数字芯片由晶体管构成
数字芯片 = 处理数字信号的芯片 =
处理0和1的芯片
- 晶体管是实现
0和1的基本元件 - 在数字芯片中,
通常使用
金属-氧化物-半导体场效应晶体管(Metal-Oxide-Semiconductor Field-Effect Transistor, MOSFET)
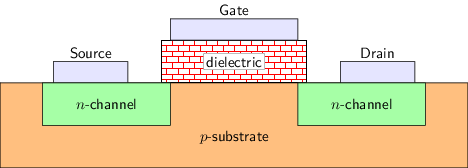
- 又分nMOS(上图)和pMOS两种, 都有栅极, 源极, 漏极
- 根据电气特性, nMOS的功能为
- 当\(V_G-V_S\)较大时, 源极和漏极导通 - 开关合上
- 当\(V_G-V_S\)较小时, 源极和漏极截止 - 开关断开
- pMOS的功能表现与nMOS类似
- \(V_S-V_G\)较大时导通, \(V_S-V_G\)较小时截止

CMOS = 用MOS管的开关特性实现0和1
CMOS = Complementary MOS = nMOS + pMOS
最简单的CMOS电路:

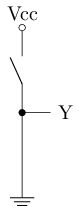
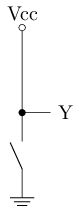
- A点加高电压时, n管导通, p管截止, 相当于Y点与地相连, 电压低
- A点加低电压时, n管截止, p管导通, 相当于Y点与电源相连, 电压高
CMOS将nMOS和pMOS的开关特性转换成输出电压的高低
- 将物理上的高电压定义为逻辑
1(高电平), 低电压定义为逻辑0(低电平)
我们得到了数字电路中信号的两种基本状态!
门电路 = 对状态进行运算
光有0和1还不够, 还要进行运算
- 通过CMOS电路对
0和1进行各种有意义的转换
- 考虑之前的CMOS电路:
- A点为
1时, n管导通, p管截止, Y点为0 - A点为
0时, n管截止, p管导通, Y点为1
- A点为

这正好是逻辑上的非运算!
- 这个电路就是非门, 也称反相器

另一个门电路
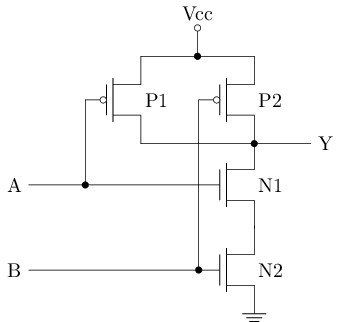
- P1和P2并联, 其中一者导通时, Y为
1 - N1和N2串联, 两者均导通时, Y为
0
| A | B | P1 | P2 | N1 | N2 | Y |
|---|---|---|---|---|---|---|
| 0 | 0 | 导通 | 导通 | 截止 | 截止 | 1 |
| 0 | 1 | 导通 | 截止 | 截止 | 导通 | 1 |
| 1 | 0 | 截止 | 导通 | 导通 | 截止 | 1 |
| 1 | 1 | 截止 | 截止 | 导通 | 导通 | 0 |
这正好是逻辑上的与非运算!
- 这个电路就是与非门

与门 = 与非门 + 非门


| A | B | P1 | P2 | N1 | N2 | Y0 | P3 | N3 | Y |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 导通 | 导通 | 截止 | 截止 | 1 | 截止 | 导通 | 0 |
| 0 | 1 | 导通 | 截止 | 截止 | 导通 | 1 | 截止 | 导通 | 0 |
| 1 | 0 | 截止 | 导通 | 导通 | 截止 | 1 | 截止 | 导通 | 0 |
| 1 | 1 | 截止 | 截止 | 导通 | 导通 | 0 | 导通 | 截止 | 1 |
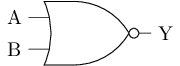
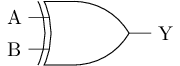
或非门和或门

- P1和P2串联, 两者均导通时, Y为
1 - N1和N2并联, 其中一者导通时, Y为
0
| A | B | P1 | P2 | N1 | N2 | Y |
|---|---|---|---|---|---|---|
| 0 | 0 | 导通 | 导通 | 截止 | 截止 | 1 |
| 0 | 1 | 导通 | 截止 | 截止 | 导通 | 0 |
| 1 | 0 | 截止 | 导通 | 导通 | 截止 | 0 |
| 1 | 1 | 截止 | 截止 | 导通 | 导通 | 0 |
这正好是逻辑上的或非运算!
