



引言
我们已经了解RISC-V指令集
本次课内容:
- 单周期处理器的微结构设计
- 指令和功能单元
- 编写可读可维护的RTL代码
单周期处理器的微结构设计
单周期处理器
回顾指令周期: 执行一条指令的步骤
- 取指(fetch): 从PC所指示的内存位置读取一条指令
- 译码(decode): 按照手册解析指令的操作码(opcode)和操作数(operand)
- 执行(execute): 按解析出的操作码, 对操作数进行处理
- 更新PC: 让PC指向下一条指令
单周期处理器的思想: 一个周期内完成上述步骤
回顾: YPC
import chisel3._
import chisel3.util._
import chisel3.util.experimental.loadMemoryFromFileInline
class YPC extends Module {
val io = IO(new Bundle{ val halt = Output(Bool()) })
val R = Mem(32, UInt(32.W))
val PC = RegInit(0.U(32.W))
val M = Mem(1024 / 4, UInt(32.W))
def Rread(idx: UInt) = Mux(idx === 0.U, 0.U(32.W), R(idx))
loadMemoryFromFileInline(M, "prog.hex")
val Ibundle = new Bundle {
val imm11_0 = UInt(12.W)
val rs1 = UInt( 5.W)
val funct3 = UInt( 3.W)
val rd = UInt( 5.W)
val opcode = UInt( 7.W)
}
def SignEXT(imm11_0: UInt) = Cat(Fill(20, imm11_0(11)), imm11_0)
val inst = M(PC(31, 2)).asTypeOf(Ibundle)
val isAddi = (inst.opcode === "b0010011".U) && (inst.funct3 === "b000".U)
val isEbreak = inst.asUInt === "x00100073".U
assert(isAddi || isEbreak, "Invalid instruction 0x%x", inst.asUInt)
val rs1Val = Rread(Mux(isEbreak, 10.U(5.W), inst.rs1))
val rs2Val = Rread(Mux(isEbreak, 11.U(5.W), 0.U(5.W)))
when (isAddi) { R(inst.rd) := rs1Val + SignEXT(inst.imm11_0) }
when (isEbreak && (rs1Val === 0.U)) { printf("%c", rs2Val(7,0)) }
io.halt := isEbreak && (rs1Val === 1.U)
PC := PC + 4.U
}设计单周期处理器
- 状态 - 时序逻辑电路
- \(PC\) - 单个寄存器, 初值为0
- \(R\) - 通用寄存器组, 可寻址, 用带使能的D触发器搭建存储器
- \(M\) - 内存, 可寻址, 容量更大的存储器
- 状态转移 - 组合逻辑电路
- 数据通路 - 数据移动和计算所经过的路径及相关部件
- 例如\(R\), \(M\), 选择器, 加法器, 移位器, 乘法器等
- 控制信号 - 控制数据在数据通路中如何移动
- 例如执行加法指令时, 需要将数据送入加法器, 而不是乘法器
- 数据通路 - 数据移动和计算所经过的路径及相关部件
在类似YEMU的模拟器中也存在数据通路和控制信号的概念
- 只不过一部分融合到C语言特性里面了
- 整个
inst_cycle()可以看作是数据通路 - 其中的
if,switch-case充当了控制信号的作用
- 整个
设计数据通路和控制信号
- 分析功能需求
- 确定相应的部件, 并根据需求将其连接成完整的数据通路
- 确定用于控制数据通路的控制信号
- 汇总控制信号, 给出每种状态下的所有控制信号的取值
- 得到从状态到控制信号的逻辑表达式, 根据其设计控制信号
以上是通用的设计方法, 可用于设计任意模块, 例如总线, cache
- 让
功能需求=指令行为, 就得到单周期处理器设计流程- 指令行为可RTFM得知
- 通过硬件上的电路(即功能单元)支持指令的行为
实际情况中需求往往是变化的
- 产品经理/客户/导师: 加个xxx功能
- 你的内心: @#%!%@%#$!&%
- 你的回答: 好的
- 哪天你心血来潮想跑Linux, 发现需要实现虚存和一大堆CSR
- 你想跑Debian, 发现又需要添加很多压缩指令
- 即使你现在知道将来的需求, 也很难一开始就考虑清楚所有细节
这对大家提出更高的要求
- 学会将需求转换为设计方案 - 画图纸
- 如果仅仅会看着电路图写代码, 很快就要被AI取代了 😂
- 学会编写易维护易扩展的RTL代码
- 新需求到来时更容易拥抱变化
从现在开始锻炼
很多书籍把图画好, 甚至把代码写好, 直接阅读这类书籍并不能帮助大家锻炼上述能力
- 现在看这些书, 你会陷入 “代码就应该一次写好, 将来不用改”的幻想, 无法正确认识训练的意义
- 总有一天你要在没图没参考代码的情况下, 按认知规律迭代实现需求
- 如果你没有锻炼出上述能力, 将来面对真实需求, 只会更困难
- 一种自检方式: 如果不看这些书籍, 我能否独立写出正确的代码?
