



引言
大家应该已经领教到bug的厉害了
今天来给大家揭秘
- 为什么调bug这么难?
- 应该如何用正确的姿势来调bug?
调试理论
码农的日常
需求 -> 设计 -> 代码 -> 运行结果
- 理解需求
- 提出设计方案解决需求
- 根据设计方案编写代码
- 运行代码得到结果, 实现需求
- 理想: 写完代码, 一键编译运行, 最后结果正确!
- 主宰代码世界的沉浮
- 现实: 结果不正确!
- 明明是你在调bug, 有时却分明感觉是bug在调你
- 但你是否思考过, bug是如何产生的?
调bug是码农的宿命
需求 -> 设计 -> 代码 -> 运行结果
- 面对现实: 每一步都可能出错
- 需求理解有误, 解决的是另一个需求
- 设计方案有误, 无法解决需求
- 编码有误, 和设计方案不一致
- 表面上看都是: 给一个输入, 程序运行出错
- 于是你需要调试
进一步理解程序出错的过程
需求 -> 设计 -> 代码 -> Fault -> Error -> Failure
- 软件工程领域中的三种 “错误”
- Fault - 有bug的代码
- 如数组访问越界, 根据C语言标准, 这是UB
- Error - 程序运行时刻的非预期状态
- 如某些内存的值被错误改写
- Failure - 可观测的致命结果
- 如输出乱码/assert失败/段错误等
- Fault - 有bug的代码
调试 = 看着Failure, 找到Fault
调试并不容易 - bug视角
需求 -> 设计 -> 代码 -> Fault -> Error -> Failure
代码 =(小错误)=> Fault =(也许?)=> Error =(也许马上?)=> Failure
- 写代码时手滑/眼瞎/脑抽, 写出Fault
- 代码不知道什么时候运行到Fault的位置
- 程序因为Fault进入Error状态, 也不一定马上观测到
- 观测到Failure的时候, 可能离Fault很远了
调试并不容易 - 程序员视角
需求 -> 设计 -> 代码 -> Fault -> Error -> Failure
Start Fault Failure
+---------------------+------------------+
|------ Error -----|程序员能做的
- 看到Failure, 知道肯定有问题
- 可以检查程序的某个状态是否正确
- 程序是个状态机: \(S = \{<PC, v_1, v_2, ...>\}\)
但检查这件事并不容易
- 需要程序员来模拟一个应该正确的状态机的转移
- 人肉DiffTest
- 而且还不知道Fault在哪里
- 看上去都 “没什么问题”, 只能慢慢定位
来自调试理论的启发
好一点的定位方法 - 二分调试理论
for (L = Start, R = Failure; L < R; ) {
S = L和R的中间点;
if (check_state(S) == GOOD) L = S; else R = S;
}第一个Error状态\(S = min_{s}(check\_state(s) == BAD)\)即为Fault
但这种方法扩展性很低: 几百行的小程序还行, 复杂的项目就搞不定了
- 时间上 - 并没有缩短Fault和Failure之间的距离
- 空间上 - 程序并不是线性的,
人工判断
check_state(S)也不容易- 循环, 递归, 函数指针的间接调用…
- 计算机系统抽象层: 程序, 运行时环境, 硬件
- 如果涉及OS, 还有进程切换, 虚存管理, 存储栈…
- 如果自己设计硬件, 还有外设, 中断异常, 虚存, 总线, 缓存, 流水线…
科学的调试方法 = 从时空角度高效地解决上述挑战
缩短Fault和Failure之间的距离
0. 最重要的是调试公理
机器永远是对的
程序出错了, 不要怀疑真机的硬件/操作系统/编译器, 先怀疑自己的代码
未测试代码永远是错的
bug往往出现在那些你觉得 “应该没问题”的地方
调试公理告诉大家: 要解决问题, 先摆正心态
