, 然后让程序在后者中重复执行, 反而能有效提升程序的执行效率. 不过这个加载过程需要读出程序的指令, 然后将其写入到目标存储器中, 因此需要一个支持写操作的存储器. 目前PSRAM仍在测试中, 考虑到mem-test并不是很大, 我们可以尝试将mem-test加载到上文提到的8KB的SRAM中.
谁来进行这个加载操作呢? 我们肯定要在mem-test执行之前完成加载, 但又希望保持"NPC复位后从flash中取指"的特性, 不让仿真环境干涉太多, 从而使得这个加载操作也可以在真实的芯片中进行. 因此, 我们只好在NPC复位之后, 且mem-test真正执行之前, 利用这段间隙来进行加载, 不难想到, 那就是bootloader! 也即, 我们需要扩展bootloader的功能, 将程序的代码和数据全部加载到SRAM中, 然后跳转到SRAM执行.
完整测试PSRAM的访问
扩展bootloader的功能, 把mem-test完全加载到SRAM, 然后再执行mem-test. 一些提示如下:
- 你还需要将只读数据段一同加载到SRAM, 它可能会包含一些代码执行中所需要的数据, 例如跳转表等
- 如果你发现
mem-test的代码过多, 无法在SRAM中放下, 可以尝试使用编译选项-Os来指示gcc以代码大小为目标进行优化 - 代码加载的实现还需要处理若干你目前能理解的细节, 如果你忽略了它们, 那就在调试中学习吧, 毕竟将来的真实项目也是这样
之后, 让mem-test测试PSRAM的所有4MB存储空间, 你会发现mem-test的运行效率提高了不少, 可花费约10分钟完成测试.
SRAM的访问速度虽然快, 但其容量并不大, 无法存放大部分程序. 完整测试PSRAM的访问后, 我们也可以考虑让bootload将程序完全加载到PSRAM中, 从而提升程序执行的效率.
通过bootloader将程序加载到PSRAM中执行
你已经通过bootloader将mem-test加载到SRAM中了, 因此要将程序加载到PSRAM中并不难. 不过为了充分利用SRAM, 我们可以把栈分配在SRAM中, 来提升函数调用和访问局部变量的效率.
尝试执行microbench的test规模, 你会发现和在flash中执行相比, 将其加载到PSRAM后执行, 可以得到可观的性能提升.
在PSRAM上执行RT-Thread
目前PSRAM的容量已经足够运行RT-Thread了. 尝试通过bootloader将RT-Thread加载到PSRAM中执行.
如果程序较大, 那么bootloader加载程序的过程也会较长, 因为bootloader本身是在flash中执行的. 同样地, 我们能否将"bootloader加载程序"的代码先加载到访问效率更高的存储器中, 然后再执行"bootloader加载程序"的功能呢? 这其实是bootloader的多级加载过程. 为了方便区分, 我们可以将整个bootloader的工作拆分成 FSBL(first stage bootloader)和SSBL(second stage bootloader)两部分. 系统上电时, FSBL, SSBL和需要运行的程序都位于flash中; 首先执行的是FSBL, 它负责将SSBL从flash加载到其他存储器, 然后跳转到SSBL执行; 然后SSBL负责将接下来需要运行的程序从flash加载到PSRAM中, 然后跳转到程序并执行. 事实上, SSBL的代码并不大, 因此我们可以让FSBL将SSBL加载到SRAM中执行, 从而让SSBL执行得更快.
实现bootloader的二级加载过程
按照上述功能实现FSBL和SSBL. 为了得知SSBL在flash中的范围, 你可能需要将SSBL单独放在一个节中, 具体可以参考start.S中的相关代码.
