



神秘嘉宾
我们邀请了香山团队的同学在年后给大家分享若干技术报告
- 内容涵盖处理器前端, 处理器后端, 访存, 缓存, 性能评估方法, 工具基础设施等高阶话题
- 从2月18日开始, 每周六晚上19:00~21:00, 持续6周
算是给大家凑一个S阶段 😂
这样我就可以 🕊🕊🕊 了
引言
经典体系结构的4类优化方法, 我们已经介绍了其中两类
- 今天给大家介绍剩下两类 - 并行/预测
- 其中介绍指令级并行 - 指令流水线
听完这节课, 你就知道为什么我们最后才讲流水线了
流水线的概念和基本结构
工厂流水线

- 组装 -> 贴纸 -> 包装袋 -> 包装盒 -> 外检
- 员工视角 - 每位员工分别负责一个产品对象的一项任务
- 产品视角 - 每个产品对象在不同时刻由不同员工完成不同任务
指令流水线 - 一种指令级并行技术
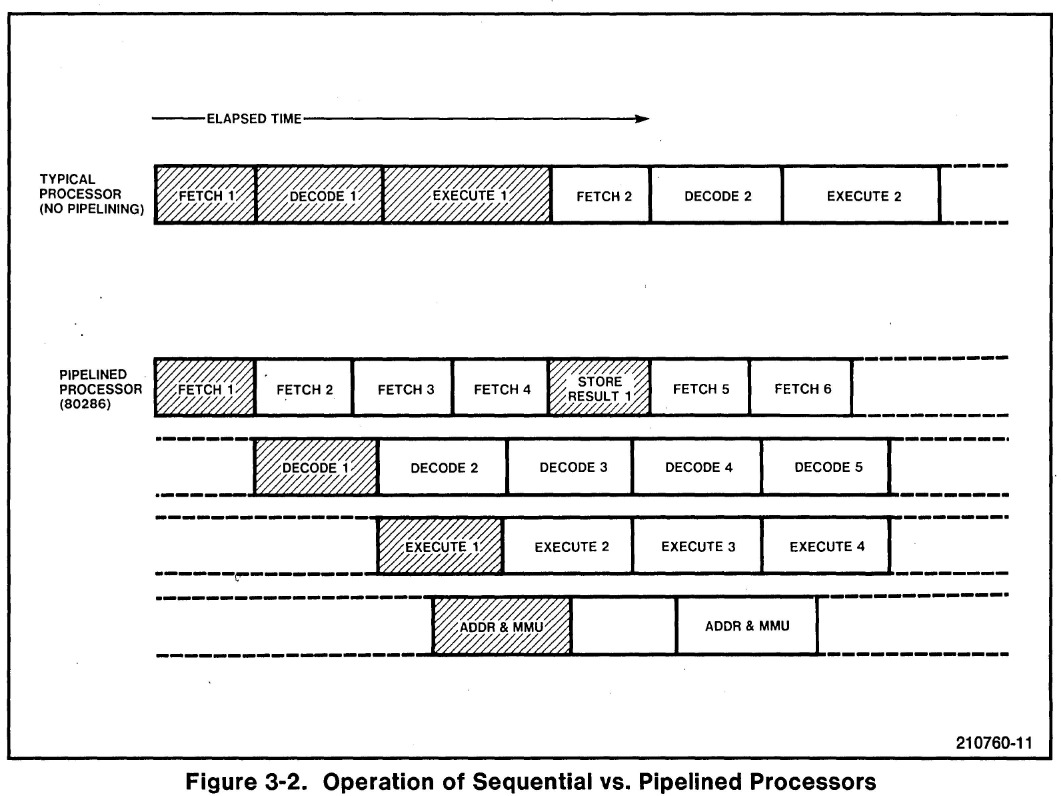
- 将指令的执行过程划分为不同阶段: 取指 -> 译码 -> 执行 ->
访存
- 阶段视角 - 每个阶段分别负责一条指令的一项任务
- 指令视角 - 每条指令在不同时刻由不同阶段完成不同任务
指令流水线的阶段划分
教科书上的经典5级流水线: 取指 -> 译码 -> 执行 -> 访存 -> 写回
- 将访存单独作为一个阶段的考虑
- 假设访存延迟为0周期, 即理想存储器
- 地址计算(加法器)的路径和访存路径加起来太长
- 拆分为两个阶段更均衡
但在实际的处理器设计中, 上述假设不再成立
- 回顾SoC: 访存操作一般需要多个周期
- 500MHz的CPU访问100MHz的SDRAM, 读延迟需要30周期
- 回顾cache: 缓存的控制逻辑是个状态机
- 即使命中, 状态机也需要经过若干周期的控制才能读出数据
- 访存路径上有很多地址寄存器, 地址计算的延迟和资源开销并不明显
实际中的阶段划分
将访存单独作为一个阶段并无好处
- 一般将其并入执行阶段, LSU可以看成一个特殊的功能单元
/--- frontend ---\ /-------- backend --------\
+-----+ <--- 3. computation efficiency
+--> | FU | --+
+-----+ +-----+ | +-----+ | +-----+
| IFU | --> | IDU | --+ +--> | WBU |
+-----+ +-----+ | +-----+ | +-----+
^ +--> | LSU | --+
| +-----+
1. instruction supply ^
2. data supply --+- 如果你想实现乱序超标量处理器, 建议不要采用教科书的经典5级流水
- 迟早要重构
- 果壳也这样, 但在IDU后增加ISU(ISsue Unit), 用于判断操作数是否就绪
- 我们后面会讨论数据冒险
流水线的基本结构
接下来我们讨论4级流水线: 取指 -> 译码 -> 执行(合并了访存) -> 写回
单周期:
+-----+ inst ---> +-----+ ... ---> +-----+ ... ---> +-----+
| IFU | valid ---> | IDU | valid ---> | EXU | valid ---> | WBU |
+-----+ <--- ready +-----+ <--- ready +-----+ <--- ready +-----+流水线:
+----+ <- stage reg +----+ +----+
+-----+ -> |inst| -> +-----+ -> |....| -> +-----+ -> |....| -> +-----+
| | +----+ | | +----+ | | +----+ | |
| IFU | valid ---> | IDU | valid ---> | EXU | valid ---> | WBU |
| | | | | | | |
+-----+ <--- ready +-----+ <--- ready +-----+ <--- ready +-----+握手时消息传递到下一级流水, 否则等待
从逻辑上理解, 流水段寄存器也可以位于下游模块内部, 作为接收消息的缓冲区
- 根据总线的行为, 握手成功后, 上游模块将不再保存该消息
流水线的简单性能分析
假设取指, 译码, 执行, 写回的延迟都是1ns(先不考虑访存)
- 单周期处理器 - 无流水段寄存器
- 关键路径为4ns, 主频能跑250MHz