- 无论你觉得自己多牛X, 机器面前人人平等: 出错了都得调试
- 你可以怀疑机器, 但需要通过调试给出足够专业的证据
- 反例: 某ACM队员怒摔键盘, 怀疑编译器有bug
1. RTFM: 需求 -> 设计
需求 -> 设计 -> 代码 -> Fault -> Error -> Failure
你想当然地认为
- 某些指令的结果需要零扩展/符号扩展
- 某些标志应该更新/不更新
- 某个库函数的功能/返回值肯定是xxx
调这种bug的唯一方法 - 仔细RTFM, 确认自己正确理解需求
- 开销很低, 但能节省好几天的调试时间
- “一生一芯”的真实案例: 某同学实现printf, 真的因为少看了手册中的一句话, 调了4天
2. 添加断言: Error -> Failure
回顾防御性编程: assert - 将预期的正确行为直接写到程序中
- 调试理论层面的意义
- 如果捕捉到Error, 通过终止程序马上转变为可观测的Failure
- 避免Error继续传播, 造成更难理解的Failure
- 能够大幅提升调试效率
segmentation fault->yemu.c:27: main: ...- 超强的assert - DiffTest
一些好的编程习惯
- 访问数组前先检查下标
assert(idx < ARRAY_SIZE); - 指针解引用前先
assert(p != NULL); switch-case不存在默认情况时default: assert(0);
NEMU中的断言
// nemu/src/isa/riscv64/local-include/reg.h
static inline int check_reg_idx(int idx) {
IFDEF(CONFIG_RT_CHECK, assert(idx >= 0 && idx < 32));
return idx;
}这个assert()看上去很蠢, 但你能100%保证它不会失败吗?
// nemu/src/memory/paddr.c
static void out_of_bound(paddr_t addr) {
panic("address = " FMT_PADDR " is out of bound of pmem [" FMT_PADDR ", "
FMT_PADDR "] at pc = " FMT_WORD, addr, PMEM_LEFT, PMEM_RIGHT, cpu.pc);
}物理内存越界是PA2中相对难调的一类错误
但如果去掉这些检查, 把Error放过去, 将会发生什么?
- 感到后怕了吧?
编译器福利 - sanitizer
让编译器自动插入assert, 拦截常见的非预期行为
- AddressSanitizer - 检查指针越界, use-after-free
- ThreadSanitizer - 检查多线程数据竞争
- LeakSanitizer - 检查内存泄漏
- UndefinedBehaviorSanitizer - 检查UB
- 还能检查指针的比较和相减
打开后程序运行效率有所下降
- 但调试的时候非常值得, 躺着就能让工具帮你找bug
man gcc查看具体用法
3. 进行测试: Fault -> Error
测试需要测试用例
- 单元测试 - 与具体模块相关, 自行编写
- 集成测试 - AM上的各种小规模程序, riscv-tests
- 系统测试 - 超级玛丽, RT-Thread, 仙剑
写单元测试是份累活
- 枚举所有指令类型在流水线中全排列的情况, 超过上万种
- 你不会愿意一个个手写出来的 😂
- 需要软件工具来辅助我们
- 全遍历测试 - 写个程序/脚本, 生成全排列的测试用例
- 随机测试 - 如riscv-torture可以产生随机的riscv指令序列
- 对于复杂的设计: 验证空间 vs. 边界情况覆盖率
- 需要更好的规则指导, 这是一个前沿的研究问题
4. 使用lint工具: Fault -> Failure
通过分析代码(静态程序分析), 提示编译通过但有潜在错误风险的代码
- 在编译阶段消灭Fault!