此外, 因为bootloader把加载工作分成多个阶段, 你还需要额外考虑目标对象在当前阶段中是否可访问.
SDRAM颗粒的内部结构
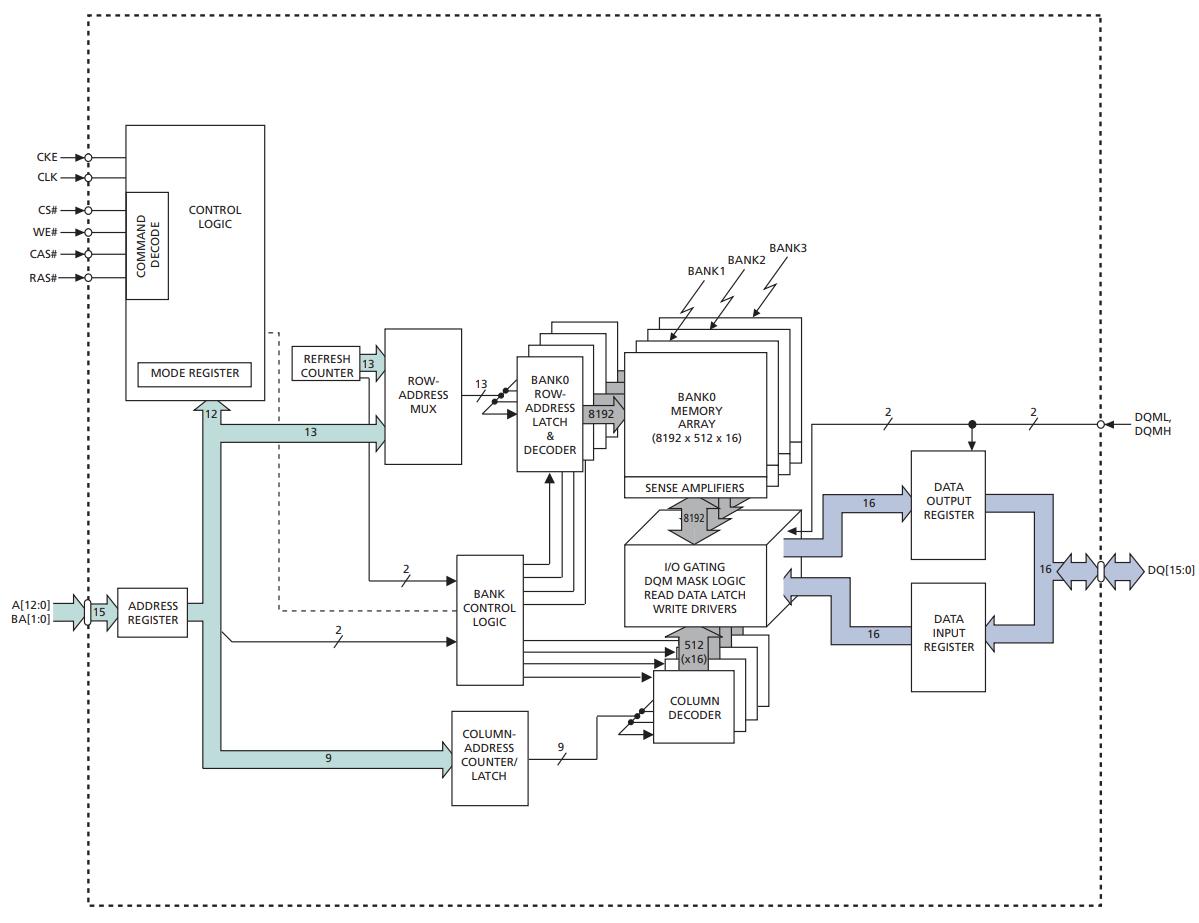
如果想要进一步提升访问DRAM颗粒的效率, 就要考虑将控制器和颗粒之间的串行总线改成并行总线了. 例如, 型号为MT48LC16M16A2的DRAM颗粒内部结构如下图所示. 该颗粒的引脚有39位, 分别包括:
CLK,CKE- 时钟信号和时钟使能信号CS#,WE#,CAS#,#RAS- 命令信号BA[1:0]- 存储体地址A[12:0]- 地址DQ[15:0]- 数据DQM[1:0]- 数据掩码, 下图中的命名采用DQML和DQMH
与SPI协议中采用分频输出的SCK不同, 这里的时钟信号CLK通常由DRAM控制器的时钟直接驱动, 这类DRAM称为同步DRAM, 即SDRAM(Synchronous Dynamic Random Access Memory). SDRAM颗粒已经成为当前主流的内存颗粒, 最早商用的SDRAM颗粒于1992年发售, 属于SDR SDRAM(Single Date Rate SDRAM), 表示一个时钟传输一次数据, 上图展示的型号为MT48LC16M16A2的颗粒, 就属于SDR SDRAM颗粒; 1997年开始出现了DDR SDRAM(Double Data Rate SDRAM), 它可以分别在时钟的上升沿和下降沿传输数据, 因此提升了数据传输带宽; 此后依次出现了DDR2, DDR3, DDR4, DDR5, 它们均通过不同技术进一步提升数据传输带宽. 与同步DRAM相对, 还有异步DRAM(Asynchronous DRAM), 它的总线信号中没有时钟. 目前异步DRAM基本上被SDRAM替代, 因此今天讨论DRAM时, 几乎都指代SDRAM.
和PSRAM颗粒的SPI总线接口不同, 传统DRAM颗粒的引脚中包含了存储体地址等信息, 这要求DRAM控制器了解DRAM颗粒中存储阵列的内部组织结构, 才能知道应该给地址相关的引脚传递什么信息.
DRAM颗粒的存储阵列是一个多维结构, 从逻辑上看由若干个矩阵组成, 一个矩阵又称一个存储体(memory bank). 存储体中的一个矩阵元素是若干个存储单元, 每个存储单元包含一根晶体管和一个电容, 用于存储1 bit信息. 需要通过行地址(row address)和列地址(column address)共同指定存储体中的一个矩阵元素. 例如, 上述DRAM颗粒中有4个存储体, 每个存储体中有8192行, 每行有512列, 存储体中的一个矩阵元素有16个存储单元, 因此该DRAM颗粒的容量为4 * 8192 * 512 * 16 = 256Mb = 32MB.
读出时, 先根据存储体编号选择一个目标存储体. 然后通过行地址激活(active)目标存储体中的一行: 目标存储体中的读出放大器(sence amplifier)会检测这一行所有存储单元中的电量, 从而得知每个存储单元存放的是1还是0. 一个读出放大器主要由一对交叉配对反相器构成, 因此可以存储信息, 故存储体中的读出放大器也称行缓冲(row buffer), 可以存储一行信息. 之后, 再根据列地址从目标存储体的行缓冲中各选出数据, 作为读出的结果输出到DRAM颗粒芯片的外部. 写入时, 先将需要写入的数据写到行缓冲中的相应位置, 然后对相应存储单元中的电容进行充电或放电操作, 从而将行缓冲中的内容转移到存储单元中. 如果要访问另一行的数据, 在激活另一行之前, 还需要先将已激活的当前行的信息写回存储单元, 这个过程称为预充电(precharge).