- 一条指令需要执行1周期 = 4ns
- 每1周期 = 4ns执行一条指令
- 流水线处理器 - 有流水段寄存器
- 关键路径为1ns, 主频能跑1GHz
- 一条指令需要执行4周期 = 4ns
- 每1周期 = 1ns执行一条指令
- 本质上是因为指令级并行: 每个周期都在处理4条不同的指令
上面只是理想情况, 实际上有很多问题需要解决
冒险及其简单处理
冒险(Hazard)
在流水线中, 当前周期不能执行当前指令的情况
- 强行执行可能会导致指令结果错误
- ISA状态机和CPU状态机的状态不一致
在流水线设计中需要检测出冒险, 并正确处理它们
结构冒险
流水线中的不同阶段需要同时访问同一个部件
- IF和EX中的LSU都需要访内
- T4的I2与I4
- ID和WB都需要访问通用寄存器
- T4的I1与I3
T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: add | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I2: ld | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I3: sub | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I4: xor | IF | ID | EX | WB |
+----+----+----+----+结构冒险的检测和处理
大部分结构冒险可从设计上完全避免, 使其在CPU执行过程中不会发生
- 避免方式 - 为物理上的一个部件添加多个处理单元
- 因此也不必检测
- 寄存器 - 独立实现读口和写口
- 内存
- 实现真双口内存
- 将内存分为指令存储器和数据存储器
- 教科书上的坑方案, 违反ISA的内存模型(指令和数据共享存储器)
- 在这个内存模型中, 无法实现类似loader加载程序的功能
- 教科书上的坑方案, 违反ISA的内存模型(指令和数据共享存储器)
- 引入icache和dcache
- 靠谱, 既达到了双口的效果, 又不违反ISA的内存模型
- 后者由icache和dcache之间的一致性协议保证
- 靠谱, 既达到了双口的效果, 又不违反ISA的内存模型
结构冒险的检测和处理(2)
有一些结构冒险还是无法完全避免
- SDRAM控制器的队列(快)满了
- 除法器要算65个周期, 很难流水化
- 多发射处理器中, 希望一周期发射多条算术指令, 但只有一个ALU
处理方式: 等
一个好消息: 如果我们从总线视角来看, 就无需实现专门的结构冒险检测和处理逻辑
- 把结构冒险的检测和处理归约到总线状态机
- 从设备/下游模块/仲裁器把ready置0即可
数据冒险
不同阶段的指令依赖同一个寄存器数据, 且至少有一条指令写入该寄存器
- I1需要写a0, 但要在T4结束时才完成写入
- I2在T3读a0, 读到旧值
- I3在T4读a0, 读到旧值
- I4在T5读a0, 读到新值
T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: add a0,t0,s0 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I2: sub a1,a0,t0 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I3: and a2,a0,s0 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I4: xor a3,a0,t1 | IF | ID | EX | WB |
+----+----+----+----+上述数据冒险称为写后读(Read After Write, RAW)冒险
RAW的检测和处理 - 1. 编译器检测, 插入空指令
T1 T2 T3 T4 T5 T6 T7 T8 T9
+----+----+----+----+
I1: add a0,t0,s0 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I2: nop | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I3: nop | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I4: sub a1,a0,t0 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I5: and a2,a0,s0 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I6: xor a3,a0,t1 | IF | ID | EX | WB |
