



提升写相似代码的效率
- 正则表达式
- 你用
INSTPAT实现了50条指令, 突然想批量修改
- 你用
- 记录回放
- 你定义了50个常量, 突然想全部+1
:%! seq 1 50 | shuf | cat -n | awk '{print "\#define X" $1 " " $2}'
$q1<C-a>jq # 将"本行数字加1"(<C-a>)和"光标移动到下一行"(j)记录到名字为"1"的宏中
49@1 # 将名字为"1"的宏回放49次
你也许很少遇到类似场景, 使得这个例子看上去没什么用
更本质地: 尝试把用编程取代重复劳动的思想应用在其他场景(文本处理/数据处理)
- 正则表达式编程/shell命令编程/vim命令编程
提升写不相似代码的效率
这没法加速吧…
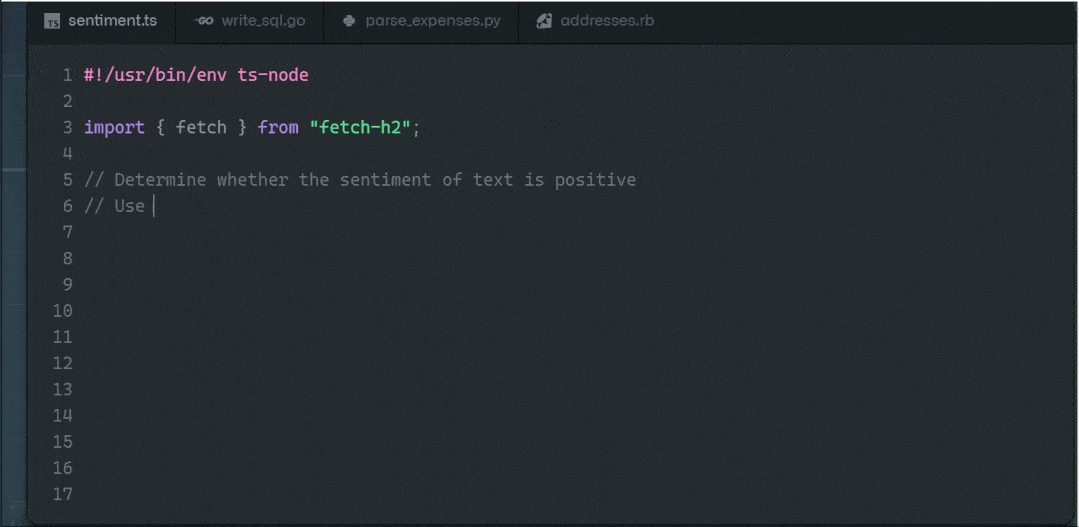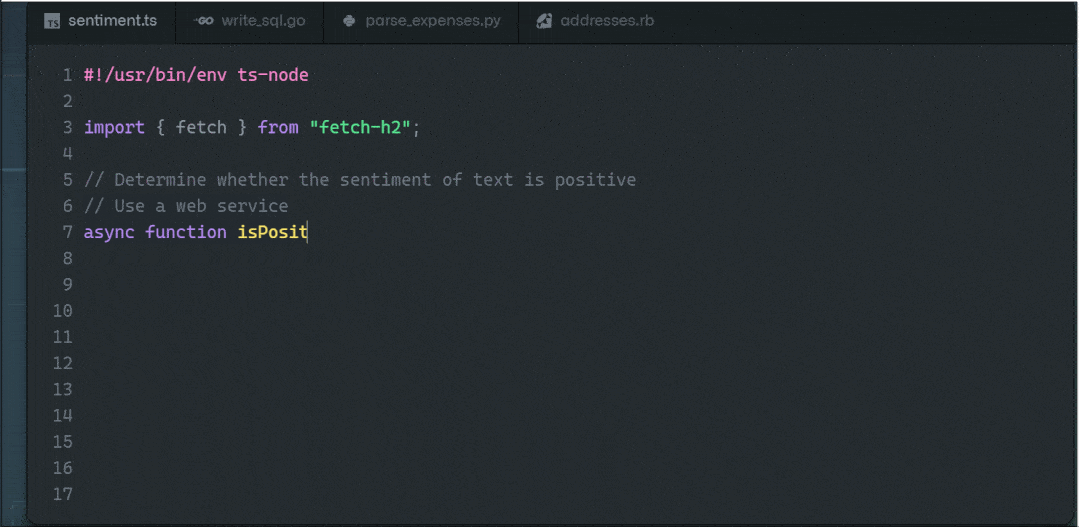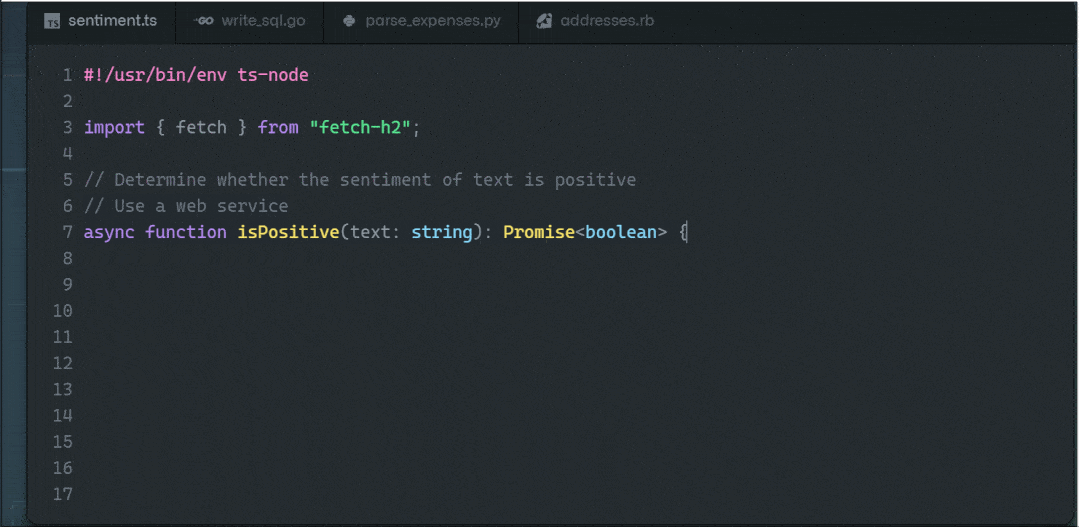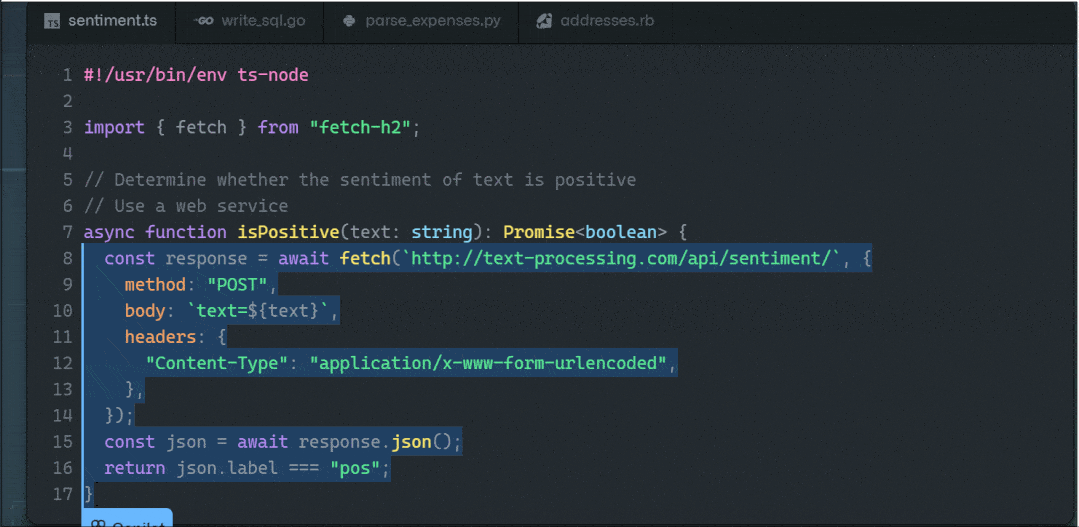
AI帮你写代码 - Copilot
还有ChatGPT
- 《索赔 649 亿!GitHub Copilot 惹上官司,被指控侵犯代码版权, 是开源社区“寄生虫”》
- 《代码的深渊》 -
2022年, 一个试图用AI取代程序员的故事
![]()
- 一篇2016年发布的科幻漫画
- Copilot正好是2022年发布, 作者真是神预测 😂

