



引言
通过状态机模型,
你已经对程序如何在计算机上运行建立基本认识
本次课内容:
C程序如何从源代码生成指令序列(二进制可执行文件)
- 预处理 -> 编译 -> 汇编 -> 链接 -> 执行
学习处理器设计, 为什么要了解这些?
- 因为将来你需要把C代码编译到你的处理器上运行
Talk is cheap, show me the code!
预处理
预处理 = 文本粘贴
// a.c
#include <stdio.h>
#define MSG "Hello \
World!\n"
#define _str(x) #x
#define _concat(a, b) a##b
int main() {
printf(MSG /* "hi!\n" */);
#ifdef __riscv
printf("Hello RISC-V!\n");
#endif
_concat(pr, intf)(_str(RISC-V));
return 0;
}
头文件是如何找到的?
方法:
阅读工具的日志(查看是否支持verbose,
log等选项)
通过man gcc并搜索-I选项可得知头文件搜索的顺序
echo '#warning I am wrong!' > stdio.h
gcc -E a.c
# change <stdio.h> to "stdio.h" in a.c
gcc -E a.c
rm stdio.h
mkdir aaa bbb
gcc -E a.c -Iaaa -Ibbb --verbose > /dev/null
echo '#warning I am wrong, too!' > bbb/stdio.h
gcc -E a.c -Iaaa -Ibbb
echo '#define printf(...)' >> bbb/stdio.h
gcc -E a.c -Iaaa -Ibbb
启发: 动手做一些简单的尝试, 你能学会很多
类函数宏
预处理阶段只进行文本粘贴, 不求值
- 小心优先级!
- 好的编程习惯 -> 总是用括号包围参数
预处理的其他工作
- 去掉注释
- 连接因断行符(行尾的
\)而拆分的字符串
IOCCC(国际混乱C代码大赛)
套路: 借助预处理机制编写不可读代码
#\
define C(c /**/)#c
/*size=3173*/#include<stdio.h>
/*crc=b7f9ecff.*/#include<stdlib.h>
/*Mile/Adele_von_Ascham*/#include<time.h>
typedef/**/int(I);I/*:3*/d,i,j,a,b,l,u[16],v
[18],w[36],x,y,z,k;char*P="\n\40(),",*p,*q,*t[18],m[4];
void/**/O(char*q){for(;*q;q++)*q>32?z=111-*q?z=(z+*q)%185,(k?
k--:(y=z%37,(x=z/37%7)?printf(*t,t[x],y?w[y-1]:95):y>14&&y<33?x
=y>15,printf(t[15+x],x?2<<y%16:l,x?(1<<y%16)-1:1):puts(t[y%28])))
,0:z+82:0;}void/**/Q(I(p),I*q){for(x=0;x<p;x++){q[x]=x;}for(;--p
>1;q[p]=y)y =q[x=rand()%-~p],q[x]=q[p];}char/**/n[999]=C(Average?!nQVQd%R>Rd%
R% %RNIPRfi#VQ}R;TtuodtsRUd%RUd%RUOSetirwf!RnruterR{RTSniamRtniQ>h.oidts<edulc
ni #V>rebmun<=NIPD-RhtiwRelipmocResaelPRrorre#QNIPRfednfi#V__ELIF__R_
Re nifed#V~-VU0V;}V{R= R][ORrahcRdengisnuRtsnocRcitatsVesle#Vfidne#V53556
. .1RfoRegnarRehtRniRre getniRnaRsiR]NIP[R erehwQQc.tuptuoR>Rtxt.tupniR
< R]NIP[R:egasuV_Redulcn i#VfednfiVfednuVenife dVfedfiVQc%Rs%#V);I/**/main(
I( f),char**e){if(f){for(i= time(NULL),p=n,q= n+998,x=18;x;p++){*p>32&&!(
*--q=*p>80&&*p<87?P[*p- 81]:* p)?t [( -- x)]=q+1:q;}if(f-2||(d=atoi
(e[1]))<1||65536<d){;O(" \""); goto O;}srand(i);Q(16,u);i=0;Q(
36,w);for(;i<36; i++){w[i] +=w [i]<26 ? 97:39; }O(C(ouoo9oBotoo%]#
ox^#oy_#ozoou#o{ a#o|b#o}c# o~d#oo-e #oo. f#oo/g#oo0h#oo1i#oo
2j#oo3k#oo4l#o p));for(j =8;EOF -(i= getchar());l+=1){a=1+
rand()%16;for(b =0;b<a||i- main (0,e);b++)x=d^d/4^d/8^d/
32,d= (d/ 2|x<<15)&65535; b|= !l<<17;Q(18,v);for(a=0;a<18;
a++ ){if( (b&(1<<(i=v[a] ))))* m=75+i,O(m),j=i<17&&j<i?i:j;}O(C(
!) ); }O(C(oqovoo97o /n!));i= 0;for(;i<8;O(m))m[2]=35,*m=56+u[i],m[1
]= 75 +i++;O(C(oA!oro oqoo9) );k=112-j*7;O(C(6o.!Z!Z#5o-!Y!Y#4~!X!X#3}
!W !W #2 |!V!V#1{!U!U#0z! T!T#/y!S!S#.x!R!R#-w!Q!Q#ooAv!P!P#+o#!O!O#*t!N!
