Time-sharing multitasking
The multiprogramming successfully implemented concurrent execution of tasks, but this concurrency is not necessarily fair. If a process does not trigger I/O operations for a long time, the multiprogramming system will not actively switch control to other processes, so other processes will not have the opportunity to run.
Imagine that when you are playing games, Windows suddenly performs an automatic update in the background, and your teammates call you asking why you keep disconnecting, you will definitely be very upset. Therefore, the multiprogramming system is still more used in batch processing scenarios. It can ensure that the CPU is fully loaded, but it is not suitable for interactive scenarios.
If it is to be used in interactive scenarios, the system needs to switch back and forth between all processes at a certain frequency to ensure that each process can get a timely response, this is time-sharing multitasking.
From the perspective of triggering context switching, time-sharing multitasking can be divided into two categories. The first is cooperative multitasking, which works based on a convention: user processes periodically voluntarily relinquish control of the CPU, allowing other processes to run. This requires the operating system to provide a special system call, which is the SYS_yield we implemented in PA3. The seemingly useless SYS_yield in PA3 is actually the cornerstone of context switching in a cooperative multitasking operating system.
It is called "cooperative" because this mechanism requires all processes to cooperate together and jointly abide by this convention for the entire system to work correctly. Some simple embedded operating systems or real-time operating systems adopt cooperative multitasking because there are only a few fixed programs running on these systems, and it is not difficult for them to jointly abide by the convention to relinquish the CPU.
But imagine, in a multi-user operating system, the source of running programs is unpredictable. If there is a malicious process that intentionally does not follow this convention and does not call SYS_yield, or unintentionally falls into an infinite loop, the entire system will be monopolized by this process. Some ancient versions of Windows adopted a cooperative multitasking design, and the operating system was often brought down by some buggy programs.
The reason why cooperative multitasking has this problem is that the system entrusts the triggering condition for context switching to the behavior of the process. We know that when scheduling a process, the entire computer will be controlled by it, whether it is computing, accessing memory, or input and output, it is all determined by the behavior of the process. To fix this loophole, we must find a mechanism that cannot be controlled by the process.
The Voice from the Outside
Recall when we were taking exams, we could control how to answer the questions on the test paper, but when the bell rang, regardless of whether we had finished answering or not, we had to immediately hand in the test paper. What we hope for is precisely this kind of effect: when the time is up, no matter how unwilling the running process is, the operating system must perform a context switch.
And the key to solving the problem is the clock. We have already added a clock in IOE, but this still cannot meet our needs. We hope that the clock can actively notify the processor, rather than passively waiting for the processor to access it.
This notification mechanism is called a hardware interrupt in computers. The essence of a hardware interrupt is a digital signal. When a device has an event that needs to notify the CPU, it will send an interrupt signal. This signal will eventually be transmitted to the CPU, attracting the CPU's attention.
The first question is how the interrupt signal is transmitted to the CPU. Device controllers that support the interrupt mechanism all have an interrupt pin, which is connected to the CPU's INTR pin. When a device needs to issue an interrupt request, it only needs to set the interrupt pin to a high level, and the interrupt signal will be continuously transmitted to the CPU's INTR pin. However, there are usually multiple devices on a computer, and the CPU pins are fixed during manufacturing, so it is not practical to allocate a pin for each device interrupt at the CPU end.
In order to better manage interrupt requests from various devices, IBM PC-compatible machines all have an Intel 8259 PIC (Programmable Interrupt Controller), while the interrupt controller used more often in RISC-V systems is the PLIC (Platform Level Interrupt Controller). The main function of the interrupt controller is to act as a multiplexer for device interrupt signals, that is, to select one signal from multiple device interrupt signals and then forward it to the CPU.
The second question is how the CPU responds to incoming interrupt requests. Every time the CPU finishes executing an instruction, it will check the INTR pin to see if there is a device interrupt request. An exception is when the CPU is in the interrupt-disabled state, in which case the CPU will not respond to interrupts even if the INTR pin is at a high level. The CPU's interrupt-disabled state is independent of the interrupt controller. The interrupt controller is only responsible for forwarding device interrupt requests, and whether the CPU ultimately responds to interrupts still depends on the CPU's state.
The CPU's interrupt-disabled state can be controlled by software, and different ISAs have different definitions for this, specifically:
- In x86, if the IF bit in EFLAGS is 0, the CPU is in the interrupt-disabled state
- In mips32, if the IE bit in status is 0, or the EXL bit is 1, or the ERL bit is 1, the CPU is in the interrupt-disabled state
- In riscv32, if the MIE bit in mstatus is 0, the CPU is in the interrupt-disabled state
- In fact, the interrupt response mechanism in the riscv32 standard has more content, which we have simplified in PA. To understand the complete interrupt response mechanism, please refer to the relevant manuals.