当然对学习来说, 这是违反学术诚信的
在CPU上执行正确的程序, 结果错
问题: 怎么调试?
看波形? printf?
dummy,sum,add这些, 不是很难hello-str有几千条指令, 慢慢看还行microbench的test规模跑几十万条指令, 笑容逐渐消失- 超级玛丽根本不会停止, @^&!%$#@…

- CPU设计好玩吗?
- 好玩
- 真的吗?
为什么这时候看波形效率这么低?
调试CPU = 找到第一条行为不正确的指令
但是波形/printf并不告诉你哪条指令开始出错, 你要自己找
- 你不仅要在很多指令里面找
- 而且还要自己判断每条指令对不对

明明是你在调bug, 有时却分明感觉是bug在调你
明明是你在玩游戏,有时却分明感到是游戏在玩你
-- 金山游侠广告词
你需要一个 “金山游侠”来 “体会那一技必杀的神奇”
DiffTest的意义
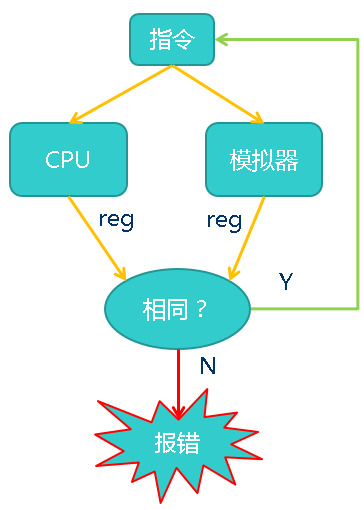
- DiffTest =
在线指令级行为验证方法
- 在线 = 边跑程序边验证
- 指令级 = 执行的每条指令都验证
- 把任意程序转化为指令级别的测试, 对执行每条指令后的状态进行断言
- 支持不会结束的程序, 例如超级玛丽, OS
- 无需提前得知程序的结果
- 检查指令执行的行为, 而不是程序的语义
- riscv-torture通过比较signature(最终的寄存器状态)来判断执行结果
- 比较signature = 离线程序级行为验证方法
- 本质上是最后自动assert, 要找到出错的指令还是很困难
- 如果程序不能结束, 就无法比较
2017年: 起源, 加入南京大学PA实验
- 2017年5月的一节计算机系统综合实验课, jyy和大家一起头脑风暴
- jyy提到应该想办法让CPU和另一个东西进行cross check(交叉对比)
- 6月, yzh突发奇想, 让x86的NEMU和真机对比指令行为
- 通过
fork()系统调用创建一个进程, 执行相同的二进制文件, 通过ptrace()控制真机单步执行并获取寄存器状态 - 还真通过了一些简单的测试, 但因32位和64位区别, 其他测试不通过
- 通过
- 7月, 尝试改用QEMU当REF, 通过所有测试