N# oo >s!M!M#oo=r!L!L#oo<q!K!K# &pIo@:;= oUm#oo98m##oo9=8m#oo9oUm###oo9;=8m#o
o9 oUm##oo9=oUm#oo98m#### o09] #o1:^#o2;_#o3<o ou#o4=a#o5>b#o6?c#o
7@d#o8A e#o 9B f#o:Cg#o; D h#o<Ei #o=Fj#o> Gk#o?Hl#oo9os#####
));d=0 ;} O: for(x=y=0;x<8;++
x)y|= d&(1<<u[x])?
1<< x:0;return
/* :9 */
y ; }编译
编译是一个比较复杂的过程
- 广义的编译: 将一种语言转换成另一种语言的过程
- C语言编译器: 将C语言转换成目标语言的过程
- 目标语言和ISA相关, 通常是指目标ISA的汇编语言
- x86架构的gcc生成x86汇编语言, riscv64-linux-gnu-gcc生成riscv64汇编语言
- 词法分析 -> 语法分析 -> 语义分析 -> 中间代码生成 -> 编译优化 -> 目标代码生成
- 目标语言和ISA相关, 通常是指目标ISA的汇编语言
词法分析
识别并记录源文件中的每一个token
- 标识符, 关键字, 常数, 字符串, 运算符, 大括号, 分号…
- 遇到非法token(如
@), 则报错
- 遇到非法token(如
- 还记录了token的位置(文件名:行号:列号)
C代码 = 字符串
- 词法分析器本质上是一个字符串匹配程序
语法分析
按照C语言的语法将识别出来的token组织成树状结构
- AST(Abstract Syntax Tree), 可以反映出源程序的层次结构
- 文件, 函数, 语句, 表达式, 变量
- 报告语法错误, 例如漏了分号
语义分析
按照C语言的语义确定AST中每个表达式的类型
- 相容的类型将根据C语言标准规范进行类型转换
- 算术类型转换
- 报告语义错误
- 未定义的引用
- 运算符的操作数类型不匹配(如
struct + int) - 函数调用参数的类型和数量不匹配
- …
但大多数编译器并没有严格按阶段进行词法分析, 语法分析, 语义分析
clang的-ast-dump把语义信息也一起输出了man clang可以得知clang的阶段划分
静态程序分析
在不运行程序的情况下对其进行分析
- 本质就是分析AST中的信息
可以检查/分析以下方面
- 语法错误, 代码风格和规范, 潜在的软件缺陷, 安全漏洞, 性能问题
重视lint工具的作用
程序符合C语言的语法, 单独看每条语句也符合C语言的语义
- 直接通过gcc编译并没有任何报错
- 甚至编译后的程序也能成功运行
添加编译选项-Wall, gcc就会进行更多的代码检查工作
- 报告代码中存在
use-after-free的问题 - 这种通过静态程序分析报告代码中潜在问题的工具称为lint工具
初学者的误解: 让编译器报告更多的警告会给编程带来额外的工作量
- 使用lint工具几乎零成本, 却可以帮助开发者发现很多潜在问题
- 这些问题一旦进入程序运行阶段, 将要付出更大的代价来调试
- 在大型项目中, 这些问题非常隐蔽, 软件很可能在运行很长一段时间后突然崩溃, 要调试是非常困难的
中间代码生成
中间代码(也称中间表示, IR) = 编译器定义的, 面向编译场景的指令集
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, ptr %1, align 4
store i32 10, ptr %2, align 4
store i32 20, ptr %3, align 4
%5 = load i32, ptr %2, align 4
%6 = load i32, ptr %3, align 4
%7 = add nsw i32 %5, %6
store i32 %7, ptr %4, align 4
%8 = load i32, ptr %4, align 4
%9 = call i32 (ptr, ...) @printf(ptr noundef @.str, i32 noundef %8)
ret i32 0
}将C语言状态机翻译成IR状态机
- 变量 -> %1, %2, %3, %4, …
- 语句 -> alloca, store, load, add, call, ret, …
中间代码作为抽象层
为什么不直接翻译到处理器ISA?