If the CPU is not in the interrupt-disabled state when an interrupt arrives, it must immediately respond to the incoming interrupt request. We just mentioned that the interrupt controller will generate an interrupt number, and the CPU will save the interrupt context, then treat this interrupt as the reason for the exception handling process, find and jump to the entry address, and perform some device-related processing. This process is very similar to the exception handling mentioned earlier.
For the CPU, when a device interrupt request arrives is unpredictable, and it is also possible that another interrupt request arrives while processing an interrupt request. If you want to support interrupt nesting -- that is, responding to another higher-priority interrupt while processing a lower-priority interrupt -- then the stack will be the only choice for saving interrupt context information. If you choose to save the context information in a fixed location, when interrupt nesting occurs, the context information saved by the first interrupt will be overwritten by the higher-priority interrupt handling process, resulting in disastrous consequences.
Catastrophic consequences (this question is a bit difficult)
Suppose the hardware stores the interrupt information at a fixed memory address (e.g., 0x1000), and AM always starts constructing the context from here. If interrupt nesting occurs, what catastrophic consequences will happen? In what form will these catastrophic consequences manifest? If you have no clue, you can simulate the interrupt handling process with pen and paper.
How to support interrupt nesting
Think about how the software and hardware of x86, mips32, and riscv32 should cooperate to support interrupt nesting.
Preemptive multitasking
The second type of time-sharing multitasking is preemptive multitasking. It is based on hardware interrupts (usually timer interrupts) to forcibly perform context switching, allowing all processes in the system to run in a fair round-robin manner. In a preemptive multitasking operating system, interrupts are the foundation of its existence: As soon as the wind of interrupts blows, the operating system will come back to life, and even a malicious program with an intentional infinite loop, no matter how powerful it is, will be asked to leave the CPU at this moment, giving other programs a chance to run.
In NEMU, we only need to add the timer interrupt. Since there is only one interrupt, we do not need to manage interrupts through an interrupt controller, we can directly connect the timer interrupt to the CPU's INTR pin. As for the interrupt number of the timer interrupt, different ISAs have different conventions. The timer interrupt is triggered by timer_intr() in nemu/src/device/timer.c, which is triggered every 10ms. After being triggered, it will call the dev_raise_intr() function (defined in nemu/src/device/intr.c). You need to:
- Add a
boolmemberINTRto the cpu structure. - In
dev_raise_intr(), set the INTR pin to high level. - At the end of the for loop in
cpu_exec(), add code to poll the INTR pin, checking if a hardware interrupt has arrived after executing each instruction:
word_t intr = isa_query_intr();
if (intr != INTR_EMPTY) {
cpu.pc = isa_raise_intr(intr, cpu.pc);
}
- Implement the
isa_query_intr()function (defined innemu/src/isa/$ISA/system/intr.c):
#define IRQ_TIMER 32 // for x86
#define IRQ_TIMER 0 // for mips32
#define IRQ_TIMER 0x80000007 // for riscv32
#define IRQ_TIMER 0x8000000000000007 // for riscv64
word_t isa_query_intr() {
if ( ??? ) {
cpu.INTR = false;
return IRQ_TIMER;
}
return INTR_EMPTY;
}
- Modify the code in
isa_raise_intr()to make the processor enter the disabled interrupt state:- x86 - After saving the EFLAGS register, set its IF bit to
0 - mips32 - Set status.EXL to
1- You also need to modify the implementation of the eret instruction, setting status.EXL to
0
- You also need to modify the implementation of the eret instruction, setting status.EXL to
- riscv32 - Save mstatus.MIE to mstatus.MPIE, then set mstatus.MIE to
0- You also need to modify the implementation of the mret instruction, restoring mstatus.MPIE to mstatus.MIE, then setting mstatus.MPIE to
1
- You also need to modify the implementation of the mret instruction, restoring mstatus.MPIE to mstatus.MIE, then setting mstatus.MPIE to
- x86 - After saving the EFLAGS register, set its IF bit to
On the software side, you also need to:
- Add support for timer interrupts in CTE, packaging the timer interrupt as the
EVENT_IRQ_TIMERevent. - After Nanos-lite receives the
EVENT_IRQ_TIMERevent, callschedule()to force the current process to yield the CPU, and you can also remove theyield()we previously inserted in device access. - To allow the processor to respond to timer interrupts while running user processes, you also need to modify the code of
kcontext()anducontext(), setting the correct interrupt state when constructing the context, so that the CPU will be in the enabled interrupt state after restoring the context in the future.
Implement preemptive multitasking
According to the above content in the lecture notes, add the corresponding code to implement preemptive time-sharing multitasking.