+----+----+----+----+RAW的检测和处理 - 2. 编译器检测, 进行指令调度
编译器尝试寻找一些没有数据依赖关系的指令, 在不影响程序行为的情况下调整其顺序
(1) add a0,t0,s0 (1) add a0,t0,s0
(2) sub a1,a0,t0 (5) add t5,t4,t3
(3) and a2,a0,s0 ---> (6) add s5,s4,s3
(4) xor a3,a0,t1 (2) sub a1,a0,t0
(5) add t5,t4,t3 (3) and a2,a0,s0
(6) add s5,s4,s3 (4) xor a3,a0,t1编译器只能尽力而为, 实在找不到, 就只能插入nop
- 假设除法需要执行65个周期
- 但一般很难找到这么多指令来调度 😂
- 用先进的SRT-16除法器也需要17个周期, 也很难找
光靠编译器不能解决所有问题
考虑load-use冒险(一种特殊的RAW冒险)
T1 T2 T3 .... T? T? T? T? T?
+----+----+--------------+----+
I1: ld a0,t0,s0 | IF | ID | EX | WB |
+----+----+--------------+----+
+----+----+----+----+
I?: nop X 30? | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I?: sub a1,a0,t0 | IF | ID | EX | WB |
+----+----+----+----+在真实的SoC中, 软件几乎无法预测访存延迟 😂
- cache命中 - 可能3周期
- cache缺失访问SDRAM - 可能30周期
- 正好碰上SDRAM充电刷新 - 可能30+?周期
- CPU频率升到600MHz(SDRAM频率不变), 访存延迟的周期数更多了
RAW的检测和处理 - 3. 硬件检测, 插入气泡
采用计分板(scoreboard)为每个通用寄存器记录是否将要被写入
- 分配一个32bit的数组Busy
- 在ID阶段, 若指令需要写入R(x), 则将Busy(x)置1
- 在WB阶段, 若指令需要写入R(x), 则将Busy(x)清0
- 在ID阶段, 若指令需要读出R(x), 且Busy(x)为1, 则发生RAW冒险
检测到RAW冒险后的一种简单处理方式: 等
- 这好办, IDU把ready置0即可
- 不理解为什么教科书上说 “控制相当复杂” 😂
果壳将计分板的维护放在IS阶段, 避免ID阶段的工作过多成为关键路径
通过硬件阻塞方式处理RAW
T1 T2 T3 T4 T5 T6 T7 T8 T9
+----+----+----+----+
I1: add a0,t0,s0 | IF | ID | EX | WB |
+----+----+----+----+
+----+--------------+----+----+
I2: sub a1,a0,t0 | IF | ID | EX | WB |
+----+--------------+----+----+
+--------------+----+----+----+
I3: and a2,a0,s0 | IF | ID | EX | WB |
+--------------+----+----+----+
+----+----+----+----+
I4 xor a3,a0,t1 | IF | ID | EX | WB |
+----+----+----+----+其实scoreboard是个很好的检测方案
- 只记录忙碌状态, 无需提前知道指令何时执行结束
- 适用于除法, load-use冒险等
- 甚至插入新的流水级, 都无需修改scoreboard相关代码
- 本质: 减少代码中的隐含依赖(执行xxx指令需要y周期)
控制冒险
跳转指令会改变指令执行顺序, 导致IFU可能会取到不该执行的指令
I4需要等到beq指令在T5计算出跳转结果, 才知道应该取哪条指令