- 基于抽象层进行优化很容易
- 容易支持多种源语言和目标语言(硬件指令集)
- 假设有
5种源语言,8种目标语言- 不用IR, 要编写
5*8=40个模块; 用IR, 只要编写5+8=13个模块
- 不用IR, 要编写
- 假设有
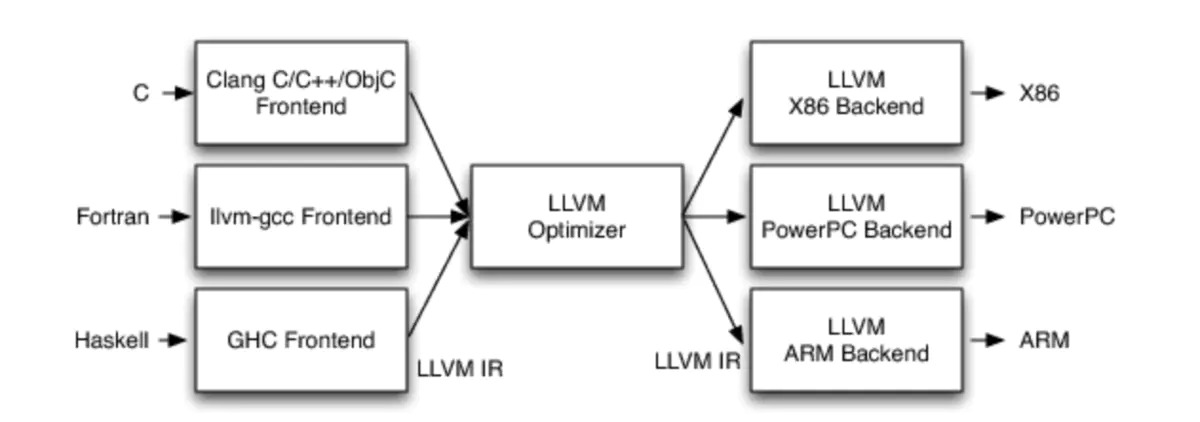
clang使用的中间代码叫LLVM IR,
gcc的叫GIMPLE
- 我们不需要理解其中的细节, 研究它是编译专家的事情
编译优化
对IR进行优化, 用更少的IR来实现同一个程序的行为
下一小节再展开讨论
目标代码生成
clang -S a.c
clang -S a.c --target=riscv64-linux-gnu
gcc -S a.c # 也可以用gcc生成
# apt-get install g++-riscv64-linux-gnu
riscv64-linux-gnu-gcc -S a.c将IR状态机翻译成处理器ISA状态机
- %1, %2, %3, %4, … -> \(\{R, M\}\)
- alloca, store, load, add, call, ret, … -> ISA的指令
编译器还会进行与目标ISA相关的优化
- 尝试把经常使用的变量放到寄存器, 不太常用的变量放到内存
- 尝试生成指令数量较少的指令序列
- 有很多优化的空间, 这里不深入讨论
编译优化
进一步了解编译优化
编译优化是现代软件构建过程中的重要步骤
- 开发者可以将精力集中在程序业务逻辑的开发中
- 不必在开发阶段过多考虑程序的性能
- 编译器通常能提供一个还不错的性能下限
真实项目普遍都使用编译优化技术
将来你也会在自己设计的处理器上运行各种经过编译优化的程序
- 了解编译优化, 知道编译器为什么会生成相应的指令序列, 将有助于将来开展调试和体系结构优化等工作
体验编译优化
#include <stdio.h>
int fib(int n) {
if (n == 0 || n == 1) return 1;
return fib(n - 2) + fib(n - 1);
}
int main() {
int n;
for (n = 0; n < 10; n ++) {
int ans = fib(40);
printf("ans = %d\n", ans);
}
return 0;
}
编译优化的正确性
直觉的定义: 若两个程序在某种意义上一致,
可以用简单的替代复杂的
- 简单 = 变量更少/语句更少…
严谨的定义:
- 严格执行 = 遵循C语言标准逐条语句执行的行为(回顾状态机模型)
一致= 程序的可观测行为(C99 5.1.2.3节第6点)的一致性- 对
volatile关键字修饰变量的访问需要严格执行- 约束C程序内部的行为, 内存映射I/O与此相关
- 程序结束时, 写入文件的数据需要与严格执行时一致
- 没有实时性的外部操作在最后
看起来一致
- 没有实时性的外部操作在最后
- 交互式设备的输入输出(stdio.h)需要与严格执行时一致
