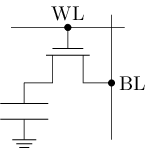
回顾: 通过SRAM存储1 bit
- 空闲: 字线加低电压时, N1和N2截止, 无读写操作
- 读出: 向两根位线加高电压(接近逻辑1), 再向字线加高电压, 此时N1和N2导通, 根据存储的信息, 其中一根位线的电压轻微下降, 可通过放大电路检测并确定哪一根位线, 从而得知存储的信息是逻辑0还是逻辑1
- 写入: 将两根字线分别设置成逻辑0和逻辑1, 再向字线加高电压, 效果类似SR锁存器的复位和置位

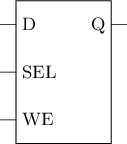
可将SRAM单元的行为抽象成一个锁存器(假设高电平有效)
- SEL有效时, Q端读出单元中数据
- SEL有效且WE有效时, 将D写入单元
通过DRAM存储1 bit
DRAM存储单元 = 1根晶体管 + 1个电容
- 晶体管 = 读写开关
- 电容 = 存储的信息
- 电量 > 某阈值, 则存储
1; 否则存储0
- 电量 > 某阈值, 则存储
- 易失性存储, 断电后信息丢失
使用电容存储信息需要解决的问题
- 随着DRAM工艺的提升, 电容越来越小
0和1之间的区别也很小, 很难直接检测
- 电容本身会漏电
- 如果什么都不做,
1就会变成0
- 如果什么都不做,
解决读出问题 - 读出放大器

读出放大器的本质 = 交叉配对反相器
- 利用负反馈特性, 将\(V_a\)和\(V_b\)的差值放大
- 只要设置\(V_a \neq V_b\),
读出放大器将进入稳态
0或1

DRAM存储单元的激活(Activate)和读出
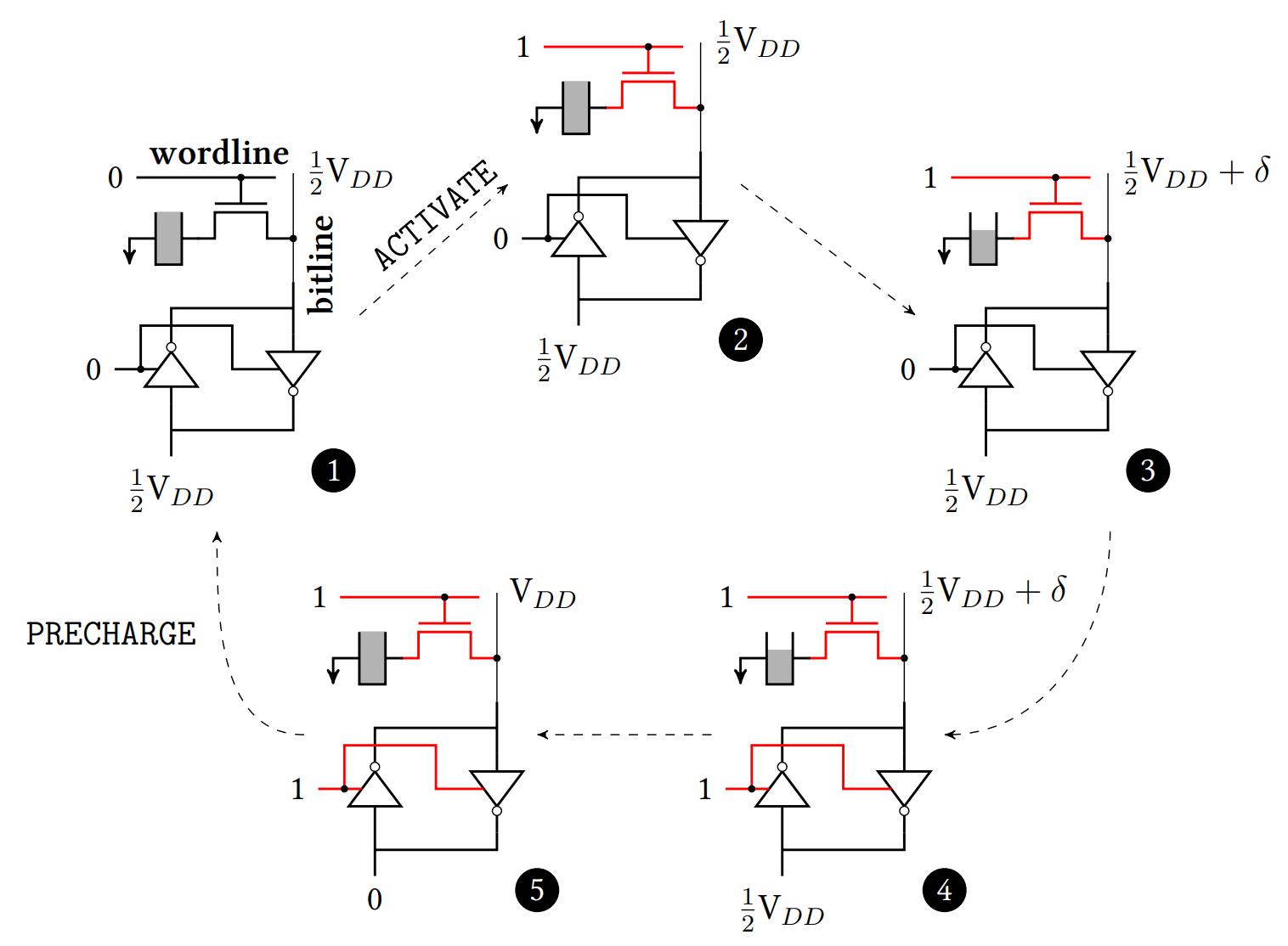
- 预充电状态: 字线未选通, 读出放大器未使能, 其两端加电压\(\frac{1}{2}V_{DD}\)
- 激活(操作1): 选通字线, 使晶体管导通, 电容与位线连通
- (假设DRAM存储单元中存
1)电容中的电荷流向位线, 使其电压升高 - 激活(操作2): 使能读出放大器, 将两端的电压差放大