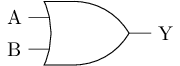
或非门的输出连一个非门, 可组成或门
三输入与非门
在门电路层面搭建
记#T(x)为门电路x所需的晶体管数量, 则
#T(nand3) = #T(and) + #T(nand) = 6 + 4 = 10可通过#T(x)粗略评估电路的面积
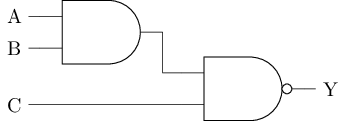
在晶体管层面搭建
#T(nand3) = 6
#T(nandN) = 2N
#T(andN) = #T(nandN) + #T(not) = 2(N + 1)
体现了ASIC设计中全定制电路的优势
- 延迟低, 功耗低, 面积小

异或门
在门电路层面
Y=A^B=A*~B+~A*B
#T(xor) = 2#T(not) + 2#T(and) + #T(or) = 2 * 2 + 2 * 6 + 6 = 22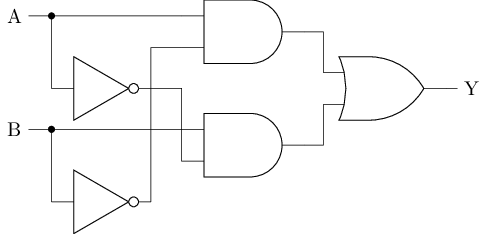
在晶体管层面搭建, 效果更优
A=1时, P2和N2相当于非门; P3和N3均截止; 故此时Y=~BA=0时, P2和N2均截止;B=0时N3导通;B=1时P3导通; 故此时Y=B
#T(xor) = 6
译码器
检测\(n\)位输入的值, 使\(2^n\)位输出中的相应位为1
- 若输入为\(X\), 则输出的第\(X\)位为
1, 其他位为0- 该输出也称独热码(One-hot)
- 常用于寻址: 输入某地址, 生成相应内容的有效信号
例: 2-4译码器
| \(A_1\) | \(A_0\) | \(|\) | \(Y_3\) | \(Y_2\) | \(Y_1\) | \(Y_0\) |
|---|---|---|---|---|---|---|
| 0 | 0 | \(|\) | 0 | 0 | 0 | 1 |
| 0 | 1 | \(|\) | 0 | 0 | 1 | 0 |
| 1 | 0 | \(|\) | 0 | 1 | 0 | 0 |
| 1 | 1 | \(|\) | 1 | 0 | 0 | 0 |
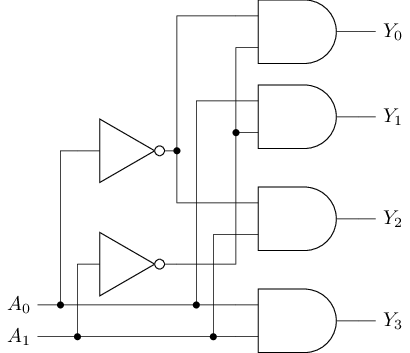
#T(2-4 dec) = 2#T(not) + 4#T(and) = 2 * 2 + 4 * 6 = 28
#T(5-32 dec) = 5#T(not) + 32#T(and5) = 5 * 2 + 32 * 12 = 394
#T(10-1024 dec) = 10#T(not) + 1024#T(and10) = 10 * 2 + 1024 * 22 = 22548编码器
\(2^n\)位输入, \(n\)位输出, 与译码器功能相反
- 若输入为独热码, 且第\(X\)位为
1, 则输出\(X\) - 常用于根据独热码生成地址: 找出
1的位置
例: 4-2编码器
| \(A_3\) | \(A_2\) | \(A_1\) | \(A_0\) | \(|\) | \(Y_1\) | \(Y_0\) |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | \(|\) | 0 | 0 |