DRAM颗粒的物理实现
考虑到物理实现的限制, 走线过长会引入较大延迟. 因此从物理实现的角度来看, DRAM颗粒的一个存储体还会进一步划分成多个子阵列(subarray). 不过这些子阵列的结构和访问方式对颗粒外部是透明的, DRAM控制器向DRAM颗粒发送命令时无需关心. 感兴趣的同学可以阅读这篇文章进一步了解DRAM颗粒内部的物理结构.
理解了DRAM颗粒的内部组织结构后, 我们就可以来梳理DRAM颗粒的命令了. 不同版本的SDRAM命令稍有不同, 下表列出了SDR SDRAM的命令:
| CS# | RAS# | CAS# | WE# | 命令名称 | 命令含义 |
|---|---|---|---|---|---|
| 1 | X | X | X | COMMAND INHIBIT | 无命令 |
| 0 | 1 | 1 | 1 | NO OPERATION | NOP |
| 0 | 0 | 1 | 1 | ACTIVE | 激活目标存储体的一行 |
| 0 | 1 | 0 | 1 | READ | 读出目标存储体的一列 |
| 0 | 1 | 0 | 0 | WRITE | 写入目标存储体的一列 |
| 0 | 1 | 1 | 0 | BURST TERMINATE | 停止当前的突发传输 |
| 0 | 0 | 1 | 0 | PRECHARGE | 关闭存储体中已激活的行(预充电) |
| 0 | 0 | 0 | 1 | AUTO REFRESH | 刷新 |
| 0 | 0 | 0 | 0 | LOAD MODE REGISTER | 设置Mode寄存器 |
上述命令涉及"突发传输"(burst transfer)的概念, 它指在一次事务(transaction)中包含多次连续的数据传输, 一次数据传输称为一个"节拍"(beat). 以读取为例, 从DRAM颗粒接收到READ命令, 到读出存储阵列中的数据并传送到DQ总线上, 一般需要花费若干周期, 这个延迟称为CAS latency(有的教材翻译成CAS潜伏期). 以上文的MT48LC16M16A2型号为例, 根据工作频率的不同, CAS latency可为1~3周期, 即从收到READ命令, 到读出16 bit数据到DQ总线上, 有1~3周期的延迟. 假设CAS latency为2周期, 如果不采用突发传输, 读出8字节需要发送4次READ命令, 共花费12周期; 如果采用突发传输, 则只需发送1次READ命令, 花费6周期.
// normal
1 1 1 1 1 1 1 1 1 1 1 1
|---|---|---|---|---|---|---|---|---|---|---|---|
^ | ^ | ^ | ^ |
| v | v | v | v
READ data READ data READ data READ data
// burst
1 1 1 1 1 1
|---|---|---|---|---|---|
^ | | | |
| v v v v
READ 1st 2nd 3rd 4th
WRITE命令也支持突发传输, 也即, 若要写入8字节, 可以在发出WRITE命令后紧接着的3个周期内连续传输需要写入的数据. 至于一次突发传输的事务包含多少个节拍, 可以通过Mode寄存器来设置. Mode寄存器还可以设置CAS latency等参数.
ysyxSoC集成了SDR SDRAM控制器(下文简称SDRAM控制器)的实现, 并将SDRAM存储空间映射到CPU的地址空间0xa000_0000~0xbfff_ffff. SDRAM控制器的代码位于ysyxSoC/perip/sdram/core_sdram_axi4/目录下, 它采用AXI4总线协议. 为了方便初期的测试, 我们将其核心部分ysyxSoC/perip/sdram/core_sdram_axi4/sdram_axi4_core.v 封装成APB总线协议(见ysyxSoC/perip/sdram/sdram_top_apb.v), 并将其接入到ysyxSoC的APB Xbar中. SDRAM控制器会将接收到的总线事务翻译成发往SDRAM颗粒的命令, 我们选择模拟型号为MT48LC16M16A2的SDRAM颗粒. ysyxSoC已经将SDRAM颗粒与SDRAM控制器相连, 但未提供SDRAM颗粒相关的代码, 为了在ysyxSoC中使用SDRAM, 你还需要实现SDRAM颗粒的仿真行为模型.
实现SDRAM颗粒的仿真行为模型
你需要实现MT48LC16M16A2颗粒的仿真行为模型. 具体地, 你需要实现SDRAM控制器会发送的命令, 其中PRECHARGE和AUTO REFRESH命令与存储单元的电气特性相关, 在仿真环境中不必考虑, 因此可以将其实现成NOP. 此外, Mode寄存器只需要实现CAS Latency和Burst Length, 其他字段可忽略.
具体地, 如果你选择Verilog, 你需要在ysyxSoC/perip/sdram/sdram.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/SDRAM.scala的sdramChisel模块中实现相应代码, 并将ysyxSoC/src/SoC.scala中的Module(new sdram)修改为实例化sdramChisel模块.
其他细节请RTFM参考相关手册, 或RTFSC参考SDRAM控制器的代码. 为了正确实现SDRAM控制器和SDRAM颗粒的通信, 你无需修改SDRAM控制器的代码
实现后, 通过mem-test测试一小段SDRAM的访问(如4KB), 检查你的实现是否正确.
完整测试SDRAM的访问
在进一步将程序加载到SDRAM中执行之前, 我们还是先通过mem-test测试对上述SDRAM颗粒所有存储空间的访问. 完成这个测试需要花费约1小时.