如果你之前从未了解过单周期处理器设计, 强烈建议先不要看书
- 把单周期处理器设计当做一个未知的新问题来解决
- 可以从YPC开始, 尝试画出电路结构图, 并思考如何添加新指令
- 自己思考过, 动手做过, 再回过头来看相关书籍, 对比双方的方案
- 双方的方案有什么不同? 究竟谁的方案(在某些情况下)更好? 为什么?
从指令需求到功能单元
加法指令 -> 加法器
回顾: 行波进位加法器(Ripple-Carry Adder, RCA)
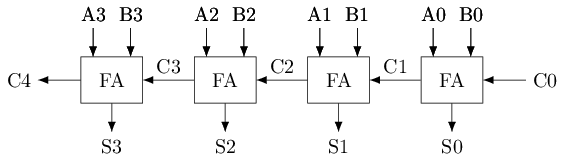
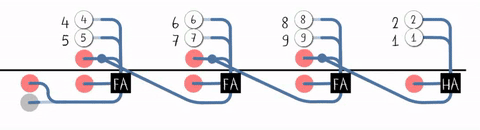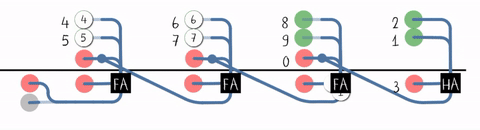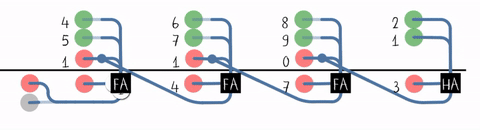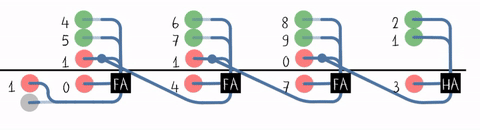
近距离观察进位
新的解读
- 若G为1, 则Cout必定为1
- G = A & B可用于产生(Generate)当前位的进位
- 若G为0且P为1, 则Cout与Cin相同
- P = A ^ B可用于将低位进位传播(Propagate)到当前位的进位输出
对于4位加法器
更快的进位计算方法
C1 = G0 | (C0 & P0)
C2 = G1 | (C1 & P1) = G1 | ((G0 | (C0 & P0)) & P1) = G1 | (G0 & P1) | (C0 & P0 & P1)
C3 = G2 | (C2 & P2) = G2 | (G1 & P2) | (G0 & P1 & P2) | (C0 & P0 & P1 & P2)
C4 = G3 | (G2 & P3) | (G1 & P2 & P3) | (G0 & P1 & P2 & P3) | (C0 & P0 & P1 & P2 & P3)G和P只依赖加法器的输入, 不依赖每一位的进位!
设\(D(s)\)为传播信号\(s\)所需的门延迟级数, 设\(d\)为1级门延迟
- \(D(G_i) = D(P_i) = d\)
- \(D(C_i) = 3d, i > 1\)(多1级与门和1级或门)
- \(D(S_i) = D(A_i \oplus B_i \oplus C_i) = D(C_i) + d = 4d, i > 1\)
这就是先行进位加法器(Carry-Lookahead Adder, CLA)
- \(D(C_i) < D(S_i)\)
CLA vs. RCA
C4 = (A3 & B3) | (C3 & (A3 ^ B3))
= (A3 & B3) | (((A2 & B2) | (C2 & (A2 ^ B2))) & (A3 ^ B3)) = ...