- 激活状态: 读出放大器进入稳定状态,
外部电路可从中读出
1
PSRAM颗粒 = 支持定时刷新和地址译码的DRAM
型号为IS66WVS4M8ALL的PSRAM(Pseudo-SRAM)颗粒
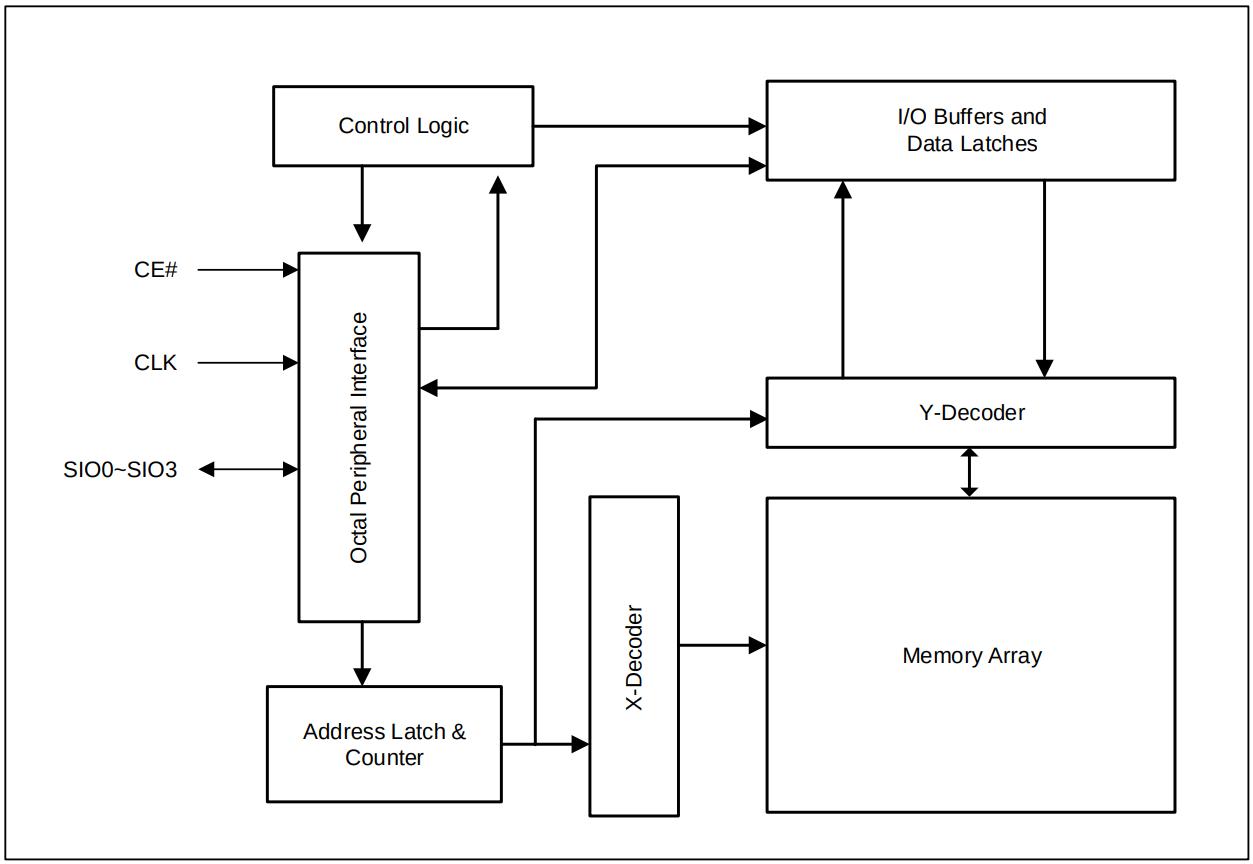
- 存储阵列 - 22根地址线, 4MB存储单元
- 地址译码器 - 行地址X和列地址Y
- 寄存器/锁存器 - 地址锁存器, 数据锁存器等
- 控制逻辑 - 命令解析, 定时刷新等
- 总线接口
使用方式与SRAM很类似: 只需给出地址, 数据和读写命令, 即可访问颗粒中的数据, 无需关心存储阵列的物理组织结构
PSRAM颗粒的总线接口
PSRAM通常提供两种接口, 可按需选择
- 并行PSRAM - 地址线和数据线全都通过引脚连出芯片
- 引脚多, 但传输带宽高
- 型号为MT38W2021AA033JZZI.X69的PSRAM颗粒有52个引脚
- 串行PSRAM - 通过串行总线协议使用少数几根信号线进行通信