将程序加载到SDRAM中执行
让bootloader将程序加载到SDRAM中并执行. 在这之后, 尝试在SDRAM上执行microbench和RT-Thread.
SDRAM颗粒的扩展
上文提到, MT48LC16M16A2型号的SDR SDRAM颗粒的容量为32MB. 但如今的内存条动辄就4GB, 这是如何做到的呢? 即使如今主流的内存条采用更先进的工艺, 单个内存颗粒的容量有所提升, 但也并非仅靠一个内存颗粒就能达到4GB. 事实上, 这是通过多个内存颗粒在一定维度上进行组合扩展来实现的. 如果你观察过内存条的结构, 你会发现一根内存条上有多个内存颗粒, 而内存条就是一块特殊的PCB板: 它以标准的尺寸规格集成多个内存颗粒, 并且采用DIMM接口, 使其可以插入主板的内存槽中.
我们知道, 如果不考虑物理组织结构, 存储器就是一个二维矩阵, 每行存储一个字, 行号即地址. 从这个角度看, 多个颗粒的扩展无非就是两个维度的扩展: 一个维度是让一个地址存储更多位的信息, 称为位扩展; 另一个维度是增加地址的范围, 称为字扩展.
位扩展的思想是, 不同颗粒同时从相同的地址中读出数据, 这不仅提升了存储器的容量, 而且还提升了访存带宽. 如果颗粒的字长(即DQ信号的位宽)小于总线的数据位宽, 位扩展能够明显提升数据传输的效率. 例如, 对于64位的CPU, 总线的数据位宽通常不低于64位, 用4个字长是16位的MT48LC16M16A2颗粒, 可以在一个CAS latency之后就读出64位, 效率比突发传输还高:
1 1 1
|---|---|---|
^ |
| v
READ data[15:0] (chip0)
1 1 1
|---|---|---|
^ |
| v
READ data[31:16] (chip1)
1 1 1
|---|---|---|
^ |
| v
READ data[47:32] (chip2)
1 1 1
|---|---|---|
^ |
| v
READ data[63:48] (chip3)
另一个例子是型号为MTA9ASF51272PZ的DDR4 SDRAM内存条, 内存条上的颗粒字长是8位, 但通过8个颗粒进行位扩展, 一次可以读写64位.
将SDRAM控制器的数据位宽扩展到32位
实例化2个SDRAM颗粒的子模块, 模拟对2个SDRAM颗粒进行位扩展的场景. 为此, 你需要修改以下内容:
- SDRAM总线接口中部分信号的位宽
- 如果你使用Chisel, 你可以直接修改
SDRAMIO的定义 - 如果你使用Verilog
- 如果你不打算参加流片, 你可以直接修改
ysyxSoC/build/ysyxSoCFull.v中的相应信号位宽 - 如果你打算参加流片, 你不能直接修改
ysyxSoC/build/ysyxSoCFull.v, 否则流片的自动测试流程将会覆盖你对ysyxSoC/build/ysyxSoCFull.v的修改; 相反, 你可以在ysyxSoC/Makefile中添加一些命令, 这些命令可以在生成ysyxSoC/build/ysyxSoCFull.v后自动修改信号的位宽
- 如果你不打算参加流片, 你可以直接修改
- 如果你使用Chisel, 你可以直接修改
- SDRAM控制器的内部实现
实现位扩展后, 就不需要通过突发传输模式来访问SDRAM颗粒了, 经过一个CAS latency后, 就可以从扩展后的颗粒中读出32位数据. 尝试运行一些benchmark, 对比位扩展前后的性能变化.
不过, 这些性能提升的得来并不是免费的, 位扩展要求DQ的引脚数量线性增长, 对于一些关注成本的芯片来说, 就需要精打细算了. 另外, 即使不关注成本, 位扩展带来的性能提升也会受限于系统中的其他因素, 例如总线的数据位宽: 如果总线的一次传输最多只有64位, 那么即使将内存颗粒的字长扩展到512位, 整体上也不会带来可观的收益, 就像水管的流量受限于最窄的片段一样.
另一个维度是字扩展, 其思想是将不同的地址分布到不同的颗粒上, 从而提升访存容量. 例如, 我们可以使用2个32MB的MT48LC16M16A2颗粒, 通过字扩展形成容量为64MB的内存. 上述字扩展只需要在存储器总线上添加1位地址, 引脚数量的增长与存储容量呈对数关系, 和位扩展相比开销并不大. 但从直觉上看, 字扩展不能直接提升访存带宽, 我们会在后面章节中继续讨论这个问题.
对SDRAM控制器进行字扩展
实例化总计4个SDRAM颗粒的子模块, 其中两对SDRAM颗粒之间进行位扩展, 再对位扩展之后的结果进行字扩展. 你还需要修改SDRAM总线接口和控制器的内部实现.
实现后, 通过mem-test测试扩展后的所有存储空间. 完成这个测试需要花费数小时.
需要注意的是, 你的修改可能会导致SDRAM控制器无法满足SDRAM颗粒的电气特性, 导致其无法在真实的SDRAM颗粒上运行. 不过要测试SDRAM的电气特性需要更复杂的仿真环境. 为了简化, 我们不要求修改后的SDRAM控制器在真实的板卡上正确运行.
接入更多外设
上面的工作全部都是围绕TRM开展的, 最后我们来看看如何支持IOE.
