



访问MROM存储阵列
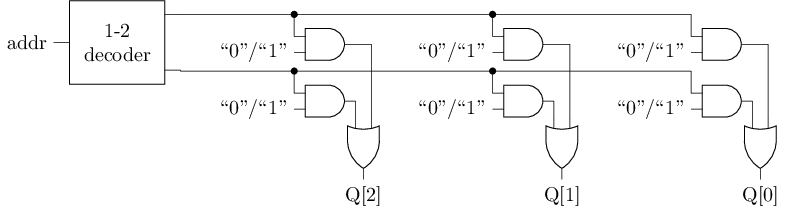
地址译码器 + 存储阵列: 本质上是一些数据输入端为常数的多路选择器
- 与门的一端输入是常数, 因此实际上这些与门也可以优化掉
// 实现类似 initial $readmemh(...) 的功能
import java.nio.file.{Files, Paths}
val binpath = "/home/ysyx/am-kernels/kernels/hello/build/hello-riscv64-npc.bin"
val wordbits = 32
val bin = Files.readAllBytes(Paths.get(binpath))
val upSize = 1 << log2Ceil(bin.size)
val bingp = (bin ++ Seq.fill(upSize - bin.size)(0.toByte)).grouped(wordbits / 8)
def byteShift(x: Byte, y: BigInt) = (x.toInt & 0xff) | (y << 8)
val wordArray = bingp.map(_.foldRight(BigInt(0))(byteShift)).toSeq
val mrom = VecInit(wordArray.map(x => x.U(wordbits.W)))
io.data := RegNext(mrom(io.addr)) // 根据地址选择MROM中的数据回顾: 通过SRAM存储1 bit
- 空闲: 字线加低电压时, N1和N2截止, 无读写操作
- 读出: 向两根位线加高电压(接近逻辑1), 再向字线加高电压, 此时N1和N2导通, 根据存储的信息, 其中一根位线的电压轻微下降, 可通过放大电路检测并确定哪一根位线, 从而得知存储的信息是逻辑0还是逻辑1
- 写入: 将两根字线分别设置成逻辑0和逻辑1, 再向字线加高电压, 效果类似SR锁存器的复位和置位

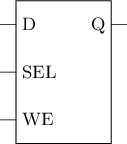
可将SRAM单元的行为抽象成一个锁存器(假设高电平有效)
- SEL有效时, Q端读出单元中数据
- SEL有效且WE有效时, 将D写入单元
回顾: 访问SRAM存储阵列
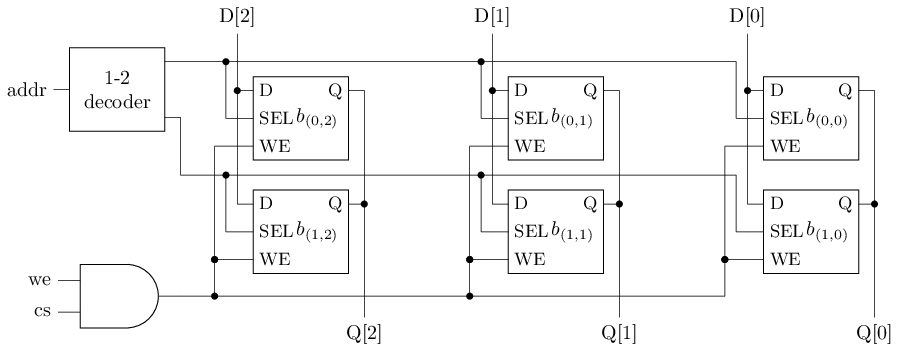
同步SRAM: 提前用D触发器存放输入端
- 引入1周期的读写延迟
总线接口和软件访问过程与MROM类似
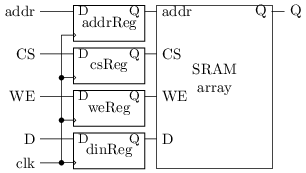
可重复编程的非易失存储器
MROM的另一个问题: 只能编程一次
val rom = VecInit(wordArray.map(x => x.U(wordbits.W)))
io.data := RegNext(rom(io.addr))想让CPU换个程序运行, 需要重新流片, 谁受得了 😂