= (A3 & B3) | (((A2 & B2) | (((A1 & B1) | (((A0 & B0) | (C0 & (A0 ^ B0)))
& (A1 & B1))) & (A2 ^ B2))) & (A3 ^ B3))4位RCA中4个FA级联, 每经过一个FA计算\(C_i\)需额外\(2d\)
- \(D(C_1) = 3d\)
- \(D(C_i) = D(C_1) + 2d * (i - 1) = (2i + 1)d, i > 1\)
- \(D(S_i) = D(C_i) + d = 2(i+1)d, i >
1\)
- \(D(S_3) = 8d < 9d = D(C_4)\)

分组CLA
C4 = G3 | (G2 & P3) | (G1 & P2 & P3) | (G0 & P1 & P2 & P3) | (C0 & P0 & P1 & P2 & P3)
C64 = G63 | (G62 & P63) | (G61 & P62 & P63) | (G60 & P61 & P62 & P63) | ...原则上来说, 位宽更大的CLA也可以通过上述方式搭建
- \(D(C_i)=3d, i > 1\)同样成立
- 但与门和或门输入太多, 延迟也会增加
4位CLA
A3B3 A2B2 A1B1 A0B0
|| || || ||
+---------------------------------------------+
S0<--|------||--------||--------||------+ || |
S1<--|------||--------||------+ || | || |
S2<--|------||------+ || | || | || |
S3<--|-+ VV | VV | VV | VV |
| | +----+ +----+ +----+ +----+ |
| +-| FA |<-+ | FA |<-+ | FA |<-+ | FA |<--+--|--C0
| +----+ | +----+ | +----+ | +----+ | |
| || | || | || | || | |
| VV | VV | VV | VV | |
| +------------------------------------+ | |
| | P3G3 C3 P2G2 C2 P1G1 C1 P0G0| | |
C4<--|--|C4 Carry Lookahead Unit(CLU) |<-+ |
| | PG GG | |
| +------------------------------------+ |
| 4-bit Carry-Lookahead Adder | | |
+---------------------------------------------+
| |
V V16位CLA
A/B12~15 A/B8~11 A/B4~7 A/B0~3
|| || || ||
+---------------------------------------------+
S0~3 <--|------||--------||--------||------+ || |
S4~7 <--|------||--------||------+ || | || |
S8~11 <--|------||------+ || | || | || |
S12~15<--|-+ VV | VV | VV | VV |
| | +----+ +----+ +----+ +----+ |
| +-|4CLA|<-+ |4CLA|<-+ |4CLA|<-+ |4CLA|<--+--|--C0
| +----+ | +----+ | +----+ | +----+ | |
| || | || | || | || | |
| VV | VV | VV | VV | |
| +------------------------------------+ | |
| | P3G3 C12 P2G2 C8 P1G1 C4 P0G0| | |
C16 <--|--|C16 Carry Lookahead Unit(CLU) |<-+ |
| | PG GG | |
| +------------------------------------+ |
| 16-bit Carry-Lookahead Adder | | |
+---------------------------------------------+
| |
V V同理, 64位CLA可以通过4个16位CLA和1个CLU组合搭建
16位CLA的延迟
- 每个FA: \(D(P) = D(G) = d\)
- 每个4位CLA: \(D(PG) = 2d, D(GG) = 3d\)
- 组间进位\(D(C_{\{4, 8, 12, 16\}}) = 5d\)
- 组内进位
- \(D(C_{\{1,2,3\}}) = 3d\)
- \(D(C_{\{5,6,7,9,10,11,13,14,15\}}) = 7d\)
- 计算S
- \(D(S_0) = d\)
- \(D(S_{\{1,2,3\}}) = 4d\)
- \(D(S_{\{4, 8, 12\}}) = 6d\)
- \(D(S_{\{5,6,7,9,10,11,13,14,15\}}) = 8d\)
A/B12~15 A/B8~11 A/B4~7 A/B0~3
|| || || ||
+---------------------------------------------+
S0~3 <--|------||--------||--------||------+ || |
S4~7 <--|------||--------||------+ || | || |