GPIO
首先我们来添加GPIO的支持. GPIO算是最简单的外设了, 其本质就是一根连接芯片内外的导线, 显然它需要占用芯片的引脚. 通过GPIO, 芯片可以将内部的信号直接输出到芯片外部, 用来驱动一些简单的设备, 例如板卡上的LED灯; 芯片也可以通过GPIO获取外部的一些简单状态, 如板卡上的拨码开关, 按钮等状态.
显然, CPU上运行的软件无法直接访问一个芯片引脚, 同样需要GPIO控制器来为GPIO的功能提供设备寄存器的抽象. 不过对GPIO控制器来说, 这些设备寄存器的功能非常简单, 只需要用电路上的寄存器来存放相应引脚的状态即可. 具体地, 对于输出引脚, 其状态由寄存器中存放的某一位直接驱动; 而对于输入引脚, 它决定了寄存器中某一位的状态.
ysyxSoC集成了一个APB总线接口的GPIO控制器, 并将其映射到CPU的地址空间0x1000_2000~0x1000_200f. 我们只给GPIO控制器分配了16字节的地址空间, 最多支持128个引脚, 通常来说已经足够使用了. 为了看到GPIO的效果, 我们将重新接入预学习阶段中你曾经接触过的NVBoard项目. 考虑到NVBoard中提供的外设, 适合GPIO使用的包括16个LED灯, 16个拨码开关, 以及8个7段数码管. 因此, 我们对GPIO控制器的寄存器空间作如下分配:
| 地址 | 作用 |
|---|---|
0x0 | 16位数据, 分别驱动16个LED灯 |
0x4 | 16位数据, 分别获得16个拨码开关的状态 |
0x8 | 32位数据, 其中每4位驱动1个7段数码管 |
0xc | 保留 |
不过ysyxSoC没有提供GPIO控制器内部的具体实现, 我们将它作为作业留给大家.
更新NVBoard
我们在2024/01/11 01:00:00将NVBoard更新到1.0版本, 不仅增加了UART功能, 还大幅提升了处理性能. 后续的部分实验内容将要求大家使用NVBoard功能, 如果你在上述时间之前获得NVBoard的代码, 你可以通过以下命令获取新版本:
cd nvboard
git pull origin master
为了运行新版本的NVBoard, 你可能需要先清除一些旧的编译结果.
通过程序实现NVBoard上的流水灯效果
你需要进行以下工作:
- 在GPIO控制器中实现用于驱动LED灯的寄存器. 具体地, 如果你选择Verilog, 你需要在
ysyxSoC/perip/gpio/gpio_top_apb.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/GPIO.scala的gpioChisel模块中实现相应代码, 并将ysyxSoC/src/GPIO.scala中的Module(new gpio_top_apb)修改为实例化gpioChisel模块. - 接入NVBoard, 将顶层模块
ysyxSoCFull中的GPIO输出引脚绑定到LED灯 - 编写测试程序, 隔一段时间往上述寄存器写入数据, 从而实现流水灯的效果
和预学习阶段不同, 这时的流水灯不再是由硬件电路直接控制, 而是由软件控制, 而且你已经了解其中的所有细节了.
通过程序读入拨码开关的状态
与LED灯类似, 让程序读出读出拨码开关的状态. 你可以在程序中设置一个16位二进制的密码, 程序一开始启动时将不断查询拨码开关的状态, 只有当拨码开关的状态与上述密码一致, 程序才继续执行.
通过程序在7段数码管上展示学号
在学号CSR中读出学号, 并将其转化成8个十六进制数, 分别用于驱动8个7段数码管.
UART
我们之前已经通过UART16550控制器的帮助下测试了串口的输出功能, 但之前串口的发送端仅仅是通过UART16550控制器代码中的$write系统任务来输出, 并没有涉及将字符进行编码并通过线缆串行传输到接收端的过程. NVBoard集成了一个串口终端, 有了NVBoard, 我们就可以来体会这个过程了!
NVBoard中的串口终端很简单, 它只支持8N1的串口传输配置. 至于波特率, 因为NVBoard中没有时钟频率的概念, 因此采用除数的方式来描述, 也即, 传输数据时一个比特需要维持多少个周期. NVBoard中的这个除数不支持运行时配置, 但可以通过修改代码来调整. 你可以在nvboard/src/uart.cpp的UART构造函数中进行修改, 具体有两种方式:
- 修改
divisor成员的初值 - 调用
set_divisor()函数来设置
将串口的TX引脚接入NVBoard
你只需要修改NVBoard约束文件, 即可将串口的TX引脚绑定到NVBoard的串口终端上. 关于如何绑定, 你可以参考NVBoard提供的示例. 由于串口控制器已经接入ysyxSoC了, 你无需再修改RTL代码.
成功绑定引脚后, 根据实际情况配置NVBoard中UART的除数. 注意NVBoard中UART的除数和UART16550中除数寄存器中的除数不完全相同, 它们之间存在一定的关系, 你需要通过RTFSC或者RTFM梳理清楚.
然后, 重新运行任意带串口输出的测试程序, 你将看到串口输出的内容不仅出现在命令行终端中, 还会出现在NVBoard右上角的串口终端中.
