



全面认识RISC-V指令集

- 从计算机系统软硬件协同的视角理解指令集
- RISC-V的设计对软硬件设计有何影响
- 指令集的7个评价标准
- 成本, 简洁, 性能, 架构与实现分离, 提升空间, 代码大小, 易于编程/编译/链接
- RISC-V指令集的最大特点 - 通过模块化应对不同的应用场景
- 指令扩展可自由组合 - 嵌入式(RV32E, RV32IC), 教学(RV64IMA), 桌面(RV64GC), 高性能(RV64GCBV)
- 通过自定义指令的模块化解决生态碎片化问题
- 用起来像是定长的变长指令集
- RISC-V指令集的若干设计案例
- 指令格式, 非法指令, 立即数符号扩展, 立即数编码方式…
AM是个多源文件的项目, 需要了解链接
- 现代工具链以源文件为单位进行编译/汇编, 然后链接成可执行文件
- 但编译/汇编都无法处理跨节的函数和数据引用
- 链接 = 符号解析 + 重定位
- 符号解析 = 将符号的引用与符号的定义建立关联
- 重定位 = 合并相同的节, 确定符号的最终地址, 并将其填写到引用处
// main.c
#include <stdio.h>
int a = 0, b = 0;
extern void f(), g();
int main() {
f(); printf("a = %d(0x%08x), b = %d(0x%08x)\n", a, a, b, b);
g(); printf("a = %d(0x%08x), b = %d(0x%08x)\n", a, a, b, b);
return 0;
}// f.c
void f() { extern float a; a = -1.0; }// g.c
void g() { extern double a; a = -1.0; }运行输出结果:
a = -1082130432(0xbf800000), b = 0(0x00000000)
a = 0(0x00000000), b = -1074790400(0xbff00000)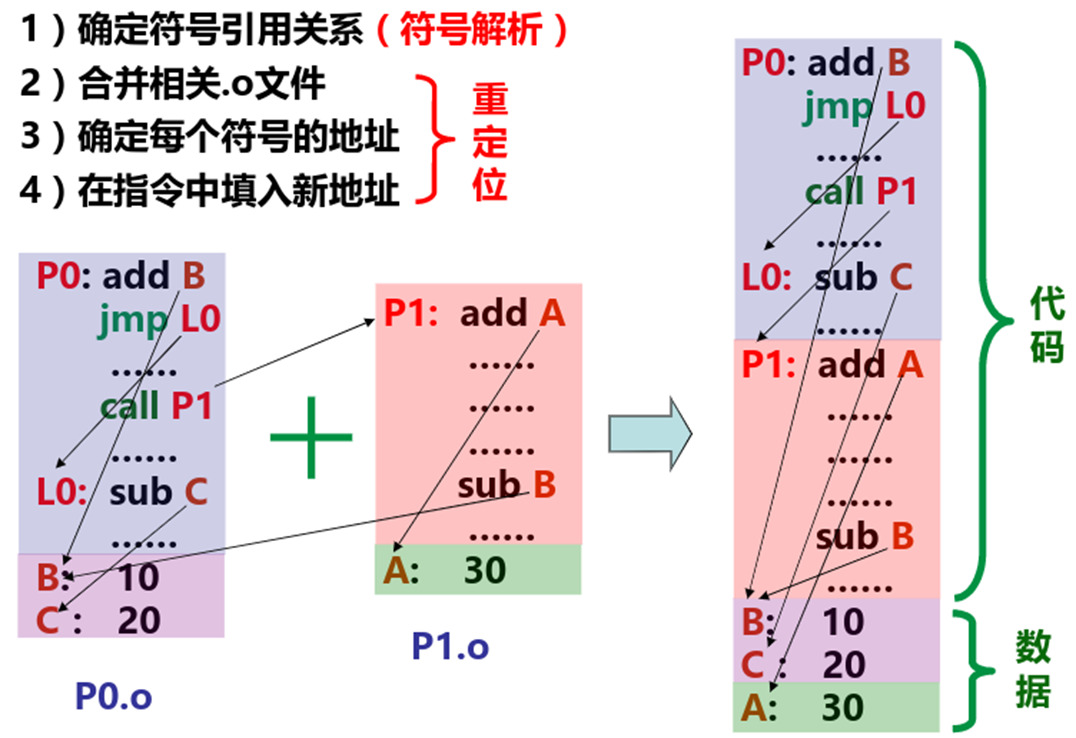
+IOE, 支持输入输出的计算机系统
- 物理世界
- 用户操作设备
- 设备的电气部分
- 将用户的操作转换成电气信号
- 设备控制器
- 将模拟信号转换成数字信号, 通过设备寄存器提供设备功能的抽象
- CPU I/O指令
- 访问这些设备寄存器, 让数字信号变成指令的操作数
- AM的IOE抽象
- 进一步提供I/O指令和常用设备的抽象
- 程序
- 用IOE的API编程, 实现游戏
加速器 - 功能单元

- 加法器 - RCA, CLA, CSA
- 乘法器 - Booth算法, 基4-Booth算法, 华莱士树
- 除法器 - 恢复余数法, 不恢复余数法, 高基SRT除法
A/B12~15 A/B8~11 A/B4~7 A/B0~3
|| || || ||
+---------------------------------------------+
S0~3 <--|------||--------||--------||------+ || |
S4~7 <--|------||--------||------+ || | || |