S8~11 <--|------||------+ || | || | || |
S12~15<--|-+ VV | VV | VV | VV |
| | +----+ +----+ +----+ +----+ |
| +-|4CLA|<-+ |4CLA|<-+ |4CLA|<-+ |4CLA|<--+--|--C0
| +----+ | +----+ | +----+ | +----+ | |
| || | || | || | || | |
| VV | VV | VV | VV | |
| +------------------------------------+ | |
| | P3G3 C12 P2G2 C8 P1G1 C4 P0G0| | |
C16 <--|--|C16 Carry Lookahead Unit(CLU) |<-+ |
| | PG GG | |
| +------------------------------------+ |
| 16-bit Carry-Lookahead Adder | | |
+---------------------------------------------+
| |
V V16位RCA
- \(D(C_{16}) = 33d\)
- \(D(S_{15}) = 32d\)
减法指令 -> 还是加法器
将1输入到加法器的\(C_0\), 可通过加法器实现减法器
若无需同时完成加法和减法操作, 可让两者共享同一个加法器
比较/跳转指令 -> 仍然是加法器
- 相等和不等可直接用异或操作来判断
- 小于操作需要通过减法进行比较
- 有符号小于: 列真值表
- \(less = C_n \oplus C_{n-1}\)
- 无符号小于: 减法有借位 = 加法无进位
- \(less_u = \overline{C_n}\)
- 有符号小于: 列真值表
| \(A_{n-1}\) | \(B_{n-1}\) | \(C_{n-1}\) | \(C_n\) | \(S_{n-1}\) | 溢出 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 | 0 |
跳转指令还需要在条件满足时修改PC
- 通过多路选择器选出新PC
移位指令 -> 桶形移位器
用电路实现a << b和a >> b
- 若设计电路时
b为常数, 则可用位拼接/位抽取实现- 静态移位(static shift),
a << 4 = {a[27:0], 4'b0000}
- 静态移位(static shift),
- 若设计电路时
b无法提前确定, 则需根据b的值动态生成移位结果- 动态移位(dynamic shift)
交叉开关式桶形移位器: 根据\(A\)直接选择\(Y\)的每一位
- 假设输入数据\(A\)的位宽为\(n\), 则本质上是个\(n\)位的\(n\)选1多路选择器
- 延迟低, 为\(O(1)\)
- 但面积较大
- 译码器的面积开销为\(O(2^n)\)
- 选择器中与门的总数为\(n^2\)

移位指令 -> 桶形移位器(2)
级联式桶形移位器: 采用(\(\log_2{n}\)级\(\times\)\(n\)个/级)的2-1选择器阵列, 第\(i\)级根据\(S_i\)选择是否移动\(2^i\)位, 并将选择结果作为下一级的输入
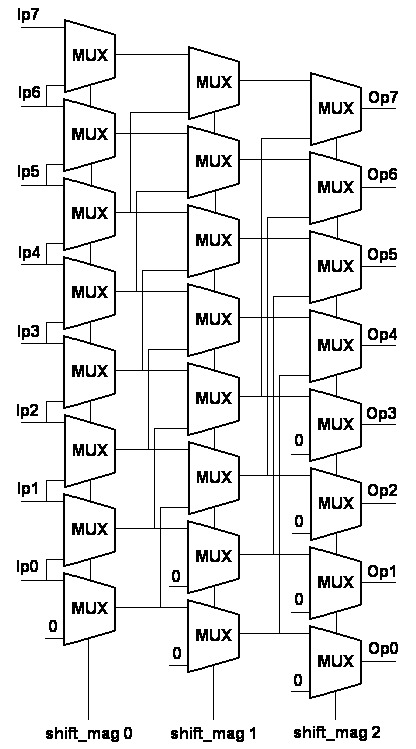
- \(S = S_{n-1}2^{n-1}+\dots+S_12^1+S_02^0\)
- 对每一级的选择器来说, 只有 “移动”(\(S_i=1\))和 “不移动”(\(S_i=0\))两种选择
- 移动时, 对于第\(i\)级, \(2^i\)为常数, 故属于静态移位
- 延迟为\(O(\log n)\), 高于交叉开关式
- 但面积较小
- \(\log_2{n}\)个1-2译码器, 面积开销为\(O(\log n)\)
- 共\(n\log_2{n}\)个选择器, 其中与门总数为\(2n\log_2{n}\)
可以增加逻辑右移和算术右移功能
- 整体框架相同, 只需增加选择端和选择器的输入
现代综合器
大部分情况下, 综合器能将各种运算符综合成高质量的电路
- 例如
+/-/<等, 综合器通常都综合出CLA - 而且很大概率比你自己设计的质量更高
- EDA大厂有数十年的经验积累
- 如果这都做不好, 三大EDA厂商如何垄断全球 😂
所以, 我们只需要从学习的层面了解前文设计的基本原理即可
- 在实际项目中,
我们更应该主动了解综合器的能力水平
- 阅读Vivado/yosys等EDA工具生成的网表文件,
了解综合器具体将
+/-/<等运算符综合成何种电路
- 阅读Vivado/yosys等EDA工具生成的网表文件,
了解综合器具体将
- 工具做得很好的事情, 就交给工具来完成
- 我们应该将时间花在工具还做不好的事情上, 取长补短, 提升项目质量
其他RVI指令
- 访存指令 -> LSU
- 计算出访存地址后, 将其连接到存储器进行访存
- 逻辑运算指令 -> 逻辑门
- 采用对应的逻辑门即可
lui- 得出立即数后, 很容易实现
auipc-> 加法器- 将PC作为其中一个操作数, 进行加法操作
jal,jalr- 需要同时计算跳转目标和下一条静态指令的地址
通常把加法器, 移位器, 以及用于逻辑运算的逻辑门统称为ALU
- 本质上也是一个多路选择器, 根据操作码选择一种运算结果
RTL设计选讲
案例1 - 指令译码器
负责从指令生成控制信号, 从而控制数据通路上的数据流向
- 本质上是一个查找表
- 表的规模会影响实现复杂度
- 5条指令, 2个控制信号, 很简单!
- 50条指令, 20个控制信号, 怎么办?