NVBoard还支持串口的输入功能, 接入NVBoard之后, 就可以来测试之前不方便测试的串口输入功能了. 绑定引脚的工作并不难, 但我们还需要考虑上层的软件如何使用. 具体地, 你还需要在riscv32e-ysyxsoc的IOE中添加抽象寄存器UART_RX的功能: 从串口设备中读出一个字符, 若无字符, 则返回0xff.
bug修复
我们修复了am-tests的按键测试中和实现定义相关的问题. 如果你在2024/01/11 00:00:00之前获取am-kernels的代码, 请获取新版代码:
cd am-kernels
git pull origin master
通过NVBoard测试串口的输入功能
绑定串口的RX引脚并在IOE中添加上述抽象寄存器后, 运行am-tests中的按键测试, 测试其能否通过UART的RX端口获得按键信息.
关于如何在NVBoard中通过UART的RX端口进行输入, 你可以参考NVBoard提供的示例. 此外, 你可能还需要在IOE中实现一些功能, 具体可以RTFSC.
在IOE中添加UART RX的相关功能之后, 我们就可以来尝试通过串口在RT-Thread中键入命令了.
bug修复
我们修复了rt-thread-am中输入无效命令时卡死的bug, 同时让msh通过轮询方式获取按键. 如果你在2024/01/11 01:50:00之前获取rt-thread-am的代码, 请获取新版代码:
cd rt-thread-am
git pull origin master
获取新版代码后, 你还需要重新生成一些配置文件:
cd rt-thread-am/bsp/abstract-machine
rm rtconfig.h
make init
之后重新编译运行即可.
通过串口在RT-Thread中键入命令
为此, 我们需要让RT-Thread调用刚才实现的IOE功能. 修改BSP中的串口输入功能, 使其在读完内置字符串后, 通过IOE从UART RX中获取字符.
PS/2键盘
你已经在预学习阶段中做过键盘相关的数字电路实验了, 现在我们来将之前的实验内容接入到ysyxSoC中. ysyxSoC集成了一个APB总线接口的PS2键盘控制器, 并将其映射到CPU的地址空间0x1001_1000~0x1001_1007. 不过ysyxSoC没有提供PS2键盘控制器内部的具体实现, 你需要实现它. 我们对PS2控制器的寄存器空间作如下分配:
| 地址 | 作用 |
|---|---|
0x0 | 8位数据, 读出键盘扫描码, 如无按键信息, 则读出0 |
| 其他 | 保留 |
让riscv32e-ysyxSoC从NVBoard读取键盘按键
你需要进行以下工作:
- 实现PS2键盘控制器. 如果你选择Verilog, 你需要在
ysyxSoC/perip/ps2/ps2_top_apb.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/Keyboard.scala的ps2Chisel模块中实现相应代码, 并将ysyxSoC/src/Keyboard.scala中的Module(new ps2_top_apb)修改为实例化ps2Chisel模块.- 相比于让键盘控制器进行按键扫描码到其他编码的翻译, 我们更推荐让软件获取按键扫描码并进行翻译: 这不仅降低了硬件设计的复杂度, 还提升了灵活性
- 接入NVBoard, 绑定相关引脚
- 在AM IOE中添加代码, 从PS2键盘控制器中读出按键信息, 并将其翻译成AM定义的键盘码
- 键盘扫描码可以参考数字电路实验的相关信息
- 注意部分按键的扫描码包含扩展码, 如
PAGEUP, 你还需要正确识别它们
实现后, 运行am-tests中的按键测试, 检查你的实现是否正确.
VGA
你应该在预学习阶段中看到过NVBoard中的VGA展示效果, 现在我们让程序借助ysyxSoC将像素信息输出到NVBoard中. ysyxSoC集成了一个APB总线接口的VGA控制器, 并将其映射到CPU的地址空间0x2100_0000~0x211f_ffff. 这段地址空间其实是帧缓冲, 程序往其中写入像素信息, 即可在输出到NVBoard的VGA区域. NVBoard提供的VGA屏幕分辨率是640x480. 不过ysyxSoC没有提供VGA控制器内部的具体实现, 你需要实现它.
复习VGA的工作原理
如果你在预学习阶段的数字电路实验中没有接触过VGA的相关内容, 我们建议你先完成相关的实验内容, 从而理解VGA的工作原理, 否则你可能会在设计VGA控制器的时候遇到困难.
让riscv32e-ysyxSoC将像素信息输出到NVBoard
你需要进行以下工作:
- 实现VGA控制器, 它将不断地将帧缓冲的内容通过VGA的物理接口输出到屏幕上. 如果你选择Verilog, 你需要在
ysyxSoC/perip/vga/vga_top_apb.v中实现相应代码; 如果你选择Chisel, 你需要在ysyxSoC/src/device/VGA.scala的vgaChisel模块中实现相应代码, 并将ysyxSoC/src/VGA.scala中的Module(new vga_top_apb)修改为实例化vgaChisel模块.- 关于帧缓冲, 目前你可以暂时使用SRAM等简单存储器的方式来实现. 但需要注意, 在真实情况中, 这种实现方案的成本较高: 以上文提到的
640x480分辨率为例, 如果每个像素占4字节, 将需要1.17MB的SRAM, 这将占用不少的流片面积
- 关于帧缓冲, 目前你可以暂时使用SRAM等简单存储器的方式来实现. 但需要注意, 在真实情况中, 这种实现方案的成本较高: 以上文提到的
- 接入NVBoard, 绑定相关引脚
- 在AM IOE中添加代码, 将像素信息写入VGA控制器的帧缓冲中
- 由于NVBoard提供的VGA机制是自动刷新的, 因此无需实现AM中的画面同步功能
实现后, 运行am-tests中的画面测试, 检查你的实现是否正确.