- 有实时性的外部操作在执行过程中
看起来一致
- 有实时性的外部操作在执行过程中
- 对
- 只要优化后仍然满足程序可观测行为的一致性,
这种优化都是
正确的
编译优化技术
为了方便理解, 我们用C代码来呈现优化前后的语义
- 常量传播 - 如果一个变量的取值是常数, 可以将该取值代入到引用处, 若代入后形成常量表达式, 可直接计算出该表达式的值
编译优化技术(2)
- 消除冗余操作 - 对于那些没被读出就被覆盖的赋值操作, 可将其移除
编译优化技术(3)
- 循环不变代码外提 - 对于每次循环结果都一样的代码, 可以将其提到循环之前进行一次计算
// 优化前 | 优化后
int a = f1(); | int x = f1() + 2;
for (i = 0; i < 10; i ++) { | for (i = 0; i < 10; i ++) {
int x = a + 2; | int y = f2(x);
int y = f2(x); | sum += y + i;
sum += y + i; | }
} |- 函数内联 - 对于较小的函数, 可在调用处展开, 节省函数调用的开销
其他编译优化技术: 归纳变量分析, 循环展开, 软流水, 自动并行化, 别名和指针分析等
- 可STFW了解更多细节
启用编译优化技术
可在clang的命令行中给出-O1选项来开启更多的编译优化工作:
加个volatile试试
优化等级
编译器通常会提供不同的优化等级
- 让开发者在程序性能, 代码大小和编译时间等指标中选择
- 优化等级越高, 生成程序的性能也越高, 但编译时间也越长
在gcc中, 针对程序性能, 有以下优化等级:
-O0- 默认的优化等级, 大部分优化技术都关闭-Og- 仅采取那些对调试较友好的优化技术- 能在提升程序性能的同时,
让优化后的程序仍然能保持程序原本的层次结构(如循环, 函数调用等)
- 使得生成的指令序列能较好地对应到C代码中, 方便开发者调试
- 能在提升程序性能的同时,
让优化后的程序仍然能保持程序原本的层次结构(如循环, 函数调用等)
-O1- 开启优化-O2- 开启更多优化, 大部分软件项目采用的优化等级-O3- 尝试通过生成更多的代码来换取更高的程序性能-Ofast- 甚至采取一些违反语言标准的优化策略, 来换取更高性能
优化等级(2)
gcc还提供一些面向代码大小的优化等级:
-O0- 默认的优化等级, 大部分优化技术都关闭-O1- 开启优化-Os- 面向代码大小的优化等级, 类似-O2, 但关闭那些经常增加代码大小的优化技术-Oz- 更激进的代码大小优化, 会牺牲性能
二进制文件的生成和执行
汇编
- 编译的结果是汇编代码, 即指令的符号化表示, 本质上是可读的文本
- 处理器无法理解汇编代码, 还需要将它转变成机器语言
- 根据指令集手册, 把指令的符号化表示翻译成指令的二进制编码表示
- 这个工作叫汇编(assemble), 完成这一工作的工具称为汇编器
链接
合并多个目标文件, 生成可执行文件
- 哪里来的多个目标文件呢?