T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: 100 add | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I2: 104 ld | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I3: 108 beq 200 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I4: ??? ??? | IF | ID | EX | WB |
+----+----+----+----+检测方法: 可以在IFU中进行预译码(pre-decode), 专门识别跳转指令
一种简单的解决方案: 等
异常引起的控制冒险
T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: add | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I2: ld | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I3: 00000000 | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I4: ??? (fetch error) | IF | ID | EX | WB |
+----+----+----+----+ T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: add | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+
I2: ld | IF | ID | EX |
+----+----+----+
+----+----+
I3: 00000000 | IF | ID |
+----+----+
+----+
I4: ??? (fetch error) | IF |
+----+
+----+----+----+----+
I5: inst pointed by mtvec | IF | ID | EX | WB |
+----+----+----+----+若在T4时ld指令发生地址不对齐异常, 则需要冲刷ld指令以及更年轻的指令, 使其不继续执行
- 冲刷 = valid清0
- 冲刷时注意不要改变ISA状态
- 冲刷后从mtvec所指位置重新取指
根据异常的类型更新mcause和mepc
- 为了正确更新mepc, 需要随流水线传播指令PC
- 若在同一时刻多个阶段同时发生异常, 则应处理最老的指令
流水线中的中断/异常处理
检测各种RISC-V异常的模块
0 - Instruction address misaligned - IFU
1 - Instruction access fault - IFU
2 - Illegal Instruction - IDU
3 - Breakpoint - IDU
4 - Load address misaligned - LSU
5 - Load access fault - LSU
6 - Store/AMO address misaligned - LSU
7 - Store/AMO access fault - LSU
8 - Environment call from U-mode - IDU
9 - Environment call from S-mode - IDU
11 - Environment call from M-mode - IDU
12 - Instruction page fault - IFU
13 - Load page fault - LSU
15 - Store/AMO page fault - LSU
中断可在任意指令的任意阶段捕获并处理
- 因为中断是异步的, 延迟若干周期处理并不违反中断的语义
让流水线流起来
先完成, 后完美
实现了简单的冒险处理后, NPC就可以跑仙剑了
但我们刚才只是粗暴地阻塞来解决冒险, 现在可以思考如何尽可能消除阻塞, 让流水线流起来
阻塞的来源有很多, 我们希望了解阻塞最频繁的来源
通过性能计数器进行profiling!
- 在阻塞来源添加性能计数器, 统计阻塞事件发生的次数/周期数
- 如果你对CPU的细节足够熟悉, 你甚至能用性能计数器列出若干等式
- 并且用这些等式预测一项技术的性能提升
根据当前的设计, 你觉得阻塞最频繁的事件是什么?
- 你不一定能马上想明白, 所以profiling非常重要
cache!