- 你想实现一个部件/一种优化方法, 发现要加几个控制信号
- 你还想加压缩指令
都是同一个设计, 但怎么写代码又是另一回事
道理我都懂, 但…
assign SB = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]);
assign SH = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]);
assign SWR = (IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign SWL = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]);
assign SRL = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & ~IR[0]);
assign SRA = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & IR[0]);
assign Ext0 = (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign Wtrs = ((Zero == 1'b0) & (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0])) | ((Zero == 1'b1) & (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]));
assign LWLR1 = (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]);
assign LWLR2 = (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]);
assign LWLR3 = (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]);
assign LHU = (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]);
assign LH = (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]);
assign LBU = (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]);
assign LB = (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]);
assign ZeroJg = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & IR[16]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & ~IR[16]) | (IR[31:26] == 6'b000111);
assign RegDst = (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign ALUSrc = (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & ~IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]);
assign PCSrc = ((~(Zero == 1)) & (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26])) | ((Zero == 1) & (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26])) | ((Address == 32'h00000000) & (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & IR[16])) | (((Address == 32'h00000001) | (Read1 == 32'h00000000)) & (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26])) | ((Address == 32'h00000001) & (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & ~IR[16])) | (Address == 32'h0 & ~(Read1 == 32'h0) & IR[31:26] == 6'b000111);
assign RegWrite = (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & ~IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & ~IR[1] & IR[0]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | ((Zero == 1'b0) & (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0])) | ((Zero == 1'b1) & (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0])) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign Jmp = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]);
assign MemWrite = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign MemRead = (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]);
assign MemtoReg = (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]);
assign SLL = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & ~IR[1] & ~IR[0]);
assign JAL1 = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & ~IR[1] & IR[0]);
assign JAL2 = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]);
assign JR = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & ~IR[1] & IR[0]);
assign Write_strb[3] = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (ALUResult[1] & ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (ALUResult[1] & ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign Write_strb[2] = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (ALUResult[1] & ~ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (ALUResult[1] & ~ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]);
assign Write_strb[1] = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~ALUResult[1] & ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (~ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~ALUResult[1] & ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]);
assign Write_strb[0] = (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~ALUResult[1] & ~ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (~ALUResult[1] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~ALUResult[1] & ~ALUResult[0] & IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]);
assign ALUctr[3] = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]);
assign ALUctr[2] = (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & IR[16]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & ~IR[16]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]) | (IR[31:26] == 6'b000111);
assign ALUctr[1] = (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & ~IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & IR[16]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & ~IR[16]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & ~IR[27] & IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]) | (IR[31:26] == 6'b000111);
assign ALUctr[0] = (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & IR[29] & ~IR[28] & IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & IR[16]) | (~IR[31] & ~IR[30] & ~IR[29] & IR[28] & IR[27] & ~IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & IR[26] & ~IR[20] & ~IR[19] & ~IR[18] & ~IR[17] & ~IR[16]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & ~IR[27] & IR[26]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & ~IR[5] & ~IR[4] & ~IR[3] & IR[2] & ~IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & IR[3] & ~IR[2] & IR[1] & IR[0]) | (~IR[31] & ~IR[30] & ~IR[29] & ~IR[28] & ~IR[27] & ~IR[26] & IR[5] & ~IR[4] & ~IR[3] & IR[2] & IR[1] & ~IR[0]) | (~IR[31] & ~IR[30] & IR[29] & IR[28] & IR[27] & ~IR[26]) | (IR[31:26] == 6'b000111);道理我都懂, 但……
6'b001010://slti
begin
RegDst <= 0;
ALUSrc <= 1;
Branch <= 0;
RegWrite <= 0;
RegRead <= 1;
MemtoReg <= 0;
//MemRead <= 0;
//MemWrite <= 0;
Write_strb <= 4'd0;
ALUcon_in <= 3'b010;
Jump <= 0;
JumpReg <= 0;
JAL <= 0;
LUI <= 0;
SL <= 0;
s <= 0;
Sign <= 1;
BEQ <= 0;
BGEZ <= 0;
BGTZ <= 0;
BLEZ <= 0;
BLTZ <= 0;
Logic <= 0;
Left <= 0;
JALR <= 0;
Align <= 0;
Part_data <= 32'd0;
end 6'b001011://sltiu
begin
RegDst <= 0;
ALUSrc <= 1;
Branch <= 0;
RegWrite <= 0;
RegRead <= 1;
MemtoReg <= 0;
//MemRead <= 0;
//MemWrite <= 0;
Write_strb <= 4'd0;
ALUcon_in <= 3'b011;
Jump <= 0;
JumpReg <= 0;
JAL <= 0;
LUI <= 0;
SL <= 0;
s <= 0;
Sign <= 0;
BEQ <= 0;
BGEZ <= 0;
BGTZ <= 0;
BLEZ <= 0;
BLTZ <= 0;
Logic <= 0;
Left <= 0;
JALR <= 0;
Align <= 0;
Part_data <= 32'd0;
end 类似的代码有1500行
编写不可维护的代码 = 给将来的自己挖坑
如何拥抱变化
- 加一条指令
- 逻辑表达式 - 给相关的assign各加一个最小项
- case语句 - 加一个case
- 加一个控制信号
- 逻辑表达式 - 加一条很长的assign
- case语句 - 每个case各加一行
灵魂拷问
- 你愿意仔细看看你的代码是否正确吗?