更实际的帧缓冲实现方案
通常, 帧缓冲一般是在内存中分配, 通过配置VGA控制器中的部分寄存器, 可以让VGA控制器从内存中读取像素信息.
思考一下, 如果在当前的ysyxSoC配置中将帧缓冲分配到内存中, 可能会造成什么问题?
通过NVBoard展示游戏
尝试在NVBoard上运行打字游戏和超级玛丽等游戏. 当然, 这应该会非常卡, 我们后续的工作就是在微结构层次优化系统的性能.
在RT-Thread上运行AM程序
接入上述设备后, 我们可以在RT-Thread上运行其他AM程序, 从而形成一个完整的SoC计算机系统!
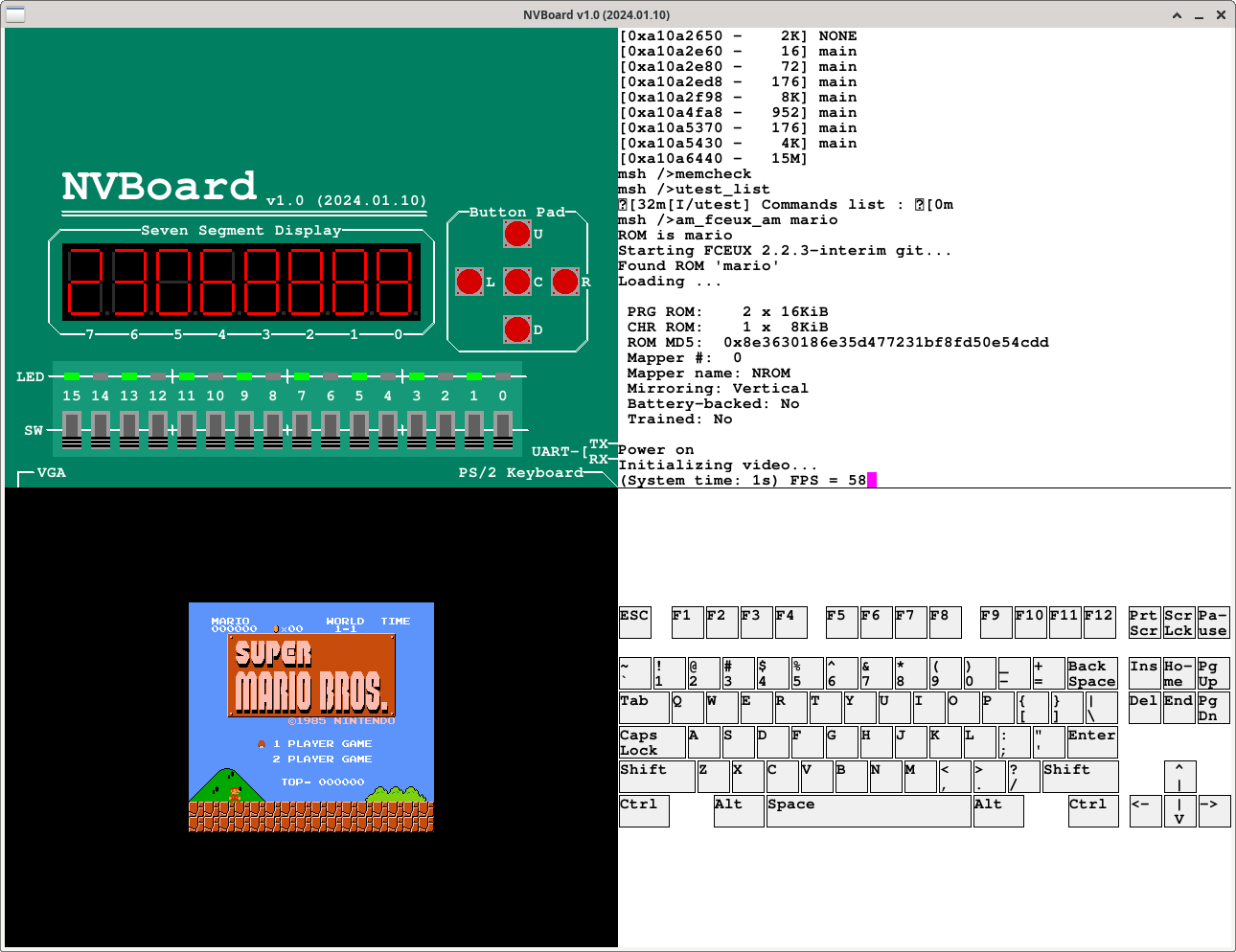
- 最上层是应用程序, 如超级玛丽, 它们以线程的方式在RT-Thread中运行
- RT-Thread提供若干资源的管理, 包括物理内存, 线程等
- RT-Thread还能管理很多资源, 如文件等, 目前我们的计算机系统暂不使用
- AM运行时环境提供TRM, IOE和CTE的功能抽象, 以支持RT-Thread在裸机上的运行
- RISC-V指令集提供具体的指令, MMIO机制和异常处理机制, 用于实现AM的TRM, IOE和CTE等具体功能
- NPC实现了RISC-V指令集的功能
- ysyxSoC集成了NPC, 使得NPC通过SoC中的总线与各种设备控制器通信
- NVBoard模拟了开发板的功能, 提供设备的物理实现, 并通过引脚与设备控制器交互
更新RT-Thread
我们在2024/01/18 20:00:00为RT-Thread添加了集成其他AM程序的功能. 如果你在上述时间前之前获取rt-thread-am的代码, 请获取新版代码:
cd rt-thread-am
git pull origin master
通过RT-Thread运行其他AM程序
参考PA4阶段1中的选做任务"在RT-Thread上运行AM程序", 尝试在riscv32e-ysyxsoc中通过RT-Thread启动超级玛丽等其他AM程序.