| 0 | 0 | 1 | 0 | \(|\) | 0 | 1 |
| 0 | 1 | 0 | 0 | \(|\) | 1 | 0 |
| 1 | 0 | 0 | 0 | \(|\) | 1 | 1 |
| 其 | 他 | 情 | 况 | \(|\) | 0 | 0 |

#T(4-2 enc) = 4#T(not) + 4#T(and4) + 2#(or) = 4 * 2 + 4 * 10 + 2 * 6 = 60优先编码器
可支持独热码以外的输入, 但只编码优先级最高的位
- 常用于找出第一个
1的位置
例: 4-2优先编码器
| \(A_3\) | \(A_2\) | \(A_1\) | \(A_0\) | \(|\) | \(Y_1\) | \(Y_0\) |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | \(|\) | 0 | 0 |
| 0 | 0 | 1 | X | \(|\) | 0 | 1 |
| 0 | 1 | X | X | \(|\) | 1 | 0 |
| 1 | X | X | X | \(|\) | 1 | 1 |
| 其 | 他 | 情 | 况 | \(|\) | 0 | 0 |
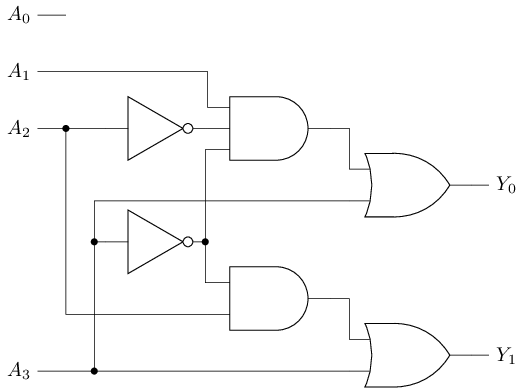
#T(4-2 prioenc) = 2#T(not) + #T(and3) + #T(and) + 2#(or) = 2 * 2 + 8 + 6 + 2 * 6 = 30多路选择器
根据选择端选择一路输入
- 将选择端看作地址,则类似一次寻址操作
例: 2选1多路选择器
| \(S\) | \(|\) | \(Y\) |
|---|---|---|
| 0 | \(|\) | \(D_0\) |
| 1 | \(|\) | \(D_1\) |
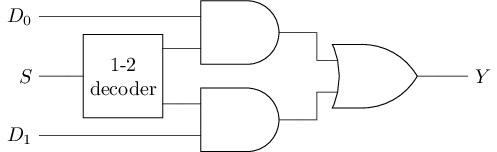
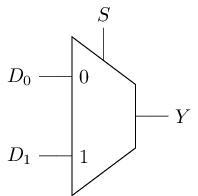
#T(2-1 mux) = #T(1-2 dec) + 2#T(and) + #(or) = #T(not) + 2 * 6 + 6 = 20
#T(2-1 mux32) = #T(1-2 dec) + 32(2#T(and) + #(or)) = 2 + 32 * (2 * 6 + 6) = 578对于数据位宽为\(M\)位的\(N\)选1多路选择器, \(\log_{2}{N}\)-\(N\)译码器的输出只有1位为1,
且可被\(M\)个\(N\)选1多路选择器复用
比较器
检查两个输入的每一位是否完全一致
例: 4位比较器
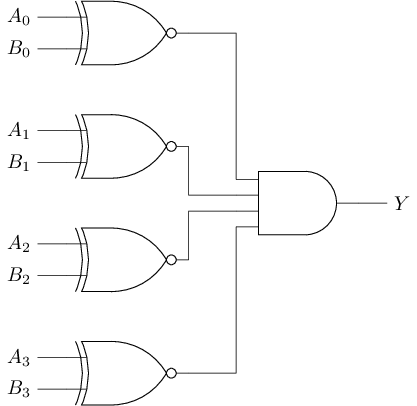
#T(cmp4) = 4#T(xnor) + #T(and4) = 4 * 6 + (4 + 4 + 2) = 34
#T(cmp32) = 32#T(xnor) + #T(and32) = 32 * 6 + (32 + 32 + 2) = 2581位加法器