- 先仿真再说, 万一跑对了呢
- 如果这是别人的代码, 你愿意仔细看看他的代码是否正确吗?
回顾 - 编写可读可维护代码
正确的代码 != 好代码
- 好代码更大概率是正确的
好代码的两条重要准则
- 不言自明 - 仅看代码就能明白是做什么的(specification)
- 不言自证 - 仅看代码就能验证实现是对的(verification)
使用正确的编程模式写出好代码
- 防御性编程 - 通过
assert检查非预期行为 - 减少代码中的隐含依赖 - 使得 “打破依赖”不会发生
- 头文件 + 源文件
- 编写可复用的代码 - 不要Copy-Paste
- 使用合适的语言特性 - 把细节交给语言规范和编译器
写代码 != “写”代码
分析: 译码器的本质是查找表
需求: 如何 “低熵”地实现一张表?
- 我们只需要维护好这张表
- 除了表本身, 其他没有必要的信息尽量不出现
- 上述case方案中, 控制信号名称是冗余的, 但如果有错, 就是bug
- 除了表本身, 其他没有必要的信息尽量不出现
- 让工具/综合器将它转换成逻辑表达式
- 上述逻辑表达式方案中, 开发者成了工具人
我们需要寻找合适的语言特性来实现一张表
Verilog解决方案
太难了 😂
我们提供一个键值选择模板muxkey-template.v, 可以像真值表一样查询
module mux41(a,s,y);
input [3:0] a;
input [1:0] s;
output y;
// 通过MuxKeyWithDefault实现如下always代码
// always @(*) begin
// case (s)
// 2'b00: y = a[0];
// 2'b01: y = a[1];
// 2'b10: y = a[2];
// 2'b11: y = a[3];
// default: y = 1'b0;
// endcase
// end
MuxKeyWithDefault #(4, 2, 1) i0 (y, s, 1'b0, {
2'b00, a[0],
2'b01, a[1],
2'b10, a[2],
2'b11, a[3]
});
endmoduleVerilog解决方案(2)
但还是有很多不完善的地方
- Verilog的类型系统很弱, 所有数据都是比特串
- 表那么大, 哪里多了/少了1bit, 整个选择结果就错了
- Verilog做不好/做不了的事情, 都丢给开发者了
- 这个模板不支持模糊匹配
- 只能先进行第一级译码, 得出指令类型
- 再进行第二级译码得到控制信号
casex和casez在行为建模语义上支持模糊匹配- 但在可综合语义上是否支持, 就不好说了
- 而且综合出来什么样的电路, 也并不直观
- 如果这里是关键路径, 怎么办?
借助外部工具
案例: 第一届龙芯杯(2017), 南京大学一队通过excel和python脚本, 实现译码器的敏捷开发和低熵维护
- 但python生成的是Verilog的case语句, 行为建模的问题同样存在

Chisel解决方案 - ListLookup API
借助scala的强大类型系统, 把表格嵌入到Chisel代码中
- 编译出级联Mux, 需要依赖综合器优化(级联树的平衡, 并行选择)
object RV64IInstr extends HasInstrType {
def ADDIW = BitPat("b???????_?????_?????_000_?????_0011011")
def SLLIW = BitPat("b0000000_?????_?????_001_?????_0011011")
def SRLIW = BitPat("b0000000_?????_?????_101_?????_0011011")
def SRAIW = BitPat("b0100000_?????_?????_101_?????_0011011")
def SLLW = BitPat("b0000000_?????_?????_001_?????_0111011")
def SRLW = BitPat("b0000000_?????_?????_101_?????_0111011")
def SRAW = BitPat("b0100000_?????_?????_101_?????_0111011")
def ADDW = BitPat("b0000000_?????_?????_000_?????_0111011")
def SUBW = BitPat("b0100000_?????_?????_000_?????_0111011")
def LWU = BitPat("b???????_?????_?????_110_?????_0000011")
def LD = BitPat("b???????_?????_?????_011_?????_0000011")
def SD = BitPat("b???????_?????_?????_011_?????_0100011")
val table = Array(
ADDIW -> List(InstrI, FuType.alu, ALUOpType.addw),
SLLIW -> List(InstrI, FuType.alu, ALUOpType.sllw),
SRLIW -> List(InstrI, FuType.alu, ALUOpType.srlw),
SRAIW -> List(InstrI, FuType.alu, ALUOpType.sraw),
SLLW -> List(InstrR, FuType.alu, ALUOpType.sllw),