我们之前的cache都是状态机控制的
- 一次只能处理一个cache访问请求
- 即使命中, 也需要多个周期才能读出cache中的内容
T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11 T12
+--------------+----+----+----+
I1 | IF | ID | EX | WB |
+--------------+----+----+----+
+--------------+----+----+----+
I2 | IF | ID | EX | WB |
+--------------+----+----+----+
+--------------+----+----+----+
I3 | IF | ID | EX | WB |
+--------------+----+----+----+- 每次取指令都要等几个周期, 这根本没法流水啊 😂
- 指令供给跟不上, CPU只能空转, 再高级的技术, 都是形同虚设
- 所以我们目前用最简单的阻塞方式来处理冒险就可以了
- 所以在第四期, cache变成必做内容了, 并且安排在流水线前面
减少结构冒险的阻塞 - cache
我们希望icache在连续命中的情况下, 每周期都能读出指令
- 解决方案 - 将icache流水化
- 根据icache命中的状态转移过程设计流水线
- 如果缺失, 则阻塞流水线并等待访存结果
T1 T2 T3 T4 T5 T6 T7 T8
+----+----+----+----+----+----+
I1 | IF1| IF2| IF3| ID | EX | WB |
+----+----+----+----+----+----+
+----+----+----+----+----+----+
I2 | IF1| IF2| IF3| ID | EX | WB |
+----+----+----+----+----+----+
+----+----+----+----+----+----+
I3 | IF1| IF2| IF3| ID | EX | WB |
+----+----+----+----+----+----+通过这种方式, 指令供给断开的概率 = icache缺失率
dcache可以保留状态机的设计, 可以认为LSU一次只能处理一条访存指令
- 可profiling统计连续访存的频率, 并估算dcache流水化的性能收益
减少结构冒险的阻塞 - 乘除法器
- 单周期的乘除法器延迟较长, 会拉低处理器的频率, 一般不采用
- 多周期的乘除法器也会存在结构冒险
- 状态机一次只能处理一个请求
- 为了解决结构冒险, 可以将乘法器流水化
- 在华莱士树中间插入若干流水段寄存器即可
- 多条乘法指令可流水执行, 性能提升取决于程序的profiling结果
T1 T2 T3 T4 T5 T6 T7 T8
+----+----+----+----+----+----+----+----+
I1: mul | IF1| IF2| IF3| ID |MUL1|MUL2|MUL3| WB |
+----+----+----+----+----+----+----+----+
+----+----+----+----+----+----+----+----+
I2: mul | IF1| IF2| IF3| ID |MUL1|MUL2|MUL3| WB |
+----+----+----+----+----+----+----+----+
+----+----+----+----+----+----+----+----+
I3: mul | IF1| IF2| IF3| ID |MUL1|MUL2|MUL3| WB |
+----+----+----+----+----+----+----+----+除法器较难流水化, 一般采用多周期
减少数据冒险的阻塞
一个想法: 计算指令结果并非WB阶段才产生, 能否提前拿到?
T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: add a0,t0,s0 | IF | ID | EX | WB |
+----+----+----+----+
+----+--------------+----+----+
I2: sub a1,a0,t0 | IF | ID | EX | WB |
+----+--------------+----+----+
+----+----+----+----+
I1: add a0,t0,s0 | IF | ID | EX | WB |
+----+----+----+----+
|
V
+----+----+----+----+
I2: sub a1,a0,t0 | IF | ID | EX | WB |
+----+----+----+----+I1中a0的新值在T4时刻已经可以从EX-WB的流水段寄存器中读出
- 这种技术叫转发(forward)或旁路(bypass)
数据转发
还需要根据寄存器号码判断是否可以转发
- 当EX-WB级中需要写入的寄存器号码, 与ID-EX级中需要读出的寄存器号码一致, 才可以转发
- 此时可以无视scoreboard中的记录
一个考察大家训练是否到位的问题: CSR指令的转发需要注意什么?