- 半加器(Half Adder, HA) - 输入无进位的加法器
S = A ^ B
C = A & B#T(HA) = #T(xor) + #T(and) = 6 + 6 = 12- 全加器(Full Adder, FA) - 输入有进位的加法器
S = A ^ B ^ Cin
Cout = (A & B) | (Cin & (A ^ B))| \(A\) | \(B\) | \(|\) | \(S\) | \(C\) |
|---|---|---|---|---|
| 0 | 0 | \(|\) | 0 | 0 |
| 0 | 1 | \(|\) | 1 | 0 |
| 1 | 0 | \(|\) | 1 | 0 |
| 1 | 1 | \(|\) | 0 | 1 |
可以用两个半加器组成一个全加器
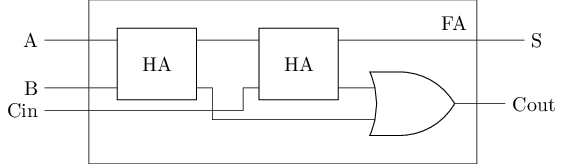
#T(FA) = 2#T(HA) + #T(or) = 2 * 12 + 6 = 30多位加法器
将低位FA的进位输出作为高位FA的进位输入
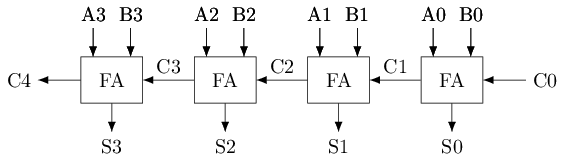
行波进位加法器(Ripple-Carry Adder, RCA)
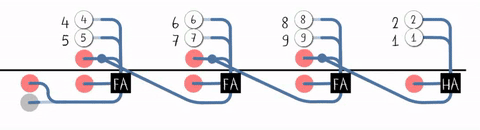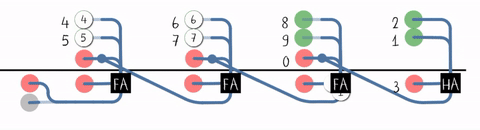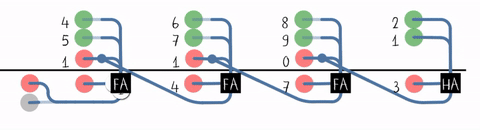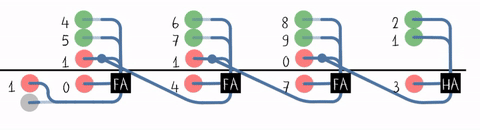
#T(RCA4) = #(HA) + 3#T(FA) = 12 + 3 * 30 = 102
#T(RCA32) = #(HA) + 31#T(FA) = 12 + 31 * 30 = 942交叉配对反相器(Cross-Coupled Inverters)
\(Q = A_{out} = \overline{A_{in}} = \overline{B_{out}} = \overline{\overline{B_{in}}} = \overline{\overline{Q}} = Q\) \(\overline{Q} = B_{out} = \overline{B_{in}} = \overline{A_{out}} = \overline{\overline{A_{in}}} = \overline{\overline{\overline{Q}}} = \overline{Q}\)
- \(Q\)和\(\overline{Q}\)都处于保持不变的稳定状态
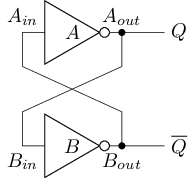
- 可稳定地存储1 bit信息(通过\(Q\)端输出)
- \(Q=0, \overline{Q}=1\),
则认为存储
0; \(Q=1, \overline{Q}=0\), 则认为存储1
- \(Q=0, \overline{Q}=1\),
则认为存储
设线延迟为\(T_w\), 反相器延迟为\(T_g\), 如果一开始\(Q=\overline{Q}=0\), 会怎样?