随着存储技术的发展, 人们发明了可重复编程的flash存储器
- 更换flash中程序的代价变得可接受
- 只需要购买一个数十元的烧录器
现在人手好几个的U盘 = USB接口的flash存储器(还带一个MCU)
- 操作系统内置了USB协议的flash驱动程序, 只要插入U盘, 就能写数据
- 1999年问世的第一款U盘只有8MB, 但已经秒杀了软盘(1.44MB), 也开始逐渐替代光盘(光驱, 刻录机)
通过flash存储1 bit
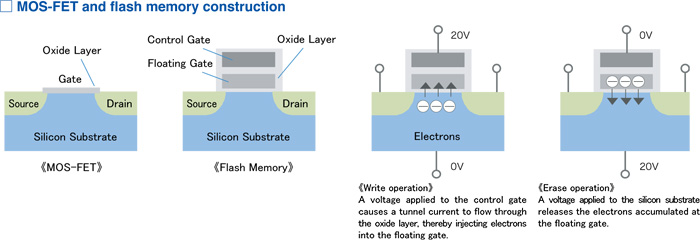
存储单元采用浮栅晶体管, 在栅极下还有一个浮栅极,
默认为状态1
- 编程 - 在栅极加大电压, 对浮栅极充电, 变为状态
0 - 读取 - 在栅极加中电压, 检测源极和漏极是否导通
- 浮栅极充电后, 会抵消部分电场效应, 导通的电压阈值更高
- 擦除 - 在衬底加大电压, 使浮栅极放电,变为状态
1- 单位: 多个存储单元(存储块)共用衬底, 存储块是最小的擦除单位
- 寿命: 放电无法100%放干净, 擦除次数太多,
读结果和充电状态
0一样
- 写入 = 擦除整个存储块 + 重新编程(写放大), 开销比读取操作大很多
flash产品对比
访问flash存储阵列
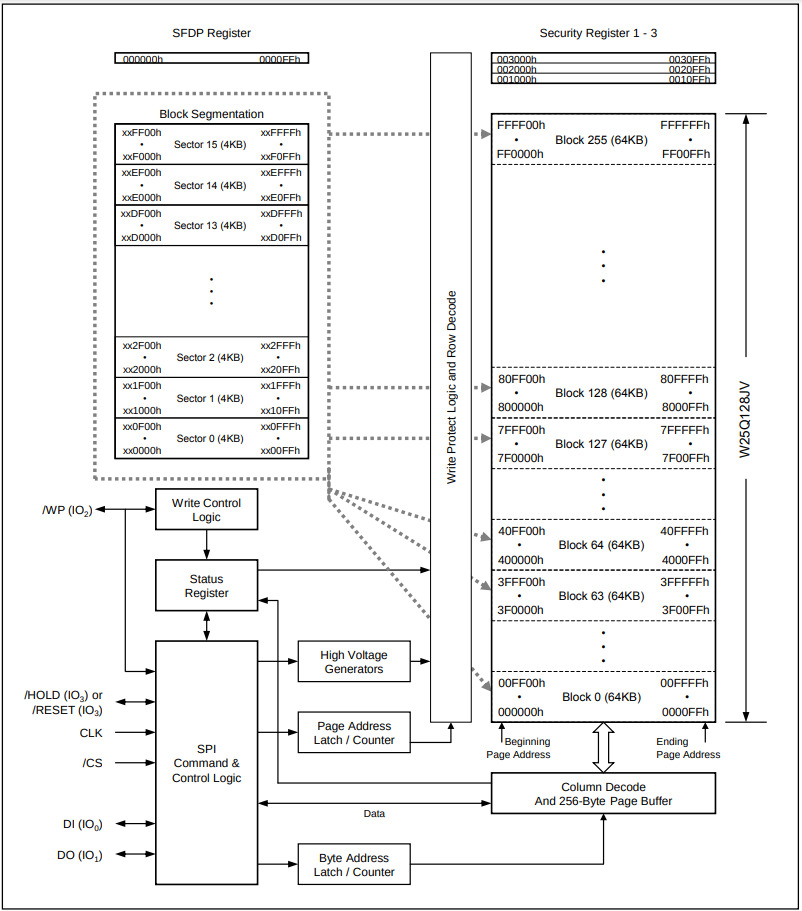
型号为W25Q128JV的NOR flash颗粒
- 存储阵列
- 24根地址线, 16MB存储单元
- 分成256个64KB块, 16个4KB扇区/块, 16个256B页/扇区
- 扇区是最小的擦除单位
- 字节是最小的读出单位, 支持随机读取
- 寄存器
- 地址寄存器, 控制寄存器(写保护等), 状态寄存器
- 颗粒内部就是一个设备控制器!
- 给flash颗粒发送命令(RTFM)
提供总线接口