- 虽然无法捕捉所有Fault, 但非常划算
- 编译器一般自带lint工具
- gcc中的
-Wall,-Werror - clang中的analyzer
- gcc中的
- 电路仿真器也有lint工具
- Verilator也有
-Wall - 还有专门进行linting的商业工具
- Verilator也有
- 综合工具的检查更严格
- 规范的芯片设计流程一定要清除工具报告的所有warning
- 任何已知风险带来的后果可能都是无法承担的
Chisel开发流程中的检查
- Scala编译错误
- 语法错, 静态类型检查错, 继承错
- Scala运行错误
- 引用null对象, 动态类型检查错, require断言失败
- Chisel编译错误
- 连线方向错, Chisel类型/Chisel对象检查错
- FIRRTL编译错误
- 未连接信号, 组合回环
- 电路仿真错误
- assert断言失败, 电路功能错
核心思想: 尽量让编译过程拦截错误(甚至是设计语义), 避免其进入仿真
- 通过编译的代码, 更大概率是正确的代码
5. 正确的编程模式: 少写Fault
回顾: 正确的代码 != 好代码
- 好代码更大概率是正确的
好代码的两条重要准则
- 不言自明 - 仅看代码就能明白是做什么的(specification)
- 不言自证 - 仅看代码就能验证实现是对的(verification)
使用正确的编程模式写出好代码
- 防御性编程 - 通过
assert检查非预期行为 - 减少代码中的隐含依赖 - 使得 “打破依赖”不会发生
- 头文件 + 源文件
- 编写可复用的代码 - 不要Copy-Paste
- 使用合适的语言特性 - 把细节交给语言规范和编译器
NEMU的 “抄手册宏”INSTPAT
用它来实现指令, 只需要无脑抄手册 😂
- 只要没抄错, 基本上是对的
有同学用verilog实现INSTPAT
- 看得出来花了不少时间, 但这种想法很值得鼓励
- 久而久之就会追求如何写出更好的代码
技术债(Technical Debt)
每当你写出难以维护的代码, 将来调试的时候都是要还的.
应对程序的复杂性
判断程序的状态是否正确
程序是个状态机: \(S = \{<PC, v_1, v_2, ...>\}\)
- 但这个状态机很大, 人工判断状态的正确性需要很多时间
软件工程领域的一个观察: Error通常只会影响程序中很少一部分的状态
启发: 没有必要观察整个状态空间, 通常只需观察若干关键变量即可