- \(T_w\)后, \(A_{in}=B_{in}=0\); \(T_g\)后, \(A_{out}=B_{out}=1=Q=\overline{Q}\)
- \(T_w\)后, \(A_{in}=B_{in}=1\); \(T_g\)后, \(A_{out}=B_{out}=0=Q=\overline{Q}\)
- 电路处于震荡状态, 无法表示稳定的信息(也称亚稳态)
不过, 即使上述电路位于稳定状态, 也使无法更新\(Q\)和\(\overline{Q}\)
更实用的存储单元 - SR锁存器
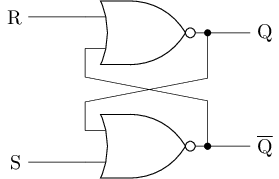
| S | R | \(|\) | Q |
|---|---|---|---|
| 0 | 0 | \(|\) | 保持 |
| 0 | 1 | \(|\) | 0 |
| 1 | 0 | \(|\) | 1 |
| 1 | 1 | \(|\) | 禁止 |
S(et)R(eset)锁存器, 其中S和R用于控制锁存器的状态
#T(SR latch) = 2#T(nor) = 2 * 4 = 8- 不允许S=R=1
- 或非门的特性使反馈功能失效, 此时输出均为0
- 从S=R=1变为S=R=0时, 会进入亚稳态
- 真实电路可能会受随机扰动而进入某个稳定状态, 但无法提前预知
- 每次工作可能会产生不同的结果(类似包含UB的程序)
避免亚稳态 - D锁存器
思想: 额外添加两个与门, 将SR锁存器的4种输入限制成3种合法输入
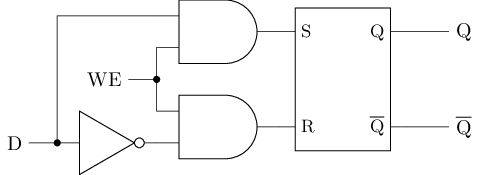
- D为输入数据
- WE为写使能(Write Enable)
#T(D latch) = #T(SR latch) + 2#T(and) + #T(not) = 8 + 2 * 6 + 2 = 22| WE | D | \(|\) | S | R | \(|\) | Q |
|---|---|---|---|---|---|---|
| 0 | 0 | \(|\) | 0 | 0 | \(|\) | 保持 |
| 0 | 1 | \(|\) | 0 | 0 | \(|\) | 保持 |
| 1 | 0 | \(|\) | 0 | 1 | \(|\) | 0 |
| 1 | 1 | \(|\) | 1 | 0 | \(|\) | 1 |
用与非门搭建的D锁存器
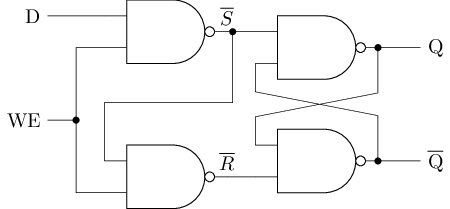
#T(D latch) = 4#T(nand) = 4 * 4 = 16面积更小
| WE | D | \(|\) | \(\overline{S}\) | \(\overline{R}\) | \(|\) | Q |
|---|---|---|---|---|---|---|
| 0 | 0 | \(|\) | 1 | 1 | \(|\) | 保持 |
| 0 | 1 | \(|\) | 1 | 1 | \(|\) | 保持 |
| 1 | 0 | \(|\) | 1 | 0 | \(|\) | 0 |
| 1 | 1 | \(|\) | 0 | 1 | \(|\) | 1 |
仅靠D锁存器无法实现同步电路的特性