SRLW -> List(InstrR, FuType.alu, ALUOpType.srlw),
SRAW -> List(InstrR, FuType.alu, ALUOpType.sraw),
ADDW -> List(InstrR, FuType.alu, ALUOpType.addw),
SUBW -> List(InstrR, FuType.alu, ALUOpType.subw),
LWU -> List(InstrI, FuType.lsu, LSUOpType.lwu),
LD -> List(InstrI, FuType.lsu, LSUOpType.ld ),
SD -> List(InstrS, FuType.lsu, LSUOpType.sd)
)
}Chisel解决方案 - Decoder API
用法和ListLookup几乎相同, 但有额外好处
- 通过算法生成逻辑表达式, 相当于工具来进行卡诺图化简
- QMC(Quine-McCluskey)算法 - 得到精确最优解, 但算法时间复杂度较高, 适用于规模不大的表格
- espresso算法 - 得到近似最优解, 算法时间复杂度较低, 适用于规模较大的表格
- 表项中支持无关项(Don’t care)
- 据说在Vivado上能提升10%的主频
核心思想: 借助工具生成精准的电路描述, 将不确定的综合器行为前移到设计阶段
译码器实现方案小结
| 方案 | 容易维护 | 综合精确 |
|---|---|---|
| 逻辑表达式 | ✖️✖️ | ✔️✔️ |
| case语句 | ✖️ | ✖️ |
| excel + python | ✔️✔️ | ✖️ |
| Chisel ListLookup | ✔️✔️ | ✔️ |
| Chisel Decoder | ✔️✔️ | ✔️✔️ |
案例2 - 级联式桶形移位器
一份参考代码
module barrelShifter(Ip, Op, shift_mag);
input [7:0] Ip; //The 8-bit Input line
output [7:0] Op; //The 8-bit Output line
input [2:0] shift_mag; //The 3-bit shift magnitude selection Input
wire [7:0] ST1,ST2; //Two 8-bit intermediate lines
//the barrel shifter implemented as array of MUX shown in the figure
mux_2to1 m0 (1'b0, Ip[0], ST1[0], shift_mag[0]);
mux_2to1 m1 (Ip[0], Ip[1], ST1[1], shift_mag[0]);
mux_2to1 m2 (Ip[1], Ip[2], ST1[2], shift_mag[0]);
mux_2to1 m3 (Ip[2], Ip[3], ST1[3], shift_mag[0]);
mux_2to1 m4 (Ip[3], Ip[4], ST1[4], shift_mag[0]);
mux_2to1 m5 (Ip[4], Ip[5], ST1[5], shift_mag[0]);
mux_2to1 m6 (Ip[5], Ip[6], ST1[6], shift_mag[0]);
mux_2to1 m7 (Ip[6], Ip[7], ST1[7], shift_mag[0]);
mux_2to1 m00 (1'b0 , ST1[0], ST2[0], shift_mag[1]);
mux_2to1 m11 (1'b0 , ST1[1], ST2[1], shift_mag[1]);
mux_2to1 m22 (ST1[0], ST1[2], ST2[2], shift_mag[1]);
mux_2to1 m33 (ST1[1], ST1[3], ST2[3], shift_mag[1]);
mux_2to1 m44 (ST1[2], ST1[4], ST2[4], shift_mag[1]);
mux_2to1 m55 (ST1[3], ST1[5], ST2[5], shift_mag[1]);
mux_2to1 m66 (ST1[4], ST1[6], ST2[6], shift_mag[1]);
mux_2to1 m77 (ST1[5], ST1[7], ST2[7], shift_mag[1]);
mux_2to1 m000 (1'b0 , ST2[0], Op[0], shift_mag[2]);
mux_2to1 m111 (1'b0 , ST2[1], Op[1], shift_mag[2]);
mux_2to1 m222 (1'b0 , ST2[2], Op[2], shift_mag[2]);
mux_2to1 m333 (1'b0 , ST2[3], Op[3], shift_mag[2]);
mux_2to1 m444 (ST2[0], ST2[4], Op[4], shift_mag[2]);
mux_2to1 m555 (ST2[1], ST2[5], Op[5], shift_mag[2]);
mux_2to1 m666 (ST2[2], ST2[6], Op[6], shift_mag[2]);
mux_2to1 m777 (ST2[3], ST2[7], Op[7], shift_mag[2]);
endmoduleRV32的字长是32位, 怎么办?