为了提升调试效率, 我们需要从不同层次理解程序的状态和行为
- 通过高层的大致信息, 快速缩小观察的范围
- 通过底层的详细信息, 仔细分析状态的变化
所以我们需要不同层次的trace!
自顶向下理解程序行为
- ftrace - 函数调用层次, 理解程序的大体行为
- itrace - 指令执行层次, 理解指令级别的行为
- mtrace - 访存的踪迹
- dtrace - 设备访问的踪迹
- sdb - 灵活细致地检查客户程序的状态
si- 细粒度的状态转移info r/x- 检查\(R\), \(M\)- 监视点 - 捕捉某状态发生变化的时刻
sdb与gdb结合使用
- 先用sdb定位到出错点附近
- 再用gdb观察NEMU的细节行为
可用类似方法调试硬件
- 通过DiffTest在程序级别定位错误时刻
- 通过各种trace工具和sdb在模块级别定位错误的空间范围
- 通过波形在信号级别进行细致分析
随着处理器复杂度上升, 添加更多trace将更容易理解模块级行为
- pipeline trace - 理解流水线的行为
- CSR trace - 记录CSR状态的变化
- cache trace - 理解cache的状态
- bus trace - 理解总线的事务处理细节
波形和trace结合使用
- 波形包含所有信息, 但可读性差: 需要人工解析信号级别的信息
- trace包含大多时候我们感兴趣的信息, 易读但不全面
- 通过脚本处理trace, 进一步提升可读性
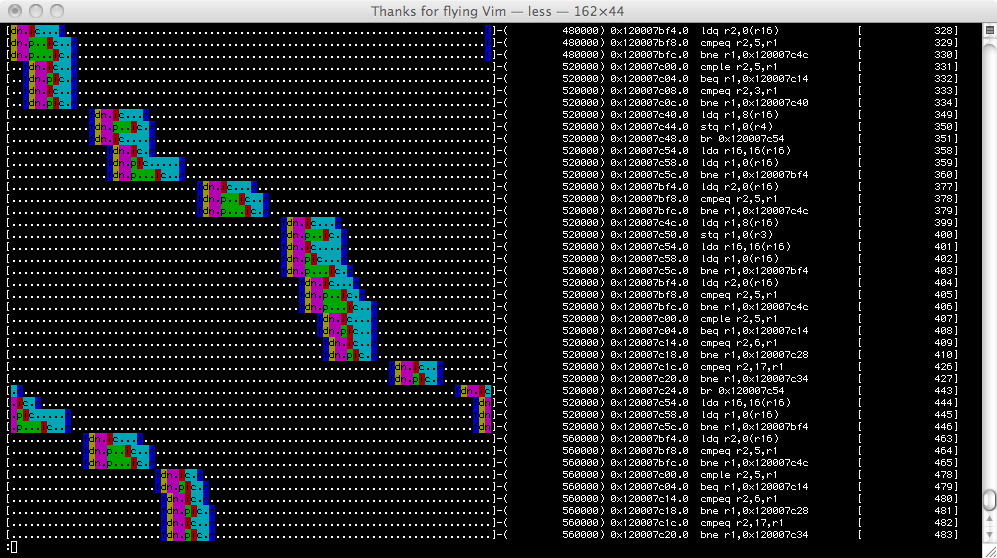
实际中的工具
gem5中的O3 Pipeline Viewer通过脚本对trace文件可视化
- 通用的trace工具,
apt可一键安装blktrace,dnstracer,extrace,fatrace,ltrace,mutrace,nfstrace,strace,tcptrace,traceroute,xtrace
- 大部分工具也自带高层行为的trace, 通过
-v等输出make,gcc,ssh
性能bug
性能bug
程序的运行结果正确, 但就是跑得慢 - performance bug
- 你需要知道程序的运行时间都花在哪里
火焰图(Flame Graph) - perf信息的可视化
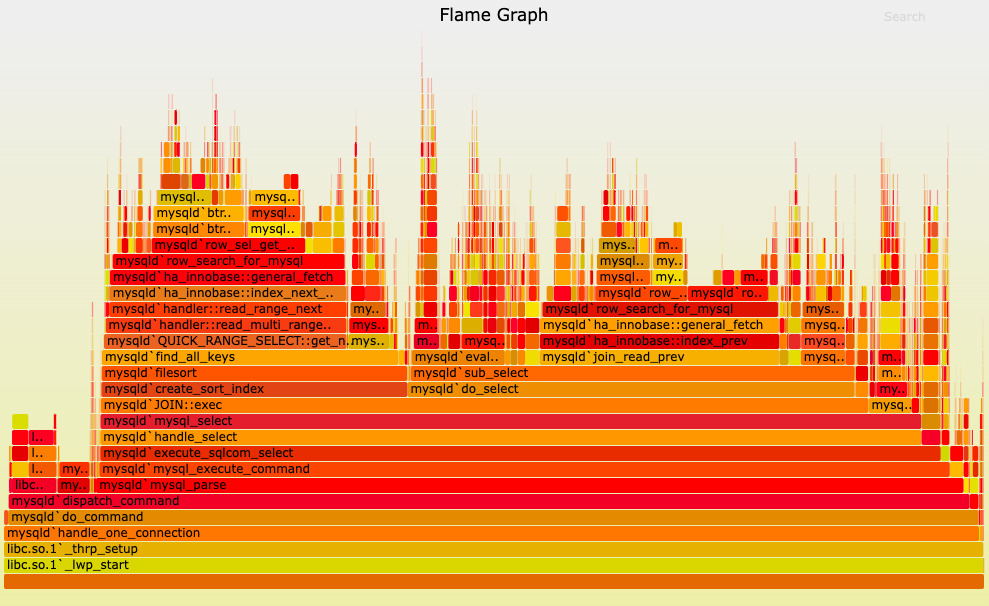
第四期有同学通过火焰图分析出verilator仿真变慢的原因, 优化verilog设计后仿真效率提升10倍!