- 如果你的第一反应不是profiling, 就应该反思了
- 实际运行过程中CSR指令占比非常小, 优化它们的整体收益几乎为零
- 在乱序执行处理器中甚至会让它们串行执行
减少控制冒险的阻塞
想法: 与其被动等待, 不如主动出击
- 分支指令只有两种执行结果 - 跳转(taken)和不跳转(not taken)
- 那就猜一种试试, 猜对了就赚了
- 猜错了就刷掉, 性能上和阻塞相比没吃亏, 设计上要加一些控制逻辑
这就是分支预测, 属于投机执行技术, 有固定模式: 投机执行-检查-恢复
- 投机执行 = IFU取指时预测一个分支的方向
- 有不同的预测算法
- 检查 = 分支指令在ALU中计算结果, 看与之前预测的方向是否一致
- 所以需要将IFU的预测结果传递到ALU检查
- 恢复 = 若预测错误, 则冲刷取错的指令, 并从正确的分支重新取指
- 冲刷 = valid清0, 和异常的冲刷类似
静态分支预测
仅根据指令本身来预测
- 方案1 - 总是预测跳转/不跳转
- 实现简单, 但准确率低
- 方案2 - 向前方(新指令)跳转时预测不跳转, 向后方(老指令)跳转时预测跳转
- 其实这和循环的行为有关
- 向前方跳转会跳过中间的代码, 可能是循环出口 -> 偏向不跳转
- 向后方跳转会重新执行之前的代码, 可能是循环体 -> 偏向跳转
- RISC-V手册也建议编译器按照上述模式生成代码
Software should also assume that backward branches will be predicted taken and forward branches as not taken, at least the first time they are encountered.- 实现起来也不难 - 看B型指令offset的符号位即可
- 在低端处理器中也容易实现
- 其实这和循环的行为有关
动态分支预测
根据分支指令在过去一段时间内的历史行为来预测当前行为
- 需要通过一张表来记录历史行为 - BHT(Branch History Table)
- 有时也称BTB(Branch Target Buffer)
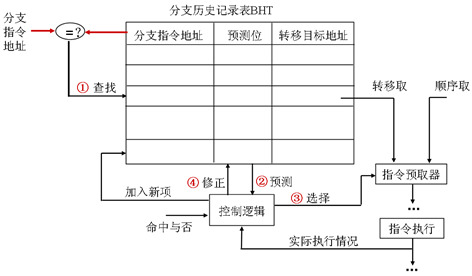
- 通过当前PC查表, 若缺失, 则认为不是分支指令, 因此顺序取指
- 若命中, 则根据预测位的状态决定是否跳转到目标地址
- ALU计算出分支结果时会更新此表 - 插入新表项或更新预测位
预测位的状态维护
一般采用饱和计数器
- 每次ALU计算出分支结果时, 更新计数器
- 若实际结果为跳转, 则计数器加1
- 若计数器已达到最大值, 则不加
- 若实际结果为不跳转, 则计数器减1
- 若计数器已达到最小值, 则不减
- 若实际结果为跳转, 则计数器加1
- 通过计数器最高位预测是否跳转, 计数器的值反映出置信度
- 可设计1/2位饱和计数器: 位数越多, 可以容忍越多意外情况
分支预测器如何设计, 是一个体系结构的设计空间探索问题
- 和cache类似, 一般先通过功能模拟器统计分支预测的准确率
- 可输入分支trace来统计
更多指令的预测
- jal指令 - 跳转目标固定, 填入BHT后可100%预测正确
- jalr指令 - 跳转目标和寄存器的值有关, 较难预测
- ret指令 - 一般和call配对, 可维护RAS(Return Address
Stack)预测器提高预测准确率
- 执行call指令时将下一条指令的PC压入RAS
- 执行ret指令时弹出RAS, 并将弹出元素作为预测的跳转目标
- 和ftrace非常类似, RTFM有惊喜
- RAS深度与程序的函数调用层数有关 - 用ftrace profiling
- 溢出时可覆盖旧的项
- 一般的jalr指令 - 可预测与上次相同的跳转地址
- ret指令 - 一般和call配对, 可维护RAS(Return Address
Stack)预测器提高预测准确率
分支预测的其他事项
分支预测的准确率直接影响指令供给, 在乱序执行处理器中更重要
- 预测错误的代价非常高
- 香山每周期能取32B的指令, 最少8条4B指令, 最多16条RVC指令
- 在第10级计算分支结果, 若分支预测错误, 则冲刷80~160条指令!