- 要实例化\(32\times\log_2{32}=160\)个选择器; RV64则要实例化\(384\)个
Chisel重磅福利
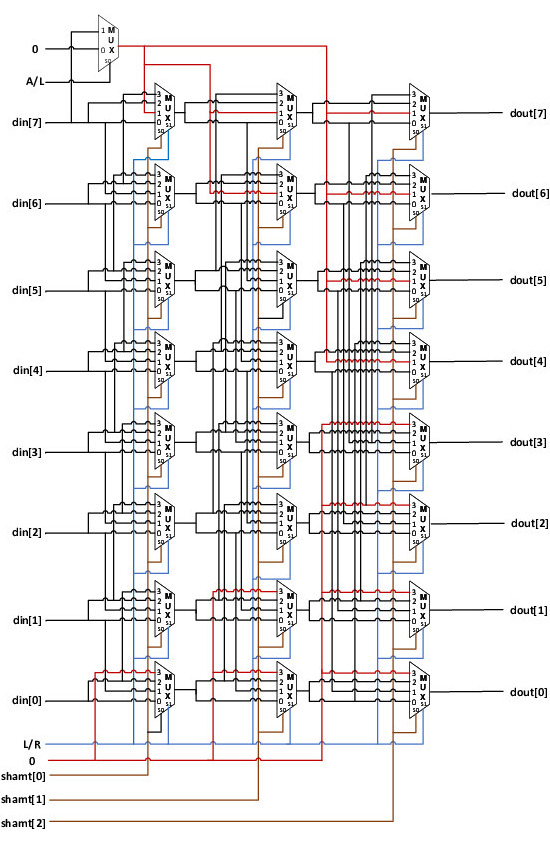
通过递归10行核心代码实现参数化桶形移位器
class BarrelShift(w: Int) extends Module {
val io = new Bundle {
val in = Input(UInt(w.W))
val shamt = Input(UInt(log2Up(w).W))
val isLeft = Input(Bool())
val isArith = Input(Bool())
val out = Output(UInt(w.W))
}
val leftIn = Mux(io.isArith, io.in(w-1), false.B) // 右移时从左边移入的位
def layer(din: Seq[Bool], n: Int): Seq[Bool] = { // 描述第n级选择器如何排布
val s = 1 << n // 需要移动的位数
def shiftRight(i: Int) = if (i + s >= w) leftIn else din(i + s) // 描述右移时第i位输出
def shiftLeft (i: Int) = if (i < s) false.B else din(i - s) // 描述左移时第i位输出
val sel = Cat(io.isLeft, io.shamt(n)) // 将移位方向和移位量作为选择器的选择信号
din.zipWithIndex.map{ case (b, i) => // 对于每一位输入b,
VecInit(b, shiftRight(i), b, shiftLeft(i))(sel) } // 都从4种输入中选择一种作为输出
}
def barrelshift(din: Seq[Bool], k: Int): Seq[Bool] = // 描述有k级的桶形移位器如何排布
if (k == 0) din // 若移位器只有0级, 则结果和输入相同
// 否则实例化一个有k-1级的桶形移位器和第k-1级选择器, 并将后者的输出作为前者的输入
else barrelshift(layer(din, k - 1), k - 1)
io.out := Cat(barrelshift(io.in.asBools, log2Up(w)).reverse) // 实例化一个有log2(w)级的桶形移位器
}只需传入不同的w参数,
即可生成不同数据位宽的桶形移位器
- 无需改动内部任何代码
核心思想: 将桶形移位器如何排布和连接的规律抽象成算法
Chisel福利的本质 - 不当工具人
核心思想: 将桶形移位器如何排布和连接的规律抽象成算法
- 执行这个算法, 就能得到RTL层次的桶形移位器
关键是谁来执行这个算法
- 传统RTL设计流程 - 开发者来执行, 需要手动编排选择器并连线
- 如果算法的输入(数据位宽)有变化, 开发者重新执行
- Chisel流程 - Chisel Builder(一个Scala程序)来执行
- 用Chisel写的不是桶形移位器, 而是桶形移位器的生成器(generator)
- 如果算法的输入有变化, 只需重新执行这个算法即可
传统流程也可以使用perl/tcl等脚本编写这个算法来生成RTL代码
- 但不能像Chisel嵌入在Scala中那样, 将Verilog嵌入在perl/tcl
- 不过如果你有这些意识, 你已经超越那些只会看图写RTL的开发者了
总结
重新审视RTL设计
- 微结构设计 - 仅仅看图写代码是不够的
- 需要学会将需求转换成微结构设计图
- 接受解决未知问题的训练, 通过试错和思考理解细节
- 功能单元设计 - 学习时了解基本原理, 实践时充分利用工具
- 如果不是纯粹为了学习, 没有必要从逻辑门开始搭建所有部件
- 了解工具的能力和极限, 取长补短, 共同提升项目的质量
- 编写可读可维护的RTL代码 - 低熵实现
- 选一个表达能力强的语言
- 借助工具弥补语言的缺陷