处理器的自顶向下性能分析方法
面向处理器体系结构优化的profiling
- Intel的现代x86处理器中有上千个性能计数器
- 例如访存等待周期数, 无指令执行的周期数…
- 通过分析这些计数器, 定位处理器的性能瓶颈
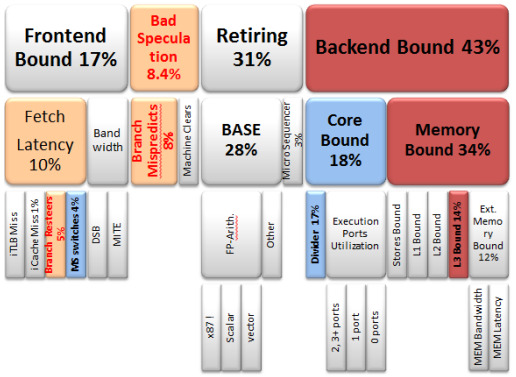
A Top-Down Method for Performance Analysis and Counters Architecture. Ahmad Yasin. In IEEE International Symposium on Performance Analysis of Systems and Software, ISPASS 2014.
反思和总结
残酷的现实
道理我都懂, 但我就是不知道如何下手
如果一个bug要调好几天, 或者长时间没有新的认识, 说明
- 要么基础知识掌握不够深入
- 要么不理解关键代码的行为
- 要么调试的方法不科学
你需要意识到, 当你觉得调试非常困难, 并不是bug本身非常困难
- 而是因为你之前的学习方法和心态不对
归根到底是心态问题
- 这个文件/函数/代码好像不看也行, 关我P事
- 有同学抱怨NPC上跑1000轮coremark很慢, 却不愿意RTFSC看看怎么把1000改小一些
- 这个bug我搞不定, 赶紧找个大佬指导一下
- 没有大佬, 就无法解决问题
- 这些工具不实现也无所谓
- 我们见过不少同学, 因为跳过工具部分而沾沾自喜
- 觉得既节省了时间, 还能把bug调出来, 说明自己技术能力很好
- 如果你调了一个月, 更应该反思如何避免下次又调一个月
- 思维的局限: 宁愿当工具人, 都不想当一个写工具的人让工作更舒适
- RTL工程师: 有波形为什么还看trace?
- 我们见过不少同学, 因为跳过工具部分而沾沾自喜
这不是做大项目该有的心态 - 课程作业/小项目确实无所谓
从小事开始锻炼心态
- 尽最大努力理解项目中的每一处细节
- 这个选项我没见过, 让我RTFM学习一下
- 这个程序跑起来了, 我来RTFSC看看它具体做了些什么
- 了解每种工具的优势和局限性
- 我第一次使用gdb, 让我STFW找个教程试试
- 我觉得这里的
printf()多输出xxx可以帮助我调试
- 感到不爽的时候,
一定有工具/方法帮你解决问题
- 不知道自己改了哪些代码 -> git
- 批量的重复性工作 -> 脚本
- 程序跑很多指令, 不知道哪一条错了 -> DiffTest
- 不知道是软件bug还是硬件bug -> 各种native平台
我们设置预学习阶段, 就是希望大家端正心态和学习习惯
成为专业码农
- 要熟悉项目了 -> STFW/RTFM/RTFSC, 尝试理解一切细节
- 要写代码了
- 仔细RTFM, 正确理解需求
- 编写可读, 可维护, 易验证的代码(不言自明, 不言自证)
- 用lint工具检查代码
- 进行充分的测试
- 添加充分的断言
- 要调试了
- 默念 “机器永远是对的/未测试代码永远是错的”
- sanitizer, trace, printf, gdb, …
- 平时 -> 用正确的工具/方法做事情
- 感到不爽了 -> 找正确的工具/搭基础设施
- 调试了很长时间 -> 反思应该如何改进
这一切, 源于对自己的要求
- 冠冕堂皇的大道理谁都不爱听
- 大家也都处于血气方刚的年纪
对于大部分初学者, “吃亏学习法”还是很有用的
- 吃亏了才会去反思
但为了让你意识到自己吃了亏, 你需要提高对自己的要求
- 这是一切改进的源头, 也是主动学习的基础
如果你能持续找到对自己不满意的地方, 这个过程中掉过的坑, 吃过的亏, 就值得了