



参考书: The RISC-V Reader & RISC-V官方手册

一本科普读物

真正的RISC-V手册 ✅
《The RISC-V Reader》
- 作者来自RISC-V团队, 书的质量并不低
- 书中介绍了很多软硬件协同工作的例子和指令集设计的考量
- 虽然是2017年出版, 有的内容已经跟不上官方的RISC-V手册, 但仍然值得阅读学习
敬请期待: 《RISC-V开放架构设计之道》

- The RISC-V Reader 第2版中文译本
- 改进较多, 大幅提升阅读体验
预计发售时间: 2023年11月
1. 成本
| ARM Cortex-A5 | RISC-V Rocket | |
|---|---|---|
| ISA | 32位ARM-v7 | 64位RISC-V |
| 微结构 | 顺序单发射 | 顺序单发射5级流水 |
| Dhrystone性能 | 1.57 DMIPS/MHz | 1.72 DMIPS/MHz |
| 工艺 | TSMC 40GPLUS | TSMC 40GPLUS |
| 不带缓存面积 | 0.27 mm2 | 0.14 mm2 |
| 带16KB缓存面积 | 0.53 mm2 | 0.39 mm2 |
| 动态功耗 | < 0.08 mW/MHz | 0.034 mW/MHz |

更小的芯片 = 一个晶圆中有更多可用芯片 = 每颗芯片的成本更低
6. 代码大小
- 嵌入式处理器: 更小的代码 = 更小的存储器 = 更低的成本
- 低端嵌入式芯片都是白菜价, 出货量高
- 成本节约1分钱, 就是巨大的竞争力
- 高性能处理器: 更小的代码 = 更高的缓存命中率 = 更低的功耗 &
更高的性能
- 访问功耗: 片外DRAM > 片内SRAM
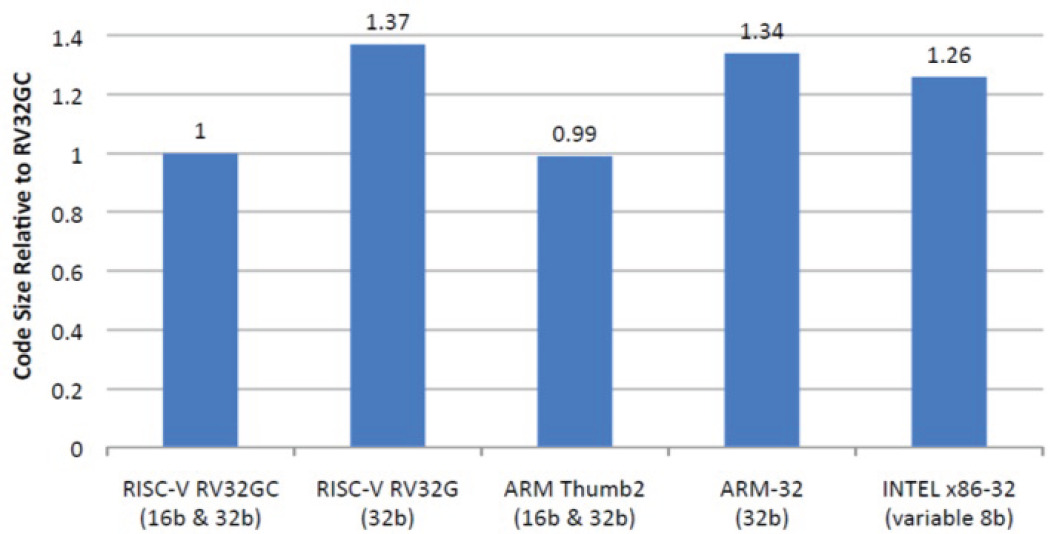
右图: 使用GCC编译的SPEC CPU2006基准测试的代码大小
- x86作为变长指令集, 代码竟然比RV32GC大26%
- 其实是历史原因造成的
x86的1字节操作码空间中的不常用指令
- 69条肯定不常用指令
- 系统指令(中断和I/O), 段寄存器相关, 保存寄存器现场,
BCD码计算(被历史淘汰), EFLAGS标志位设置清除, ESP寄存器相关, 循环前缀
![]()
- 系统指令(中断和I/O), 段寄存器相关, 保存寄存器现场,
BCD码计算(被历史淘汰), EFLAGS标志位设置清除, ESP寄存器相关, 循环前缀
- 42条不常用指令
- 进位加/借位减, 溢出和奇偶标志, 数据交换, 字符串操作, 原子前缀/字符串重复前缀