- 8月, 更新讲义时发现cross check是一个国际象棋术语
- jyy想到differential testing
- 9月, DiffTest与AM作为套餐首次加入2017年PA, 标志着PA迈向现代化
2018年: 助力南大乱序CPU NOOP获龙芯杯第二名
首个采用DiffTest验证CPU的FPGA项目
- 先实现mips32的NEMU, 再作为REF和NOOP对比
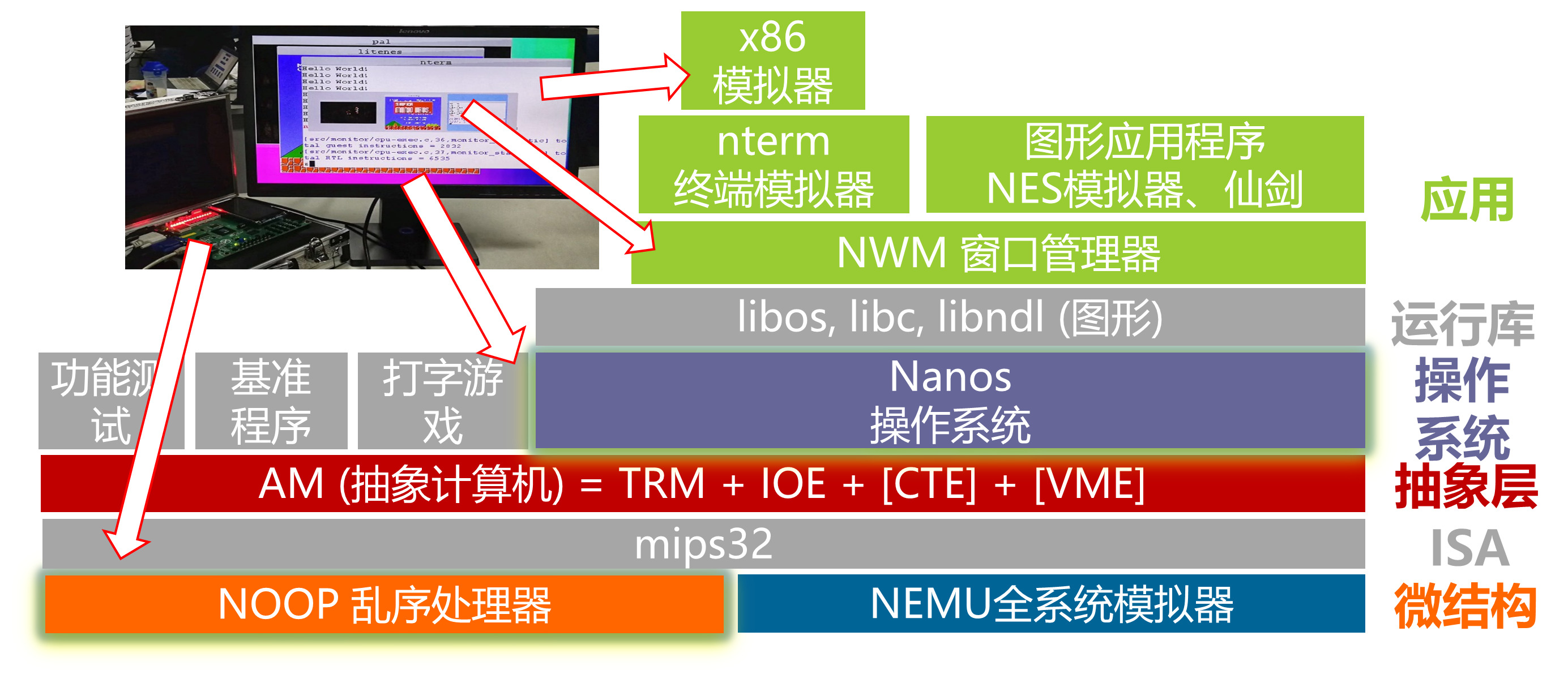
2018年: 助力南大乱序CPU NOOP获龙芯杯第二名
书写了一周正确实现一个乱序发射乱序执行处理器, 成功运行自制分时多任务操作系统Nanos和仙剑奇侠传的神话
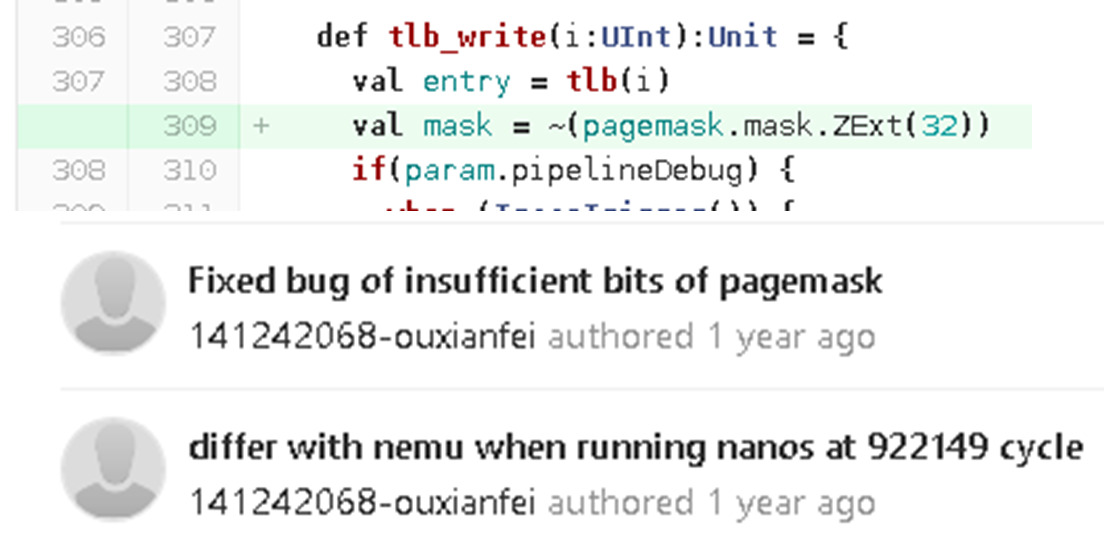
按位取反之前忘记零扩展
可惜其中一名队员摸鱼严重, 最后Linux只起了一半
2019年: 助力首期 “一生一芯”果壳处理器硅前验证