S8~11 <--|------||------+ || | || | || |
S12~15<--|-+ VV | VV | VV | VV |
| | +----+ +----+ +----+ +----+ |
| +-|4CLA|<-+ |4CLA|<-+ |4CLA|<-+ |4CLA|<--+--|--C0
| +----+ | +----+ | +----+ | +----+ | |
| || | || | || | || | |
| VV | VV | VV | VV | |
| +------------------------------------+ | |
| | P3G3 C12 P2G2 C8 P1G1 C4 P0G0| | |
C16 <--|--|C16 Carry Lookahead Unit(CLU) |<-+ |
| | PG GG | |
| +------------------------------------+ |
| 16-bit Carry-Lookahead Adder | | |
+---------------------------------------------+
| |
V V +----+ | | +----+
A4-->| |------+ | +-->| |-->S4
B4-->| FA | | +----->| FA |
C4-->| |---+ +-------->| |--+
+----+ | +----+ |
+-----+ +-----------+
+----+ | | +----+
A5-->| |------+ | +-->| |-->S5
B5-->| FA | | +----->| FA |
C5-->| |---+ +-------->| |--+
+----+ | +----+ |
+-----+ +-----------+
+----+ | | +----+
A6-->| |------+ | +-->| |-->S6
B6-->| FA | | +----->| FA |
C6-->| |---+ +-------->| |--+
+----+ | +----+ |性能bug
- 使用profiler发现性能瓶颈
- 了解程序的运行时间都花在哪里
99.99% 0.00% callgraph [unknown]
|
---0x64e258d4c544155
__libc_start_main
main
|
|--58.81%--A
| |
| |--23.57%--C
| |
| --23.52%--B
| |
| --11.78%--C
|
|--23.51%--B
| |
| --11.78%--C
|
--11.79%--C
通过构建计算机系统, 锻炼解决未知问题的能力
- 曾广森@华南理工大学,
电子科学与技术, 报名时大四
- 将学到的方法和思想应用到科研项目
通过构建计算机系统, 锻炼解决未知问题的能力(2)
- 王晨宇@南通大学,
计算机科学与技术, 报名时大二
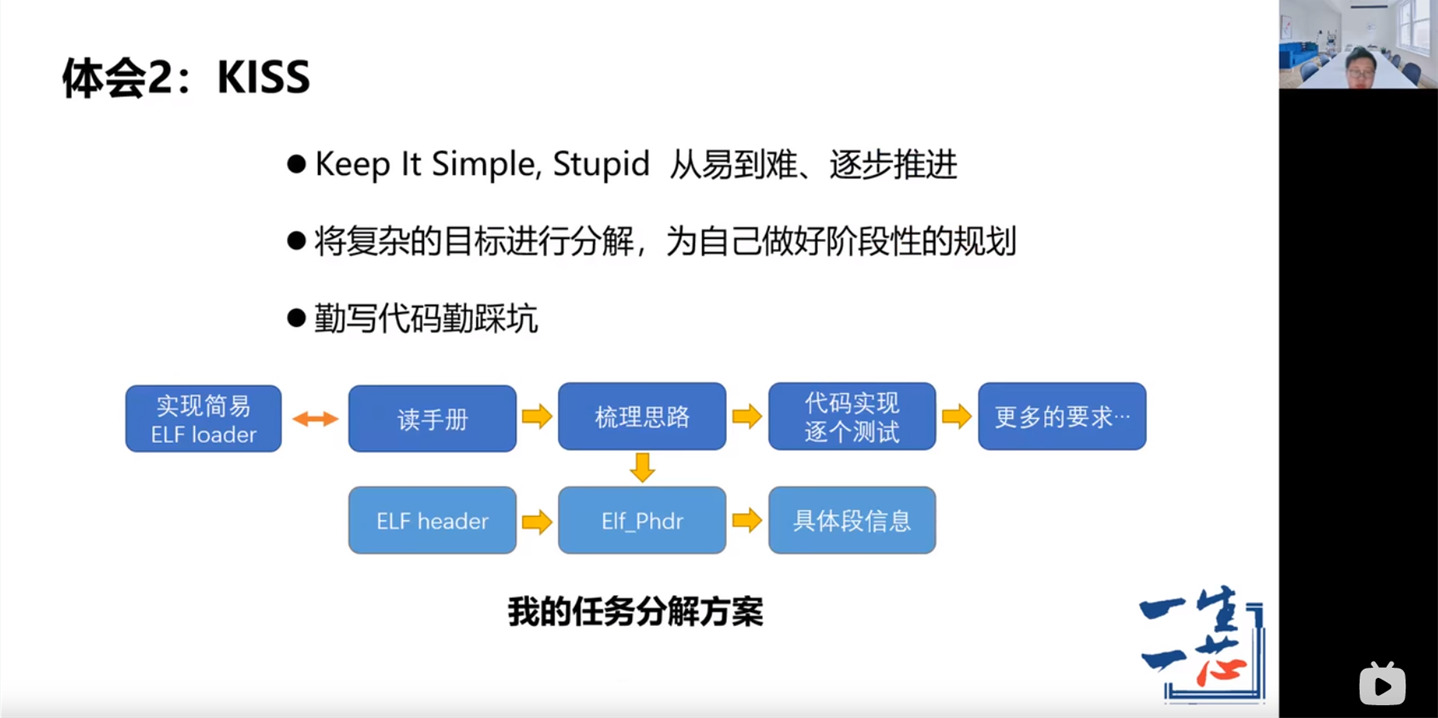
- 学会分解复杂目标, 逐步解决新问题
痛苦中的快乐: 重温把一件事情讲清楚的乐趣
- 如: CLA引入P和G只是换个角度理解进位, 为什么能降低进位延迟?