To test if the timer interrupt is working, you can use Log() to output a message after Nanos-lite receives the EVENT_IRQ_TIMER event.
Hardware interrupts and DiffTest
For DiffTest, we cannot directly inject timer interrupts into QEMU, so we cannot guarantee that QEMU and NEMU are in the same state when the interrupt arrives. However, the infrastructure that has accompanied you all the way should have helped you eliminate most of the bugs, so try to rely on yourself for the remaining short distance.
Interrupts and user process initialization
We know that the user process starts running from Navy's _start, and the correct stack pointer is set in _start. If an interrupt arrives before the user process sets the correct stack pointer, can our system still handle the interrupt correctly?
Time-slice based process scheduling
In a preemptive multitasking operating system, since timer interrupts arrive at a fixed rate, time is divided into equal-length time slices, allowing the system to perform time-slice based process scheduling.
Priority scheduling
We can modify the code of schedule() to allocate more time slices to The PAL so that The PAL is scheduled several times before the hello kernel thread is scheduled once. This is because the hello kernel thread only continuously outputs strings, and we only need to let the hello kernel thread output occasionally to confirm that it is still running.
We will find that after allocating more time slices to The PAL, its running speed has improved to some extent. This once again demonstrates the essence of "time-sharing": programs only take turns using the processor, they are not truly running "simultaneously".
The scheduling problem in real systems is much more complicated than the example of The PAL. For instance, during the Double 11 shopping festival, shopping requests are sent to Alibaba's servers from all over the country in an instant, and these requests will eventually be converted into hundreds of millions of processes being processed on tens of thousands of servers. How to schedule such a huge number of processes in the data center to maximize user service quality is a daunting challenge that Alibaba has always faced.
Preemption and Concurrency
If there were no interrupts, the operation of a computer would be completely deterministic. Based on the current state of the computer, you can completely infer the state of the computer after executing the next instruction, or even after executing 100 instructions. However, if the computer supports interrupts, the behavior of the state machine becomes unpredictable.
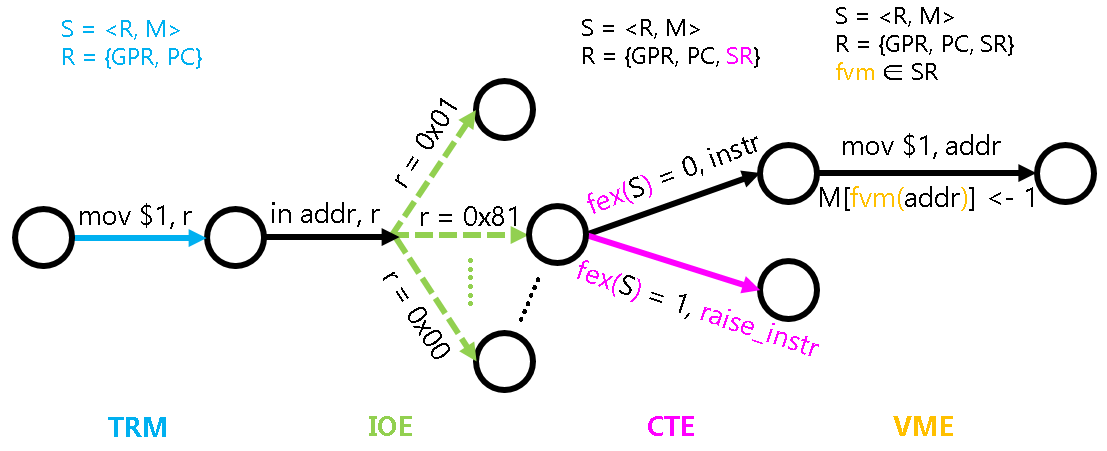
To model the behavior of interrupts, we extend the definition of the fex() function: in addition to determining whether the current state needs to throw an exception, if the current processor is in an interrupt-enabled state, it also needs to determine whether an interrupt has arrived. This means that during the execution of each instruction, the computer may jump to the interrupt handler due to the arrival of an interrupt.
The uncertainty brought by interrupts to computer systems can be considered a double-edged sword. For example, the GNU/Linux kernel maintains an entropy pool to collect entropy (uncertainty) in the system. Whenever an interrupt arrives, some entropy is added to this pool. Through this entropy, we can generate truly random numbers, which is how /dev/random works. With truly random numbers, attacks by malicious programs become relatively difficult (such as ASLR), and the system's security is also enhanced.