- 型号为IS66WVS4M8ALL的PSRAM颗粒只有8个引脚
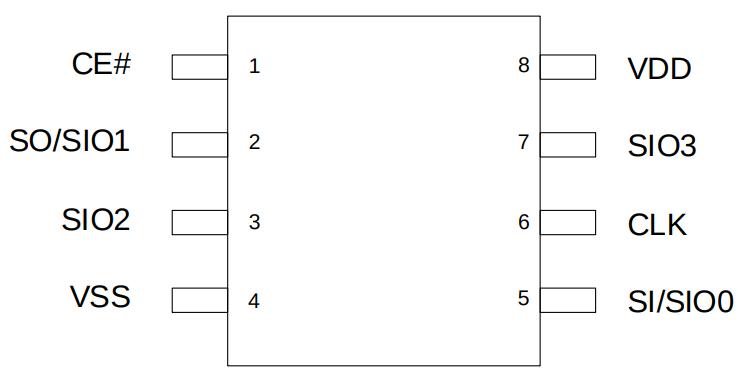
访问PSRAM颗粒中的数据
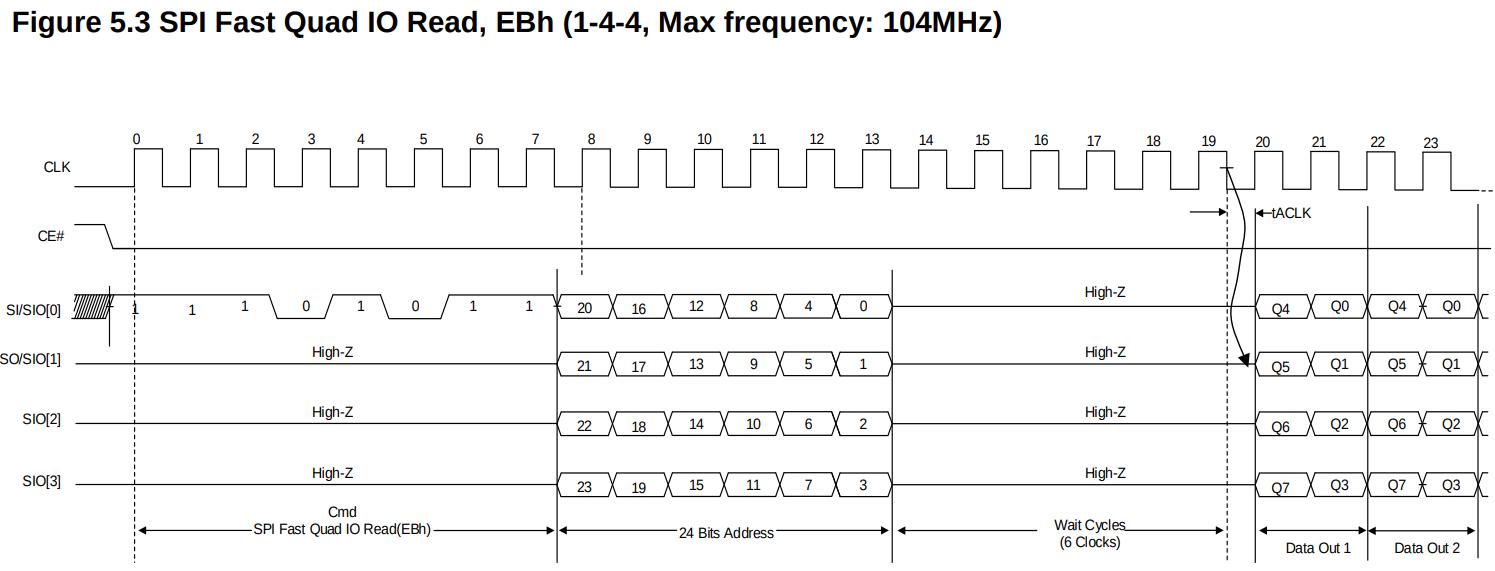
根据手册给PSRAM颗粒发送正确的指令序列
- 8位指令
EBh表示通过QSPI传输方式读数据
SDRAM颗粒的总线接口
型号为MT48LC16M16A2的SDR SDRAM颗粒有39根引脚
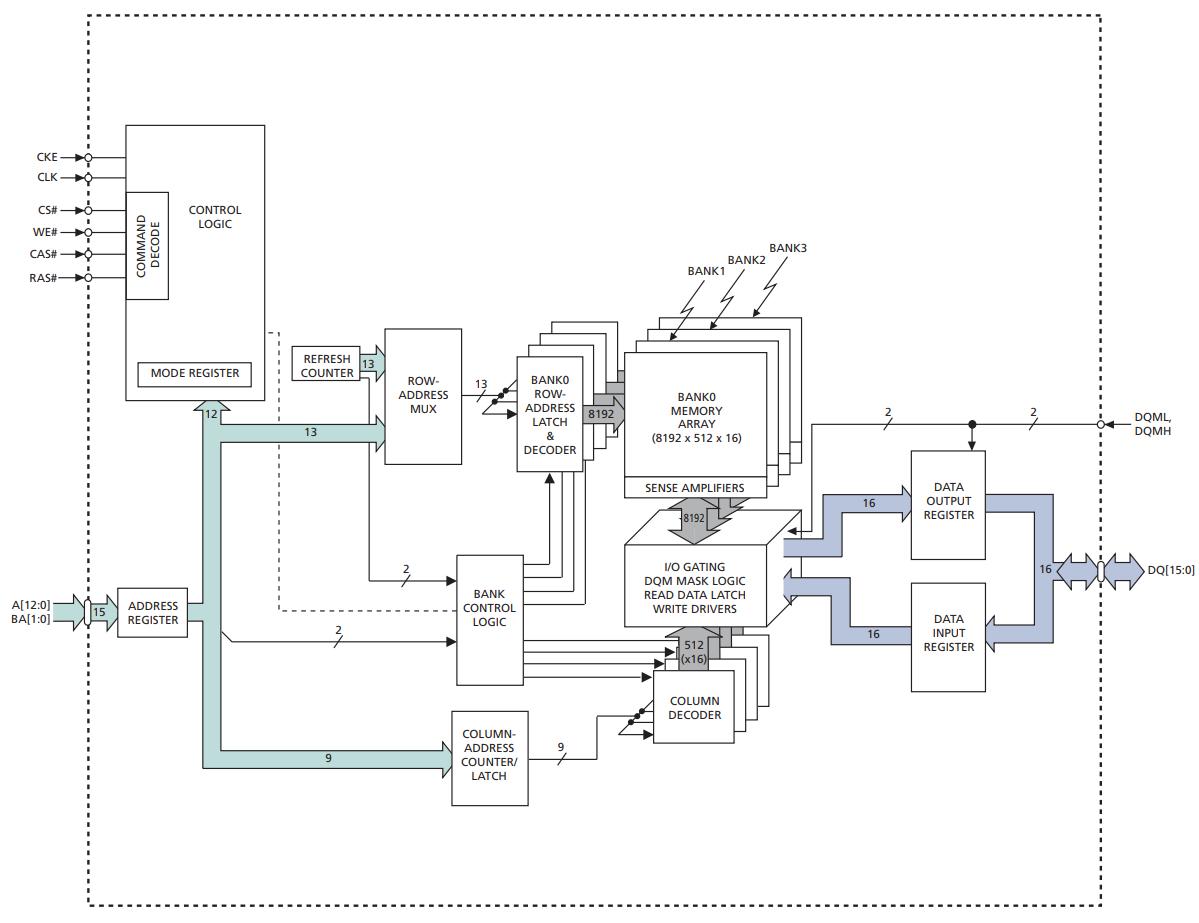
CLK,CKE- 时钟信号和时钟使能信号CS#,WE#,CAS#,#RAS- 命令信号BA[1:0]- 存储体地址A[12:0]- 地址DQ[15:0]- 数据- 一个周期能传输16位数据
DQM[1:0]- 数据掩码
SDR SDRAM颗粒的读写命令序列
逻辑上需要\(\log_2(32\mathrm{MB} / 16\mathrm{b}) = 24\)根地址线, 但地址端口只有13位, 因此地址需要分时传输