2019年: 助力首期 “一生一芯”果壳处理器硅前验证
学生代表作报告介绍果壳项目时, DiffTest均作为关键技术进行介绍


2020年: 助力开源高性能RV处理器香山硅前验证
香山在开发早期(第二周)就搭建DiffTest框架, 之后便一直开启

2021年: 香山团队实现支持多核的DiffTest
【王凯帆、王华强】SMP-DiffTest:支持多处理器的差分测试方法 - 第一届RISC-V中国峰会

新增memory checker的assert

SMP DiffTest报告了新的硬件bug, 修复后香山成功启动多核Linux
2022年: 龙芯杯引入DiffTest帮助学生调试处理器
2022龙芯杯第三期线上培训
2022年: 香山团队的DiffTest工作被体系结构国际顶会MICRO录用
Yinan Xu, et al. Towards Developing High Performance RISC-V Processors Using Agile Methodology

DiffTest开创了新的处理器验证方法
| 年份 | 项目 | 效果 |
|---|---|---|
| 2017 | 南京大学PA实验 | 大幅降低了调试指令bug的难度 |
| 2018 | 南京大学参加龙芯杯 | 一周正确实现乱序发射乱序执行处理器, 并运行自制分时多任务操作系统和复杂应用仙剑奇侠传 |
| 2019 | 首期 “一生一芯”果壳处理器 | 5天成功启动Linux运行Busybox, 4天成功启动Debian运行GCC/QEMU |
| 2020 | 开源高性能RISC-V处理器香山 | 项目启动后第3周成功运行coremark, 第5周成功运行仙剑奇侠传, 第3个月成功启动Linux, 第4个月成功启动Debian |
| 2021 | 开源高性能RISC-V处理器香山 | 成功启动SMP Linux; 环境就绪后首次上FPGA即可正确跑完所有SPEC 2006 REF测试, 无需在板卡上调试任何处理器相关的bug |
| 2022 | 龙芯杯 | LoongArch赛道引入DiffTest帮助学生调试处理器, 团体赛不少启动Linux的队伍自发使用DiffTest |
| 2022 | 香山团队 | DiffTest工作被体系结构国际顶会MICRO录用 |
- 没用过的不知道, 用过的都说好!
- 但其实软工领域很早就提出这些方法了 😂
- 所以应该多向软工领域学习
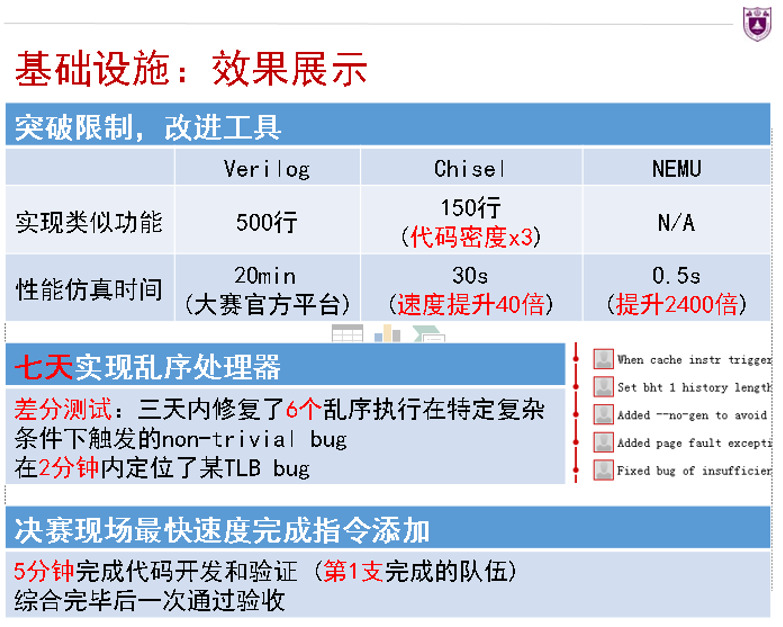
香山项目的基础设施
2021年RISC-V中国峰会, 工具类报告占香山团队报告总量55%(12/22)
- 大厂里面的基础设施更丰富