同步电路: 存储单元仅在时钟边沿到达时写入数据, 且在该时钟周期中稳定读出该数据
D锁存器的性质: WE有效时, 输入的变化马上传播到输出
将时钟连到D锁存器的WE端仍然无法实现
- 假设上升沿触发
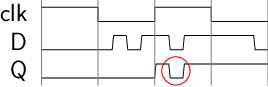
需要一种新的电路结构
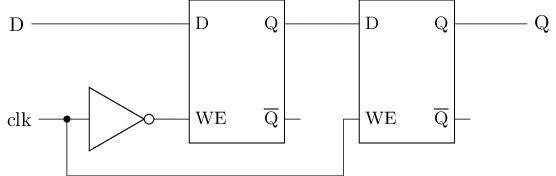
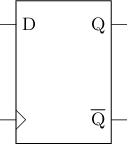
D触发器(D Flip-Flop, DFF)
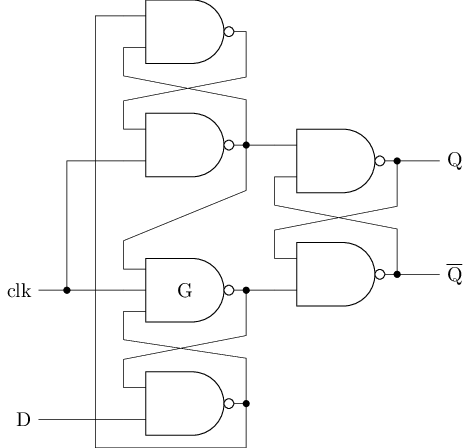
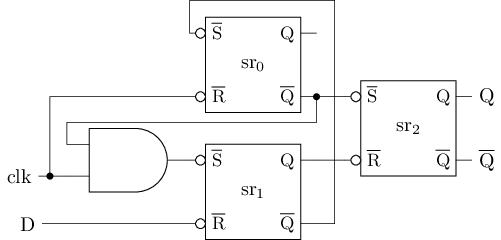

若将左上图的三输入与非门G(nand3)看成二输入与门(and2)和二输入与非门(nand2)的级联, 其行为等价于右上图
#T(DFF) = 5#T(nand) + #T(nand3) = 5 * 4 + 6 = 26D触发器的工作原理
| \(|\) | \(\mathrm{sr_0}\) | \(|\) | \(\mathrm{sr_1}\) | \(|\) | \(\mathrm{sr_2}\) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| clk | D | \(|\) | \(\mathrm{\overline{S}}\) | \(\mathrm{\overline{R}}\) | \(\mathrm{\overline{Q}}\) | \(|\) | \(\mathrm{\overline{S}}\) | \(\mathrm{\overline{R}}\) | \(\mathrm{Q}\) | \(\mathrm{\overline{Q}}\) | \(|\) | \(\mathrm{\overline{S}}\) | \(\mathrm{\overline{R}}\) | \(\mathrm{Q}\) |
| 0 | 0 | \(|\) | 1 | 0 | 1 | \(|\) | 0 | 0 | 1 | 1 | \(|\) | 1 | 1 | 保持 |
| 0 | 1 | \(|\) | 0 | 0 | 1 | \(|\) | 0 | 1 | 1 | 0 | \(|\) | 1 | 1 | 保持 |
| \(\uparrow\) | 0 | \(|\) | 1 | 1 | 1(保持) | \(|\) | 1 | 0 | 0 | 1 | \(|\) | 1 | 0 | 0 |
| 1 | 1 | \(|\) | 1 | 1 | 1(保持) | \(|\) | 1 | 1 | 0(保持) | 1(保持) | \(|\) | 1 | 0 | 0 |
| \(\uparrow\) | 1 | \(|\) | 0 | 1 | 0 | \(|\) | 0 | 1 | 1 | 0 | \(|\) | 0 | 1 | 1 |
| 1 | 0 | \(|\) | 1 | 1 | 0(保持) | \(|\) | 0 | 0 | 1 | 1 | \(|\) | 0 | 1 | 1 |