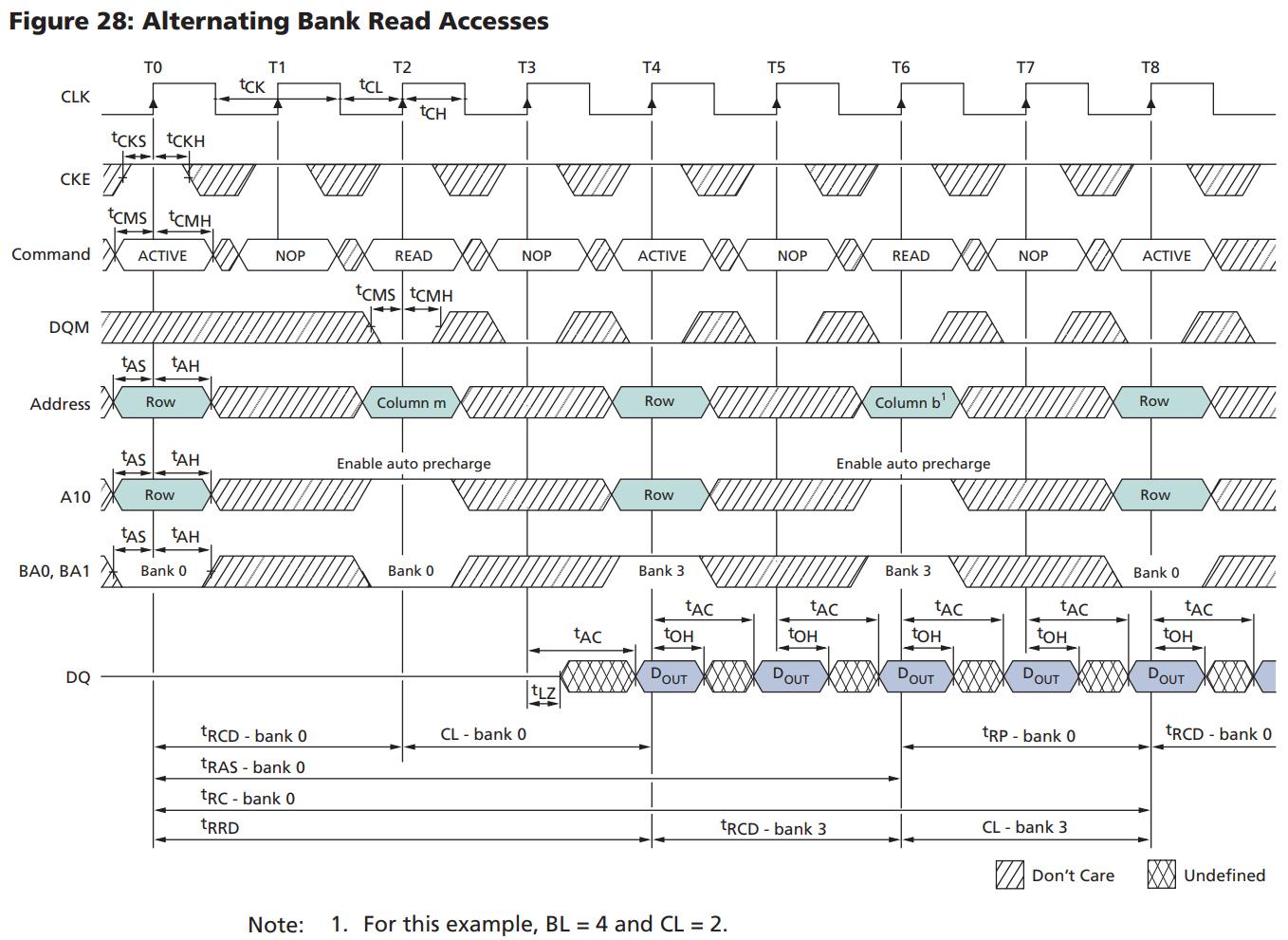
DRAM颗粒的内部结构
- 1根晶体管 + 1个电容 = 1个DRAM存储单元
- w个存储单元 = 1个存储字 = 1列

- c个存储字 = 1行

DRAM颗粒的内部结构(2)
- r行 = 1个存储体

- b个存储体 = 1个颗粒芯片
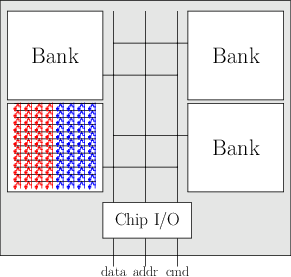
从DRAM颗粒到内存条(2)
- 位扩展: C个颗粒芯片 = 1个rank(面)
- 思想: 同时访问不同颗粒中相同的地址的数据
- 既提升存储器容量, 还提升访问带宽
- 代价: 要求数据引脚线性增长
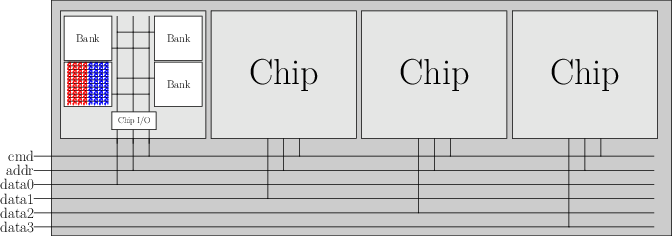
从DRAM颗粒到内存条(3)
- 字扩展: R个rank = 1个channel
- 通常内存条一侧的颗粒组成1个rank
- 思想: 将不同的地址分布到不同的颗粒上
- 通过对部分地址信号的译码, 生成不同rank的片选信号