On the other hand, the existence of interrupts also forces programs to pay an additional cost in handling some issues. Since interrupts can occur at any time, if two processes share a variable v (for example, multiple threads in Thunder download share the same file buffer), when process A writes 0 to v and an interrupt arrives immediately after that, the value of v may no longer be 0 the next time A runs. To some extent, this is also the trouble caused by concurrency: it is possible that process B is concurrently modifying the value of v, but A is unaware of this. Such bugs caused by concurrency also bear the mark of uncertainty: if the timing of the interrupt arrival is different, the bug may not be triggered. Therefore, this kind of bug is also called a Heisenbug, similar to the uncertainty principle in quantum mechanics - when you try to debug it, it may not appear.
Not only can there be shared variables between user processes, but the operating system kernel is also a disaster area for concurrency bugs. For example, multiple user processes that concurrently write to the same file share the same file offset, and if not handled properly, it may lead to data loss during writing. More generally, user processes will execute system calls concurrently, and the operating system needs to ensure that they can all execute correctly according to the semantics of the system calls.
Ah, let's not spoil too much. When you take the operating system course, you will gradually experience the fun (and pain) of it. Perhaps by then, you will miss the good old days of single-threaded PA.
Kernel Stack and User Stack
We previously left the following question as the most difficult one for you to ponder:
Why is it currently not supported to concurrently execute multiple user processes?
Now we will reveal the answer to the question: this is due to the access of the user stack.
Problem Analysis
For ease of description, let's assume that at a certain moment, the operating system is about to switch from user process A to user process B. Specifically, when A is running, the stack pointer sp points to A's user stack. When A executes a system call or an interrupt arrives, it will enter the operating system through CTE. At this time, if the operating system decides to schedule user process B, it will return B's context to CTE, and expects CTE to perform the following operations in sequence:
- Switch to B's virtual address space through
__am_switch() - Restore B's context in
trap.S
If we carefully consider the details of the process, we will discover the problem. Specifically, before __am_switch() switches to B's virtual address space, it needs to first read out the address space descriptor pointer pdir (for x86, it is cr3) from B's context structure. However, B's context structure was created on B's user stack the last time B entered CTE, but B's user stack is not in A's virtual address space!
Therefore, to correctly read out B's address space descriptor pointer, we need to switch to B's virtual address space first; but on the other hand, to switch to B's virtual address space, we need to first correctly read out B's address space descriptor pointer! This forms a "chicken and egg" circular dependency problem. During actual execution, the code of __am_switch() will read out an incorrect address space descriptor pointer, and thus cannot correctly switch to B's virtual address space.
To break the above circular dependency, we cannot store the address space descriptor pointer in the user stack, but should store it in an address space that is visible to all user processes. Obviously, this address space visible to all user processes is the kernel's virtual address space, because all virtual address spaces will contain kernel mappings, which ensures that no matter which user process the operating system switches to, the code can access the kernel's virtual address space through the kernel mapping.
However, as an address space descriptor pointer, its value is already determined when creating the user process context, and its value is consistent every time it enters CTE. Therefore, we do not need to save it when an interrupt or exception arrives. Instead, we only need to store it in the PCB when creating the user process context, and when we need to switch the virtual address space, we can directly read out the address space descriptor pointer from B's PCB. Of course, PCB is a concept of the operating system, which AM is not aware of, so VME needs to provide a new API switch_addrspace(): after the operating system selects process B in schedule(), it first switches to B's virtual address space through switch_addrspace(), and then returns to CTE and restores B's context.
Method to break the circular dependency
As described above, storing the address space descriptor pointer in the PCB, and adding a new API switch_addrspace() in VME, from the perspective of correctness, is this solution feasible?
We will leave the analysis of the correctness of the above solution as a thinking exercise for you. Assuming the above solution is correct, but in a real operating system, saving the context on the user stack would introduce a security vulnerability. A malicious program can execute the following instruction sequence:
la sp, kernel_addr
ecall
If the operating system saves the context to the memory location pointed to by sp, the kernel data located at kernel_addr will be maliciously corrupted!
Therefore, the operating system cannot trust the value of the stack pointer when entering the kernel. Before performing any stack operations (including saving the context), the operating system needs to first point the stack pointer to a stack prepared by itself. This process is called "stack switching". After that, the location for saving the context is under the control of the operating system, thereby solving the problem of the above malicious program. This stack prepared by the operating system itself is the kernel stack we introduced earlier.
In addition to solving the above security vulnerability, using the kernel stack can also make the above circular dependency problem self-resolving: no matter which user process the operating system switches to, the code can successfully access the kernel stack, thereby breaking the above circular dependency.
A method to break the circular dependency (2)
The TSS (Task State Segment) mechanism in x86 can, with hardware support, allow the operation of switching virtual address spaces and the operation of context restoration to occur simultaneously. Since they occur simultaneously, there is no circular dependency issue caused by the order of multiple operations.