- 研一上过胡老师的系统结构课, 当时也没细想这个问题
- 这次备课思考了本质原因 - 通过表达式变换对电路进行平衡处理
- 果然读了博士还是会本能地追求事物的本质(职业病 😂)
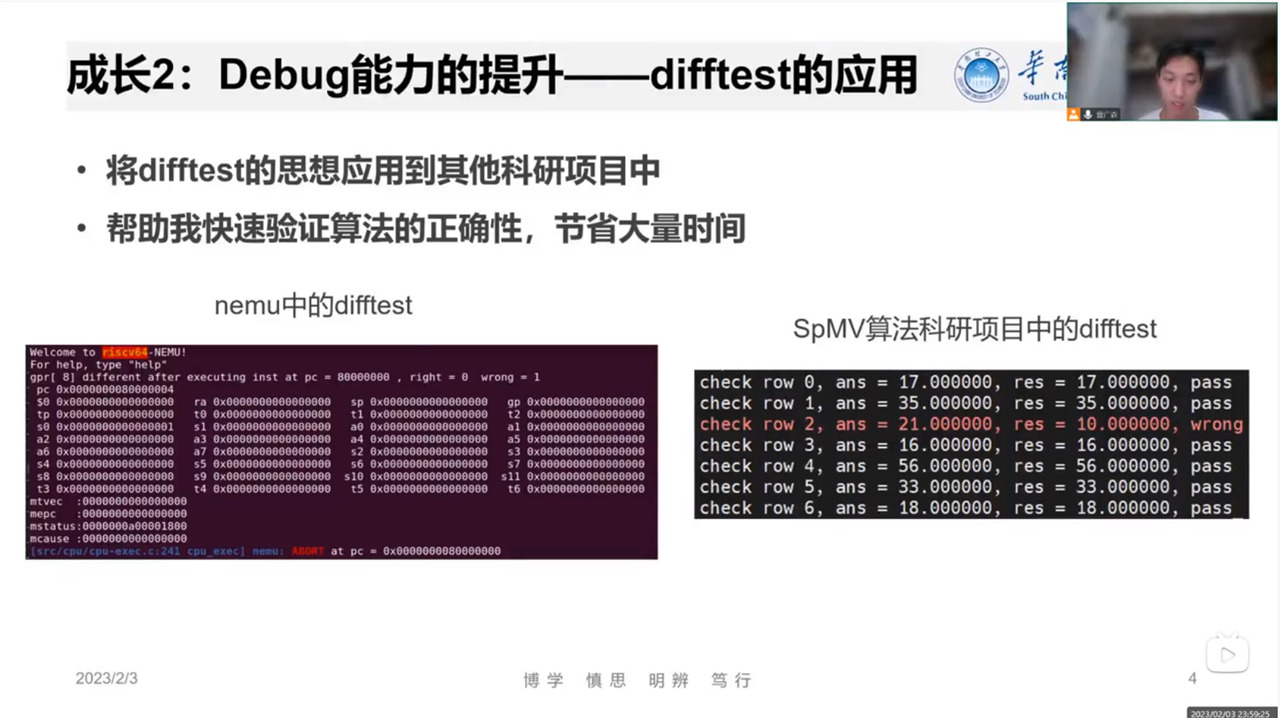
- 更多例子: DiffTest的好处, 行为建模的问题, 总线从简单到复杂的过渡…

It's very satisfying to take a problem we thought difficult and find a simple solution. The best solutions are always simple.
-- Ivan Sutherland
教学的 “神之一手” - 用简单的话将一件复杂的事情讲清楚