- 地址引脚数量的增长与存储容量呈log关系
- 缺点: 无法直接提升访存带宽
- 给定一个地址, 只有一个rank能工作
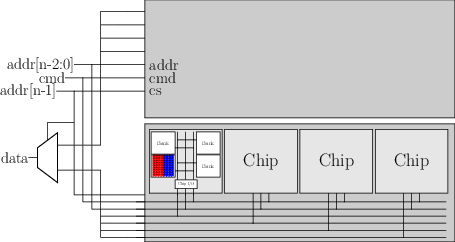
支持多通道(channel)的主板
- n个channel = 1个SoC
SoC中集成多个内存控制器, 可独立工作, 分别连接一个通道的内存条
- 主板上不同颜色的插槽表示不同的通道
- SoC引脚数量线性增长

NVBoard + ysyxSoC + NPC + RISC-V + AM + RT-Thread + FCEUX = 计算机系统!
ChipLink + FPGA = 灵活的设备扩展
若对端芯片是个FPGA, 还能获得灵活的扩展能力
- 只需要将设备控制器烧录到FPGA中, 芯片就可以访问这些设备
- 只要FPGA足够高级, 可以连接现代DDR/PCI-e
- 设备控制器有bug也不会带来灾难性的后果, 修复bug后重新烧录即可
- 缺点: 带宽低(用性能换来的灵活性)