Specifically, the TSS mechanism requires the system software (e.g., the operating system) to first prepare a special data structure in memory to describe the process context, which also includes the value of the CR3 register that describes the process's virtual address space. Then, the address of the data structure is set to a system register called TR. Finally, a special instruction is executed, and the hardware will automatically restore the context and switch the virtual address space based on the contents of the data structure.
This solution requires implementing a very complex context restoration instruction in hardware, which obviously not all processor architectures have.
Context switching in Linux
In early versions of Linux, context switching was indeed performed through the hardware TSS mechanism. Later, it was found that implementing this complex instruction in hardware was not as performant as software-implemented context switching. Additionally, as Linux evolved, more architectures needed to be supported. For better code maintainability, Linux eventually chose to implement context switching in software. This article summarizes the evolution of the context switching code in Linux from the initial 0.01 version to the modern 4.x versions, for those interested in learning more.
Details on stack switching
To implement stack switching, we need to implement the following functionality:
- If entering CTE from user mode, switch to the kernel stack before CTE saves the context, and then save the context
- If returning to user mode in the future, switch to the user stack after CTE restores the context from the kernel stack, and then return
Note that if we enter CTE from kernel mode, no switching is needed; if we mistakenly point the stack pointer to the bottom of the kernel stack again, the existing contents of the kernel stack will be overwritten by the subsequent push operations!
User mode and stack pointer
Generally speaking, the processor's privilege level is also a state. Can we determine whether we are currently in user mode or kernel mode based on the value of the stack pointer?
Basic functionality
To implement the above functionality, we need to solve the following problems:
- How to identify whether it was in user mode or kernel mode before entering CTE? -
pp(Previous Privilege) - How does the CTE code know where the kernel stack is? -
ksp(Kernel Stack Pointer) - How to know whether to return to user mode or kernel mode? -
np(Next Privilege) - How does the CTE code know where the user stack is? -
usp(User Stack Pointer)
We have defined a conceptual variable for each of these problems. To solve these problems, we need to maintain these variables correctly in the CTE. We use pseudocode to describe the functionality that needs to be implemented, where $sp represents the stack pointer register:
void __am_asm_trap() {
if (pp == USER) {
usp = $sp;
$sp = ksp;
}
np = pp;
// save context
__am_irq_handle(c);
// restore context
pp = np;
if (np == USER) {
ksp = $sp;
$sp = usp;
}
return_from_trap();
}
Note that the above pseudocode only describes the conceptual behavior, and does not mean that the code must be written strictly in the corresponding order. For example, np = pp; can be placed after saving the context, or even at the beginning of __am_irq_handle(). From the pseudocode, the functionality we need to add does not seem too complex.
System complexity
If you think the above code is not difficult to implement, you are underestimating the complexity of the system. Try not to read the following content first, and analyze what problems the above code may encounter in the actual running process? If there are problems, how should they be solved?
Context switching
But don't forget, the operating system may return a new context structure through CTE and perform a switch. We need to ensure that the code still works correctly under the condition that context switching will occur.
System complexity (2)
Since you have already seen this, try not to read the following content first, and then try to analyze how to ensure that the code still works correctly under the condition that context switching will occur?
We need to carefully consider the behavior of the above variables. After some simple analysis, we can find that pp and ksp are not affected by context switching: they are assigned before leaving CTE, but are not used until the next time they enter CTE. Their values do not change during this period, and context switching only occurs after they are used. However, np and usp are different. They are assigned when entering CTE and used before leaving CTE, and context switching may occur during this period.
We can easily construct an example to illustrate the problem caused by context switching. Suppose a user process enters CTE due to a system call or interrupt, the above code will set np to USER, indicating that the next time it leaves CTE, it will return to user mode. If context switching occurs during this period and switches to a kernel thread, the kernel thread will find that np is USER after restoring the context, and will mistakenly set usp to $sp. We know that the kernel thread does not have a user stack, and when it returns from CTE, the execution of the kernel thread will have disastrous consequences.
For these variables affected by context switching, we cannot simply define them as global variables. They are attributes used to describe the context and should switch along with the context. Therefore, defining them in the Context structure is the correct approach:
void __am_asm_trap() {
if (pp == USER) { // pp is global
c->usp = $sp; // usp should be in Context
$sp = ksp; // ksp is global
}
c->np = pp; // np should be in Context
// save context
__am_irq_handle(c);
// restore context
pp = c->np;
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
CTE re-entry
In addition to context switching, we also need to consider the CTE re-entry problem: is it possible for the code to re-enter CTE before leaving CTE?
We know that yield() is implemented through CTE. If a user process enters the kernel through a system call and then executes yield(), CTE re-entry will occur.