个人观点: 总计43.36%的1字节操作码空间的使用并不合理
- 但为了向前兼容, 无法更改/回收
用起来像是定长的变长指令集
- 变长指令集: 无限的操作码空间, 但译码器的设计复杂
- 定长指令集: 有限的操作码空间, 但译码器的设计简单

大人才做选择, 小孩全都要!
- 基础指令集和大部分标准扩展采用4字节定长指令(RVC是2字节)
- 对绝大部分RISC-V处理器来说, 指令是定长的
- 通过模块化, 更长的指令只会用在特定应用场景
- 只有采用变长指令扩展的RISC-V处理器, 才需要支持变长指令
- 不影响已经设计的RISC-V处理器
本质: 模块化特性根据需求对不同处理器的实现细节进行隔离
指令格式

- 6种指令格式, 长度均为32位, 简化了译码器的实现
- 在低端处理器中, 复杂的译码器 = 提高成本
- 在高端处理器中, 复杂的译码器 = 性能瓶颈
- 三地址指令, 即指令操作数有3个
- 大部分x86指令是二地址指令, 需要额外移动数据来进行三地址操作
# a = b + c; # 假设b分配在ebx中, c分配在ecx中, 计算结果a分配在eax中 # 为了避免b或c被覆盖, 完成上述操作需要借助额外的mov指令 mov %ebx, %eax add %ecx, %eax
指令格式(2)
- 在所有指令格式中,
rd,rs1,rs2总是在相同的位置- 实现时可节省不必要的选择器
- MIPS则不是
31 26 25 21 20 16 15 11 10 6 5 0
+------+-----+-----+-----+-----+-----+
|opcode| rs | rt | rd | sa |funct| R-type rd = rs op rt
+------+-----+-----+-----+-----+-----+
+------+-----+-----+-----------------+
|opcode| rs | rt | imm | I-type rt = rs op imm
+------+-----+-----+-----------------+奇怪的立即数编码方式
你很可能会觉得立即数的编码方式匪夷所思
- 需要从硬件实现角度来理解
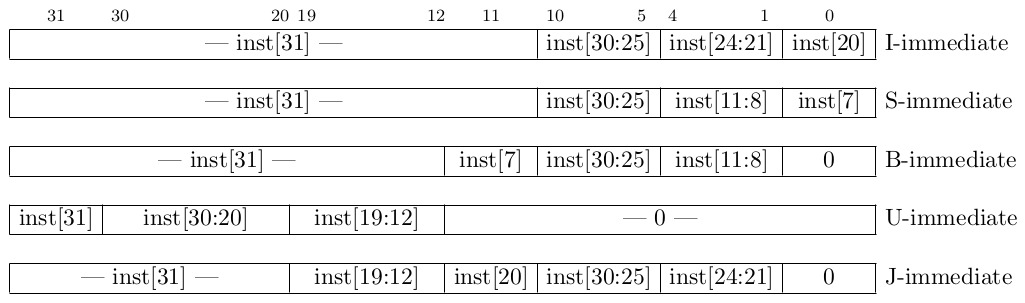
对于生成的立即数, 其中每个比特来源于不同类型指令的不同位置
- 因此需要通过选择器来生成立即数的每个比特
- 诀窍: 通过尽量减少每个比特的来源位置情况, 来减少选择器的输入端,
从而节省实现成本
imm[5]只来源于inst[25]或0(U型), 只需要2选1选择器imm[31]只来源于inst[31], 无需选择器, 可低延迟进行符号扩展
- 代价: 编译器生成指令时需要更长时间, 但这是一次性开销, 值得