- 香山采用多种分支预测器结合的设计
- 香山每周期能取32B的指令, 最少8条4B指令, 最多16条RVC指令
分支指令的计算结束前, 后续指令的执行都是投机的, 可能被冲刷
- 不应该随意修改ISA状态 - 否则冲刷时无法恢复到正确的状态
- I/O也不能投机访问 - 一旦访问就会改变设备状态
- 在基础流水线中一般不会发生, 但也应该仔细斟酌!
fence.i的处理
fence.i指令的语义是, 让fence.i之后的取指操作可以看到fence.i之前的store结果
- 但在fence.i执行完之前, 流水线可能已经取出若干指令
- 这些指令是在fence.i生效前取出的, 不应执行, 因此需要冲刷
T1 T2 T3 T4 T5 T6 T7
+----+----+----+----+
I1: add | IF | ID | EX | WB |
+----+----+----+----+
+----+----+----+----+
I2: fence.i | IF | ID | EX | WB |
+----+----+----+----+
+----+
I3: ??? may be stale | IF |
+----+
+----+----+----+----+
I4: sub | IF | ID | EX | WB |
+----+----+----+----+也即, 在保证icache和dcache一致性的基础上, 再冲刷流水线, 可保证后续取指操作能看到之前的store结果
测试福利 - 模糊测试
流水线架构比较复杂
这么多流水级, 若每一级指令类型不同, 可能会有不同的行为
- 加/减/逻辑/移位等可通过ALU一周期计算结果的指令
- 分支指令, 又分3种: 条件分支, jal, jalr
- 访存指令, 又分2种: load, store
- 乘法指令, 除法指令
- CSR指令, ecall, fence.i
共11种指令
只考虑4级流水线, 也有\(11^4=14641\)种可能
- 还要考虑访存指令可能发生cache缺失
- 还要考虑数据依赖: 每条指令最多可依赖两条比它老的指令
你不会愿意设计那么多测试用例的 😂
模糊测试 - 让工具自动生成测试
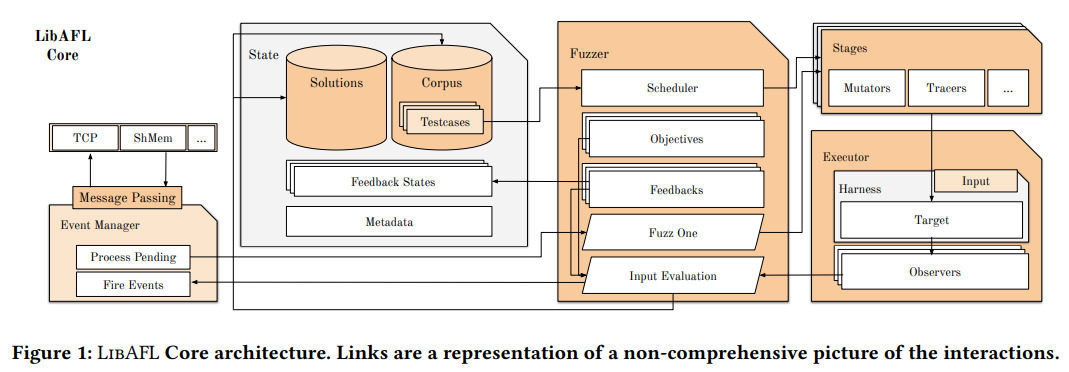
- corpus - 提供少数的测试输入
- mutator - 变异模块, 通过某些算法(如遗传算法)生成新的输入
- executor - 在我们的场景中就是仿真环境, observer是DiffTest
- input evaluation - 用于评估输入的指标
- fuzzer - 根据评估指标决定如何生成下一轮测试
总结
教科书的流水线设计 != 真实的流水线设计
大部分教科书已经把流水线的原理讲得很清晰了
- 但有些假设在实际中并不成立: 0周期延迟的理想存储器, 多个周期才能完成的指令
我们有足够理由把流水线放在最后讲, 来介绍真实的流水线设计
- 站在全局的角度理解各个模块之间的影响
- 既包括硬件之间, 也包括硬件-ISA-软件
- 通过性能计数器科学地定位流水线当前的性能瓶颈
- 面向教科书设计, 看图写RTL代码 ✖️
- 面向profiling设计, 提出合理的优化方案 ✔️
- 使用现代工具对设计进行测试和调试
- libAFL, trace等