Another phenomenon that causes CTE re-entry is the interrupt nesting mentioned earlier: when the first interrupt arrives, the code enters CTE, but the second interrupt may arrive before the code leaves CTE.
However, interrupt nesting will not occur in PA because we put the processor in a disabled interrupt state after entering CTE.
What impact will CTE re-entry have on the above code? By analyzing the behavior of the code from the perspective of a program state machine, we can easily see the problem.
System complexity (3)
We treat the CTE re-entry problem as an exercise from the perspective of a state machine. Please try to analyze what problems the above code has in the case of CTE re-entry.
To solve this problem, we need to modify the above code as follows:
void __am_asm_trap() {
if (pp == USER) { // pp is global
c->usp = $sp; // usp should be in Context
$sp = ksp; // ksp is global
}
c->np = pp; // np should be in Context
pp = KERNEL; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
pp = c->np;
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
Operating systems and interrupts
In real operating systems, system call processing is performed with interrupts enabled. This is because system call processing may take a very long time. For example, SYS_read may read a large amount of data from a mechanical disk. If the operating system is always in a disabled interrupt state, it will not be able to respond to various interrupt requests in the system in a timely manner: The system clock maintained by the clock interrupt may experience significant delays, and the network card may drop a large number of network packets due to a full buffer...
This poses a great challenge for operating system design: since the arrival of interrupts is unpredictable, it means that CTE re-entry may occur at any point during system call processing. Even more troublesome is that not only the CTE code will produce re-entry, but also much of the code in the operating system may produce re-entry. Therefore, operating system developers must be very careful when writing the corresponding code, or else global variables may be overwritten due to re-entry.
It is precisely because of this challenge that we simply avoid this problem by disabling interrupts in PA. In fact, re-entry can be considered a special form of concurrency, and you will have a deeper understanding of concurrency in the operating system course next semester.
Some optimizations
We can make some simple optimizations to the above code. One place that can be optimized is to merge the functionality of pp into ksp, allowing ksp to represent both the address of the kernel stack and the privilege level before entering CTE.
Note that ksp is always used when pp == USER, and the value of ksp is definitely not 0, so we can use ksp == 0 to represent pp == KERNEL.
We make the following convention for the value of ksp:
- If currently in user mode, the value of
kspis the bottom of the kernel stack - If currently in kernel mode, the value of
kspis0
After that, the above code can be optimized to:
void __am_asm_trap() {
if (ksp != 0) { // ksp is global
c->usp = $sp; // usp should be in Context
$sp = ksp;
}
c->np = (ksp == 0 ? KERNEL : USER); // np should be in Context
ksp = 0; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
Another place that can be optimized is to merge the functionality of c->usp into c->sp, allowing c->sp to represent the value of $sp before entering CTE, regardless of whether the system was in user mode or kernel mode before entering CTE.
Similarly, when restoring the context, simply assign c->sp to $sp.
This way, there is no need to define usp additionally in the Context structure, so the above code can be optimized to:
void __am_asm_trap() {
c->sp = $sp;
if (ksp != 0) { // ksp is global
$sp = ksp;
}
c->np = (ksp == 0 ? KERNEL : USER); // np should be in Context
ksp = 0; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
if (c->np == USER) {
ksp = $sp;
}
$sp = c->sp;
return_from_trap();
}
Implementation details of stack switching
The above discussion is only a conceptual solution. To implement kernel stack switching in the code, we still need to map the conceptual variables mentioned above to specific implementations related to the ISA.
mips32
For implementing kernel stack switching, mips32 is the simplest. According to the mips32 ABI convention, two registers k0 and k1 in the general-purpose registers are reserved specifically for kernel use, and the compiler will not allocate variables to k0 or k1. Therefore, we can make the following conventions:
- Map the conceptual
kspto thek0register - Map the conceptual
c->nptoc->gpr[k1] - Map the conceptual
c->sptoc->gpr[sp]
You only need to add a small amount of code in the CTE according to the above conventions to implement kernel stack switching.
riscv32
Unlike mips32, the riscv32 ABI does not specify register usage similar to k0 and k1. Instead, riscv32 provides a CSR register called mscratch, specifically as a temporary register for system software to use. It does not have any special behavior in hardware. Therefore, we can make the following conventions:
- Map the conceptual
kspto themscratchregister - Add a new member
npto the Context structure, and map the conceptualc->npto it - Map the conceptual
c->sptoc->gpr[sp]
However, when you plan to implement the code, you will find that before entering CTE and switching to the kernel stack, we do not have any free general-purpose registers to use! In fact, the design of riscv32 is very ingenious, and we can complete the kernel stack switching with 3 instructions:
__am_asm_trap:
csrrw sp, mscratch, sp // (1) atomically exchange sp and mscratch
bnez sp, save_context // (2) take the branch if we trapped from user
csrr sp, mscratch // (3) if we trapped from kernel, restore the original sp
save_context:
// now sp is pointing to the kernel stack
// save the context...