flash的制造工艺和CPU不同, 两种芯片通常独立生产, 然后焊接到板卡上, 需要考虑引脚数量
- 引脚太多, 会增大芯片面积, 也增加封装成本
- 从四边出引脚(如QFP封装): 芯片边长\(=O(n)\)
- 从底部出引脚(如BGA封装): 芯片边长\(=O(\sqrt{n})\)
NOR flash通常提供两种接口, 可按需选择
- 并行NOR flash - 地址线和数据线全都通过引脚连出芯片
- 引脚多, 但传输带宽高
- 型号为MT28EW01GABA的flash颗粒有56个引脚
- 串行NOR flash - 通过串行总线协议使用少数几根信号线进行通信
- 型号为W25Q128JV的flash颗粒只有8个引脚
SPI(Serial Peripheral Interface)总线协议
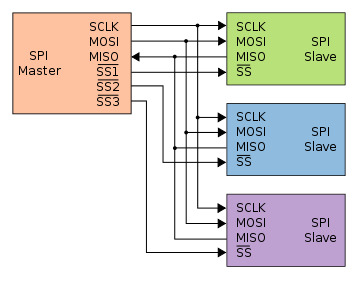
一种串行总线协议, 采用主从设备架构
- SCK - master发出的时钟信号, 1位
- SS - slave select, master发出的slave选择信号, 用于指定通信对象, 每个slave对应1位
- MOSI - master output slave input, master向slave通信的数据线, 1位
- MISO - master input slave output, slave向master通信的数据线, 1位
master通信过程(slave等待master的通信并回复):
- 通过SS选择目标slave
- 通过SCK信号向slave发送时钟脉冲, 同时将需要发送的信息转化成串行信号, 逐个比特通过MOSI信号传输给slave
- 监听MISO信号, 并将通过MISO接收到的串行信号转化成并行信息, 从而获得slave的回复
从flash颗粒中读出数据
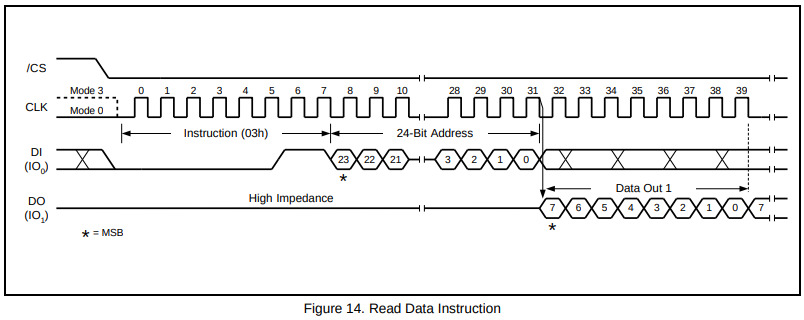
根据手册给flash颗粒发送正确的指令序列
- 8位指令
03h表示读数据, 后面加24位的存储单元地址, 通过MOSI传输 - 之后返回该存储单元的数据, 通过MISO传输
- 若SCK持续, 则依次读出后续存储单元的内容
SPI协议的实现
核心是串行/并行信号之间的转换: 发送方如何发送, 接收方如何采样
- 本质上通过移位寄存器实现
- 但还需要考虑:
- 发送的尾端(endianness) - 从高位到低位, 还是从低位到高位
- 时钟相位(clock phase) - 发送/采样发生在SCK上升沿, 还是下降沿
- 时钟极性(clock polarity) - SCK空闲时是高电平, 还是低电平
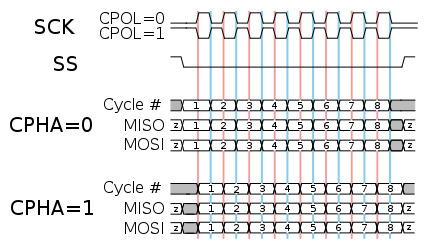
- SCK起到同步作用, 双方共同约定上述内容, 并在RTL层次实现约定
- 不同slave可能有不同约定, 因此master需要可配
- 具体约定RTFM
运行flash中的程序
可以先通过flash_read()将程序加载到SRAM,
然后跳转到SRAM中的程序执行
我们已经把程序烧录到flash中了, 可以直接从flash中取指令执行吗?
flash_read()也是程序的一部分, 其指令序列也烧录在flash中![]()
- 想要从flash中取出指令, 需要先执行
flash_read() - 想要执行
flash_read(), 需要先从flash中取出其指令 - 变成了一个 “鸡和蛋”的循环依赖问题 😂
- 想要从flash中取出指令, 需要先执行

问题的根源: 取指令是硬件层的行为, 不应该依赖软件函数来实现
- 应在硬件层实现
flash_read()的功能!