ChipLink - 芯片间的总线协议
上面的设备控制器都位于同一个SoC中, 因此会占用一定的流片面积. 如果设备控制器比较复杂(如现代DDR控制器), 将会花费不少流片成本. 事实上, 我们可以将总线延伸到芯片外部: 两个芯片可以在遵循同一套通信协议的情况下互相通信. 这样, 我们设计的芯片就可以访问其他芯片成品上的设备, 而后者一方面不占用我们的流片面积, 从而节省流片成本, 另一方面也可以降低验证的复杂度和流片风险, 毕竟芯片成品上的功能已经经过较充分的验证.
如果对端芯片是个FPGA, 我们还能获得灵活的扩展能力: 只需要将设备控制器烧录到FPGA中, 芯片就可以通过片间总线协议访问这些设备. 即使设备控制器有bug也不会带来灾难性的后果, 只需要在修复bug后重新烧录到FPGA中即可.
不过, 这些接口是要占用芯片引脚的. 考虑地址位宽和数据位宽均为32位的AXI总线, araddr, awaddr, rdata和wdata这几个信号就占用了128个引脚, 加上各种控制信号, 总计约150个引脚; 若数据位宽是64位, 则总计需要占用200个以上的引脚. 因此, 如果我们直接将AXI总线连到片外, 很可能需要采用较昂贵的封装方案, 这就违背了节省成本的初衷.
如果想通过更少的引脚将AXI请求发送到片外, 就只能对引脚进行分时复用了: 通过对AXI请求的信号进行分解, 每次传输其中的一部分, 通过多个周期来传输一个完整的AXI请求. 例如, 如果只用32个引脚, 那么我们可以约定, 在T0时刻先传输32位的写地址, 在T1时刻传输32位的写数据, 在T2时刻传输其他控制信号. 如果对端的芯片也遵循相同的约定, 它就可以按照约定, 将这3个周期从32个引脚上收到的信息重新组合成一个AXI的写请求, 从而实现了通过3个周期将一个AXI写请求传送到另一个芯片上的效果.
这样的约定, 其实就是一套芯片间的总线协议, 它约定了通过分时复用将AXI请求传输到片外的各种细节. 为了方便描述, 我们将片间的总线协议称为外层协议, 将被分解传输的总线协议称为内层协议. 例如, 上述场景中AXI就是片间传输过程中的内层协议. 当然, 内层协议不一定是AXI, 也可以对其他协议的请求进行分解并传输.
例如, 片间总线协议ChipLink可以将TileLink总线协议作为内层协议进行片间传输. 和AXI类似, TileLink也是全双工的, 也即发送方和接收方可以同时在信道上传输信息. 因此, ChipLink也被设计成全双工, 单个方向除了32个数据信号之外, 还有时钟, 复位和有效信号, 标准的ChipLink协议需要占用70个引脚, 比单独将内层协议TileLink传输到片外所占用的引脚数少得多.
事实上, 还可以通过减少数据信号的位宽来进一步减少ChipLink占用引脚的数量. 例如, 当数据位宽减少到8位时, ChipLink协议只需要占用22个引脚. 不过这需要付出传输带宽的代价: 一个内层协议请求的传输需要花费更多周期了, 因此单位时间内传输的有效数据量也会随之降低. 如果使用场景对带宽的需求不大, 可以通过这种方式节约芯片封装的成本.
ChipLink提供了开源的实现, 不过它的内层协议只支持TileLink, 但我们可以借助rocket-chip项目中的转接桥, 先将AXI请求转成TileLink请求, 然后通过ChipLink协议将TileLink请求传输到对端芯片, 对端芯片根据ChipLink协议组合出TileLink请求后, 再通过转接桥将TileLink请求转换回AXI请求, 从而实现了AXI请求的片间传输.
ysyxSoC集成了上述ChipLink的开源实现, 并模拟了通过ChipLink连接对端FPGA芯片的场景, 模拟的对端FPGA芯片中包含一个大小为1GB的存储器, ysyxSoC将这段空间映射到CPU的地址空间0xc000_0000~0xffff_ffff. 在实际的使用中, 这段地址空间中包含什么设备, 是可编程的, 也即, 我们可以充分利用FPGA的可编程性, 通过更新FPGA的比特流文件, 将不同的设备接入到这段地址空间中.
通过ChipLink访问对端芯片的资源
ysyxSoC默认未打开ChipLink, 因此你需要在ysyxSoC/src/Top.scala的Config对象中 将hasChipLink变量修改为true, 重新生成ysySoCFull.v并仿真即可.
不过ChipLink的代码要求仿真顶层的复位信号需要维持至少10个周期, 你需要检查你的仿真代码是否符合这个条件.
打开ChipLink后, 通过mem-test对上述地址空间进行测试. 由于测试的侧重点是检查NPC是否能通过ChipLink访问对端资源, 因此我们不必测试整个地址空间, 只需要测试一小段存储空间的访问(如4KB)即可.
由于ChipLink的实现较复杂, 添加ChipLink后将生成较多Verilog代码, 从而使仿真效率明显降低. 因此后续实验内容不要求你在打开ChipLink的情况下进行. 通过当前测试后, 你可以关闭ChipLink.