让我们来看日志!
有很多crtxxx.o的文件
- crt = C runtime, C程序的运行时环境(的一部分)
- 为了向可执行文件的执行提供必要的支持
- 可以通过
objdump确认
执行
./a.out
# 通过一些配置工作, RISC-V的可执行文件也可以在本地执行
# apt-get install qemu-user qemu-user-binfmt
# qemu-riscv64 -h # 查看环境变量QEMU_LD_PREFIX的默认值
# mkdir -p /usr/gnemul/
# ln -s /usr/riscv64-linux-gnu/ /usr/gnemul/qemu-riscv64
file a.out
a.out: ELF 64-bit LSB pie executable, UCB RISC-V...
./a.out # 实际上是在QEMU模拟器中执行执行程序 = 执行指令序列
- 取指, 译码, 执行, 更新PC
- 只要将程序的指令序列放置在内存, 并让PC指向第一条指令, 处理器就会自动执行程序
编译出生成的可执行文件在外存(磁盘或SSD)中, 怎么把它放置在内存?
加载程序
在Logisim中,
通过GUI的Load Image操作将程序的指令序列读入ROM
- 本质是手动完成
将程序的指令序列放置在内存的工作
执行./a.out时, 究竟是谁完成这项工作?
- 现代操作系统中有一个称为
加载器的特殊程序, 它的工作是- 将其他可执行文件从外存读入(加载)到内存
- 并跳转到相应的程序入口处执行指令
- 加载器在加载程序的过程中, 还会检查程序的指令序列属于哪种ISA
- 如果与当前处理器的ISA不一致, 加载器通常会停止加载并报错
加载程序是程序运行之前的必要步骤, 因此加载器属于运行时环境的一部分
- 上文提到的
crtxxx.o这些目标文件, 其中就包含加载器的部分功能
运行时环境
在上述./a.out的执行过程中, 运行时环境的作用还体现在:
- 在程序执行开始前, 准备各种初始化事项
- 程序真的是从
main()开始执行吗? 至少很多C语言书籍也这么说- 但如果真的是这样, 我们在命令行中输入的程序参数,
是如何传递给
main()的argc和argv的呢?
- 但如果真的是这样, 我们在命令行中输入的程序参数,
是如何传递给
- 事实: 运行时环境在完成加载程序, 参数准备等一系列准备工作后,
才会调用
main()- 如何验证?
运行时环境(2)
- 在程序执行过程中, 提供库函数的支持
- 之前的示例代码中直接调用
printf(), 并不包含printf()的代码- 但执行
./a.out的时候确实成功通过printf()输出了信息 - 猜测:
crtxxx.o以直接或者间接方式提供了执行printf()的方法
- 但执行
- 事实: 库函数确实是运行时环境的一部分
- 如何验证?
运行时环境(3)
- 在程序执行结束后, 提供程序退出的功能
- 你可能会认为程序从
main()返回后就直接退出- 运行时环境在
main()执行之前还做了很多准备工作 - 猜测: 从
main()返回之后应该回到运行时环境
- 运行时环境在
- 事实: 运行时环境还会开展程序退出前的清理工作
- 如何验证?
用strace和gdb都能确认
光有程序本身还不能运行
- 所有支撑程序运行的功能, 都属于运行时环境的范畴
总结
预处理 -> 编译 -> 汇编 -> 链接 -> 执行
- 编译 = 词法分析 -> 语法分析 -> 语义分析 -> 中间代码生成
-> 编译优化 -> 目标代码生成
- 学会使用工具和日志理解其中的细节
- 了解常见的编译优化技术
- 常量传播, 死代码消除, 消除冗余操作, 代码强度削减, 提取公共子表达式, 循环不变代码外提, 函数内联
- 运行时环境 = 向可执行文件的执行提供必要支持的环境
- 在程序执行开始前, 准备各种初始化事项
- 在程序执行过程中, 提供库函数的支持
- 程序执行结束后, 提供程序退出的功能