D触发器的核心思想:
- 时钟低电平期间, 通过\(\mathrm{sr_2}\)的保持功能, 保持其输出不变
- 时钟上升沿到来时, 根据输入D触发\(\mathrm{sr_2}\)的复位或置位功能, 以写入数据
- 时钟高电平期间, 通过\(\mathrm{sr_0}\)和\(\mathrm{sr_1}\)的保持功能, 使D的变化无法传播到\(\mathrm{sr_2}\)
带使能端的D触发器
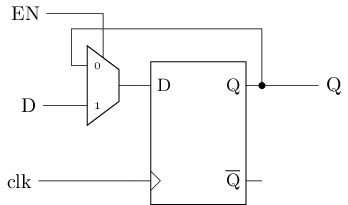
#T(DFFE) = #T(DFF) + #T(2-1 mux) = 26 + 20 = 46多加一个使能端, D触发器的晶体管数量增加77%!
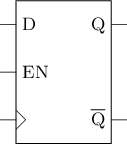
寄存器 = 可同时读写多位的结构
由多个D触发器组成
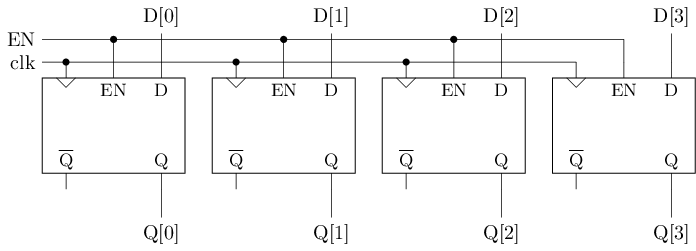
在RV32中, PC寄存器所需的晶体管数量约为:
#T(RV32.PC) = 32#T(DFFE) = 32 * 46 = 1472用D触发器实现存储器(读操作)
给定地址addr, 读出存储器中的相应内容
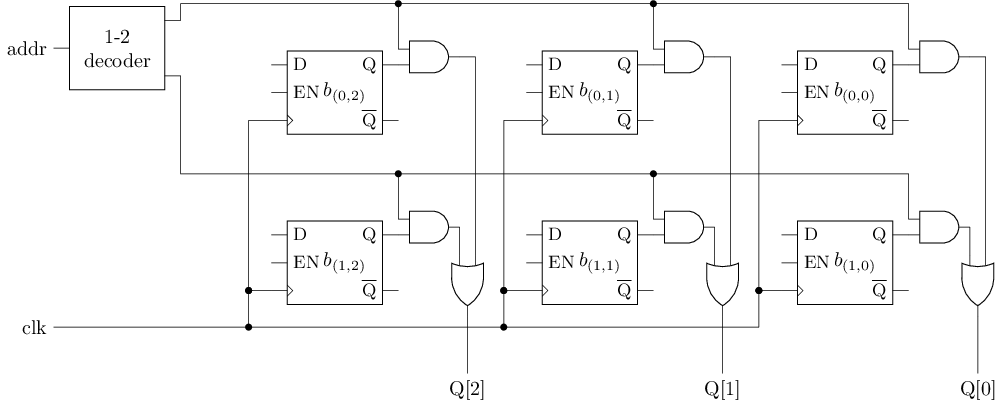
- 左上方的译码器又称
地址译码器 - 地址译码器, 与门和或门共同构成一个3位的2选1多路选择器
- 根据addr选出一行数据
用D触发器实现存储器(写操作)
给定地址addr和数据D, 将数据D写入存储器中的相应位置
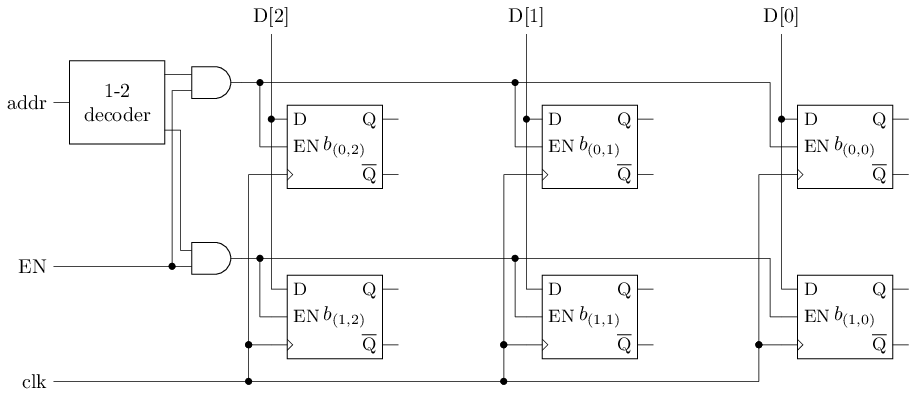
- 将数据D的每一位分别连接到每一行的D端
- 根据地址译码器的结果, 将需要写入的行所在的使能信号置1, 其余行的使能信号为0
用D触发器实现存储器(完整结构)
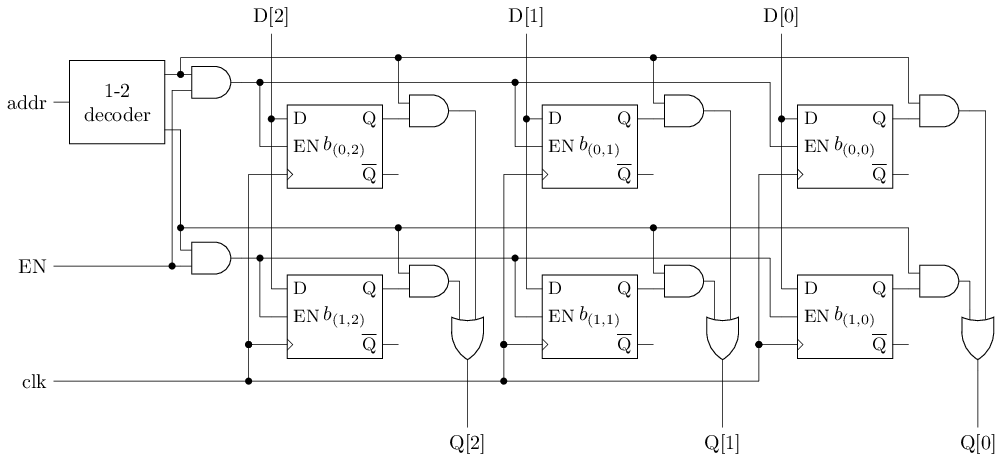
#T(3x2 RAM) = #T(1-2 dec) + 6#T(DFFE) + 8#T(and) + 3#(or) = 2+6*46+8*6+3*6 = 344
#T(RV32.Reg) = #T(32x32 RAM) =
#T(5-32 dec)
+ (32*32)#T(DFFE)
+ 32#T(and) // 生成一行的使能信号, 共32行
+ (32*32)#T(and) // 用于读出一行数据的与门, 其数量与D触发器相同
+ 32#T(or32) // 用于选出一位数据的或门, 输入端口数量=存储器深度, 或门数量=存储器宽度
= 394 + 1024 * 46 + 32 * 6 + 1024 * 6 + 32 * 66 = 55946面积更小的存储器 - SRAM
#T(32x32 RAM) = #T(5-32 dec) + 1024#T(DFFE) + 32#T(and) + 1024#T(and) + 32#T(or32)
= 394 + 1024 * 46 + 32 * 6 + 1024 * 6 + 32 * 66随着RAM的规模增加, 带使能端的D触发器的晶体管数量占主要部分
想法: 用面积更小的存储单元构成RAM
SRAM单元 - 在晶体管层面全定制!