To check the value of mscratch, we cleverly use the atomic exchange function of the CSR access instruction in (1) to exchange the values of sp and mscratch. This way, we can read the original mscratch value into the general-purpose register sp for comparison (riscv32's branch instructions cannot access CSR registers), and also save the original sp value into the mscratch register to avoid being overwritten.
Next, we use (2) to check the mscratch value (i.e., the conceptual ksp) that was just read out: if the value is 0, it means that it was in kernel mode before entering CTE, and at this point, the kernel stack pointer has been exchanged into the mscratch register by (1), so we use (3) to read the kernel stack pointer back; if the value is not 0, it means that it was in user mode before entering CTE, and we need to switch sp to the kernel stack, but instruction (1) has already completed this switching, so we can directly jump to save_context to save the context.
Temporary register scheme
As a temporary register for CTE, mips32 chooses to allocate k0 and k1 in the GPR, while riscv32 uses the mscratch CSR register. Compared to these two schemes, is there a better one? Why?
x86
Implementing kernel stack switching in x86 is relatively special, because the x86 exception handling mechanism directly saves eflags, cs, and eip onto the stack, and software code cannot interfere with this behavior.
If we want to save these 3 registers onto the kernel stack, the x86 hardware needs to perform the kernel stack switching. Similarly, the x86 iret instruction restores the context by popping from the stack. This means that we cannot restore the user stack pointer through software either: if we switch to the user stack before the iret instruction, the iret instruction will not be able to find the correct eflags, cs, and eip; but if we execute the iret instruction first, eip will point to the user code, and at this point, we will no longer be able to restore the user stack pointer.
Therefore, x86 must provide a solution to the above problem through hardware mechanisms. First, we must allow the hardware to identify the current privilege level, which is identified through the RPL field in the CS register (also known as CPL defined in the i386 manual). If CS.RPL is 0, it means the processor is in kernel mode; if CS.RPL is 3, it means the processor is in user mode.
Then, according to the i386 manual, we extend the behavior of the x86 exception handling mechanism and the iret instruction:
- If an exception occurs in kernel mode, the behavior of the exception handling mechanism is consistent with the description in PA3 (see
WITHOUT PRIVILEGE TRANSITIONin Figure 9-5 of the i386 manual) - If an exception occurs in user mode, the exception handling mechanism first finds
kspthrough the TSS mechanism, then pushesss(stack segment register) andespontoksp, and finally pusheseflags,cs, andeip(seeWITH PRIVILEGE TRANSITIONin Figure 9-5 of the i386 manual) - When executing the
iretinstruction, first popeip,cs, andeflagsin order. If the poppedcsindicates that it will return to user mode, then continue to popespandss
The complete TSS mechanism has two purposes: one is for context switching in hardware, and the other is for kernel stack switching when an exception occurs in user mode. In PA, we only need to care about the latter.
However, to introduce the TSS mechanism, we have to introduce the segmentation mechanism that we originally hoped to simplify in PA. However, you have already learned about the exception handling mechanism in PA3, which will help you understand the TSS mechanism.
Let's first review the x86 exception handling mechanism:
Read the starting address of the IDT array from the IDTR register, index the IDT with the exception number to get a gate descriptor, and then combine the offset field in the gate descriptor into an address.
Then we can analogize the processing of the TSS mechanism:
Read the starting address of the GDT array from the GDTR register, index the GDT with the idx field in the TR register to get a TSS descriptor, and then combine the base field in the TSS descriptor into an address.
Oh, it doesn't seem too difficult to understand. However, the address finally obtained in the exception handling mechanism is the exception entry address, while the address finally obtained in the TSS mechanism is the address of the TSS structure. The TSS structure has many members, but in the kernel stack switching process, the hardware will only use the ss0 and esp0 members (see the definition of the TSS32 structure in abstract-machine/am/src/x86/x86.h). Chapter 7 of the ICS textbook introduces the exception handling process with the TSS mechanism, and for details about the TSS mechanism, you can also refer to the i386 manual.
With the support of the hardware TSS mechanism, the CTE only needs to maintain the conceptual variable ksp in software:
- Map the conceptual
kspto theesp0member of the TSS structure - Map the conceptual
c->nptoc->cs.RPL - Add two new members
ss3andesp3to the Context structure, and map the conceptualc->sp(actuallyc->usp) toc->esp3
To ensure that the TSS mechanism can work correctly in the future, we also need to add some initialization code in cte_init():
#define NR_SEG 6
static SegDesc gdt[NR_SEG] = {};
static TSS32 tss = {};
bool cte_init(Context*(*handler)(Event, Context*)) {
// ...