- 只需6根晶体管

SRAM单元工作原理
- 空闲: 字线加低电压时, N1和N2截止, 无读写操作
- 读出: 向两根位线加高电压(接近逻辑1), 再向字线加高电压, 此时N1和N2导通, 根据存储的信息, 其中一根位线的电压轻微下降, 可通过放大电路检测并确定哪一根位线, 从而得知存储的信息是逻辑0还是逻辑1
- 写入: 将两根位线分别设置成逻辑0和逻辑1, 再向字线加高电压, 效果类似SR锁存器的复位和置位
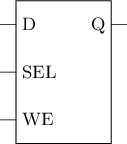
可将SRAM单元的行为抽象成一个锁存器(假设高电平有效)
- SEL有效时, Q端读出单元中数据
- SEL有效且WE有效时, 将D写入单元
用SRAM单元实现存储器
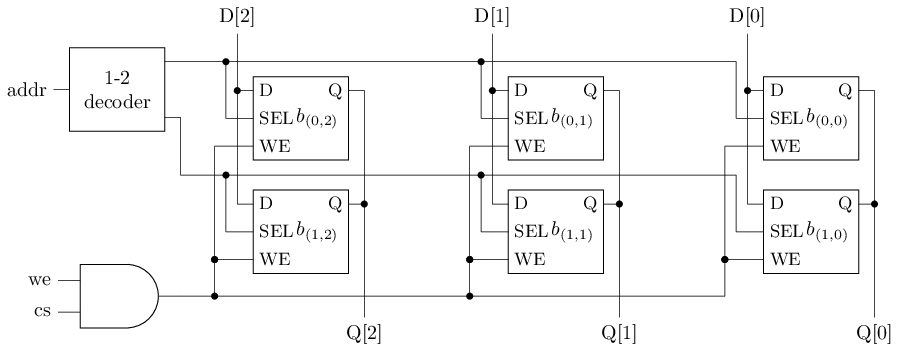
#T(3x2 RAM) = 344
#T(3x2 SRAM) = #T(1-2 dec) + 6#T(SRAM latch) + #T(and) = 2 + 6 * 6 + 6 = 44
#T(32x32 RAM) = 55946
#T(32x32 SRAM) = #T(5-32 dec) + (32*32)#T(SRAM latch) + #T(and)
= 394 + 1024 * 6 + 6
= 6544
如何解决锁存器不满足同步电路特性的问题?
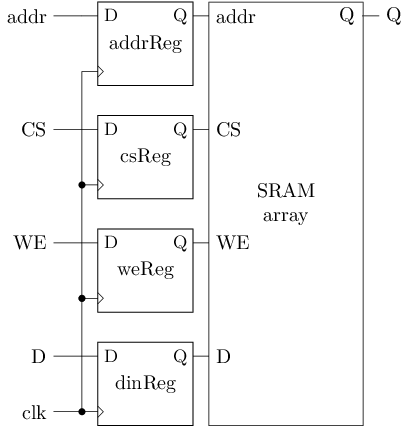
同步SRAM
提前用D触发器存放输入端
- 使SRAM的输入受时钟控制
- 好处: 能在同步电路中使用SRAM了
- 代价:
- D触发器带来额外的面积开销
- 但与存储阵列相比可忽略不计
- 读出数据时需要多等待一个周期
- D触发器需要在下个时钟上升沿到来时才会把D端数据传播到Q端
- D触发器带来额外的面积开销
Backup
主从式D触发器