// initialize GDT
gdt[1] = SEG32(STA_X | STA_R, 0, 0xffffffff, DPL_KERN);
gdt[2] = SEG32(STA_W, 0, 0xffffffff, DPL_KERN);
gdt[3] = SEG32(STA_X | STA_R, 0, 0xffffffff, DPL_USER);
gdt[4] = SEG32(STA_W, 0, 0xffffffff, DPL_USER);
gdt[5] = SEG16(STS_T32A, &tss, sizeof(tss) - 1, DPL_KERN);
set_gdt(gdt, sizeof(gdt[0]) * NR_SEG);
// initialize TSS
tss.ss0 = KSEL(2);
set_tr(KSEL(5));
return true;
}
We set 5 descriptors in the GDT array. The first 4 represent the kernel code segment, kernel data segment, user code segment, and user data segment, respectively. They are used to allow QEMU to correctly handle privilege levels during DiffTest. We do not need to worry about the details.
Implement switching between kernel stack and user stack
Understand the above lecture notes, modify the CTE code to support switching between the kernel stack and user stack. You need to understand how your implementation reflects the functionality of the above pseudocode. At the same time, depending on the nature of different conceptual variables, you may also need to initialize them in cte_init() or kcontext()/ucontext(). If you want to maintain these conceptual variables in __am_irq_handle(), you can use inline assembly when necessary.
After implementation, let Nanos-lite load the NTerm and hello user processes, and then start the PAL from NTerm. If your implementation is correct, you will see the hello user process and NTerm/PAL running in a time-sharing manner. Unlike the previous effect, this time we have truly implemented time-sharing execution of two user processes.
Some hints:
- For easier debugging, you can first disable the clock interrupt in NEMU, which can improve the determinism of the system. After successful testing, turn on the clock interrupt again.
- mips32 -
k1is already a usable register before saving the context - riscv32 - To maintain
c->np, you may need to save a small portion of the GPR immediately after switching to the kernel stack, or use a global variable to help you - x86 - In addition to implementing the necessary registers and hardware mechanisms in hardware, you also need to perform the following initializations:
- In
kcontext(), setc->cstoKSEL(1) - In
ucontext(), setc->cstoUSEL(3)andc->ss3toUSEL(4)
- In
Note that we currently only allow at most one process that needs to update the screen to participate in scheduling. This is because concurrent execution of such processes will cause the screen to be overwritten, affecting the screen output effect. In a real graphical user interface operating system, a window manager process usually manages the screen display in a unified manner. Processes that need to display the screen communicate with this manager process to achieve the purpose of updating the screen. However, this requires the operating system to support inter-process communication mechanisms, which is beyond the scope of ICS. Since Nanos-lite is a trimmed-down operating system, it does not provide inter-process communication services either. Therefore, we have simplified it to allow at most one process that needs to update the screen to participate in scheduling.
Complexity of real systems
By analyzing the problems and solutions that need to be solved for "concurrent execution of multiple user processes", we have seen that when some learned knowledge points are combined, the complexity of the problem may increase exponentially: Interrupts can occur at any time, and trap operations may occur, all of which may trigger context switching; On the one hand, this may lead to switching of virtual address spaces, and on the other hand, when the context returns, it may be necessary to switch to the user stack or the kernel stack, which in turn depends on the maintenance of some variables; Although these variables are all defined and used through the C language, under the combined effect of interrupt exceptions and context switching, global variables and member variables in the Context structure have different lifetimes, and we need to define some key variables in different locations according to different scenarios...
Modern computer systems are generally equipped with multi-core processors and run multi-core operating systems, so there is another class of variables related to the number of processors; in addition to the concurrent scenarios brought by interrupt exception handling, multiple processors may even execute code in parallel, and how to correctly solve various concurrency problems in multi-core systems has always been a challenge in the field of computer systems.
Nanos-lite and concurrency bugs (recommended for second pass/after completing the operating system course)
When discussing concurrency in the above text, it is mentioned: more generally, user processes will execute system calls concurrently, and the operating system needs to ensure that they can all execute correctly according to the semantics of the system call.
In PA3, we know that printf() will allocate a buffer through malloc(), and malloc() may execute _sbrk(), trapping into the kernel through SYS_brk; in the previous stage, we implemented mm_brk() supporting the paging mechanism, which will request a page through new_page() when necessary. Both the Xian Jian and hello user processes will call printf(), causing them to potentially execute SYS_brk concurrently. Think about it, will the current design of Nanos-lite lead to concurrency bugs? Why?