



引言
我们已经了解整个SoC计算机系统如何执行程序了
本次课内容: 体系结构优化
- 性能评估
- 缓存的设计
- 设计空间探索
- 缓存和系统的交互
性能评估
回顾
性能 = 程序执行时间
给定一个程序, 性能优化的方向
- 减小
inst/prog- 编译优化, 更好的指令集设计 - 减小
cycle/inst(CPI) - 增加IPC, 体系结构优化 - 减小
time/cycle- 增加主频, 电路关键路径优化, 后端物理设计优化
跑一个程序的性能如何?
性能 = 程序执行时间
我们需要在仿真环境中做一些统计工作
inst/prog- 程序的指令数- 像NEMU那样直接统计即可
cycle/inst- CPI, 不过一般统计IPC- 有指令数了, 再统计周期数即可
- 在仿真环境里面很容易统计
- 有指令数了, 再统计周期数即可
time/cycle- 每周期的时间- 这里的
time不是主机的真实时间, 是仿真环境中的时间 - 一般通过综合器评估出主频, 然后计算
- 这里的
如果想进一步了解为什么程序跑成这样?
我们需要知道程序的运行时间都花在哪里
- 需要对CPU内部做profiling!
我们关心的问题
- CPU执行指令可能会在哪些地方发生阻塞/等待?
- 在这些地方具体等待了多久?
科学的性能瓶颈定位方法:
- 通过性能计数器统计阻塞事件的次数
- 通过波形观察那些阻塞事件较多的部件的细致行为
一个简单的处理器性能模型
/--- frontend ---\ /-------- backend --------\
+-----+ <--- 3. computation efficiency
+--> | FU | --+
+-----+ +-----+ | +-----+ | +-----+
| IFU | --> | IDU | --+ +--> | WBU |
+-----+ +-----+ | +-----+ | +-----+
^ +--> | LSU | --+
| +-----+
1. instruction supply ^
2. data supply --+将处理器分为前端和后端, 如果希望处理器全速运行:
- 前端需要保证指令供给
- 影响所有指令 - 指令都没有, 整个处理器只能空转
- 后端需要保证数据供给和计算效率
- 数据供给影响访存指令, 尤其是load指令
- store可以通过写入store buffer认为已完成
- 计算效率影响其他计算类型指令, 如乘除法, 浮点等
- 数据供给影响访存指令, 尤其是load指令
经典体系结构的4类优化方法
- 局部性 - 利用数据访问性质提升指令/数据供给的效率. 代表性技术:
- 缓存, 今天的主题
- 并行 - 多个实例同时工作. 代表性技术:
- 指令级并行 - 流水线, 多发射, VLIW, 乱序执行
- 数据级并行 - SIMD, 向量指令/向量机, GPU(SIMT)
- 任务级并行 - 多线程, 多核, 多处理器, 多进程
- 预测 - 先投机, 后检查. 代表性技术:
- 分支预测
- 缓存预取
- 加速器 - 专用部件做专业事情. 代表性技术:
- 乘除法器
- 各种定制化的加速器IP
体系结构设计的8个伟大思想 - David Patterson

最后, 跑什么程序比较合适?
- 需要跑有代表性的程序 - 越能代表处理器的应用场景, 就越合适
- 各种各样的benchmark - MLPerf(机器学习), CloudSuite(云计算), SPEC CPU(通用计算)…
- coremark和dhrystone早就该淘汰了 - David Patterson
- 它们代表不了什么应用场景
- 只不过业界惯性太大了, 大部分人都不太懂评测 😂
不过 “一生一芯”主要是教学, 所以要求也不用那么苛刻
- 但有条件的话还是可以跑丰富一些的程序(例如仙剑)
- microbench是一个不错的选择
- 排序, 位操作, 语言解释器, 最大流, 矩阵, 压缩, md5, 素数, A*算法
- RTL仿真可以考虑跑train规模
缓存
存储层次结构 - 不同存储介质的物理性质不同
access time /\ capacity price
/ \
~1ns / reg\ ~1KB $$$$$$
+------+
~10ns / DRAM \ ~10GB $$$$
+----------+
~10ms / disk \ ~1TB $$
+--------------+
~10s / tape \ >10TB $
+------------------+



SoC访存延迟
“一生一芯”SoC目前采用SDRAM
- 控制器时钟100MHz, 读延迟6周期, 写延迟3周期
- 流片SoC环境实测数据
- 从现在来看已经很落后了 😂
- SDRAM(SDR) -> DDR -> DDR2 -> DDR3 -> DDR4
- 感兴趣的同学可以加入我们, 一起研发 “先进”的IP
用这个SDRAM, 如果你的CPU能跑500MHz
- 读延迟30周期, 写延迟15周期
- 单周期处理器? 实际中不存在的
cache - 弥补寄存器和DRAM之间的存储层次
access time /\ capacity price
/ \
~1ns / reg\ ~1KB $$$$$$
+------+
cache -----> ~3ns / SRAM \ ~30KB $$$$$
+----------+
~10ns / DRAM \ ~10GB $$$$
+--------------+
~10ms / disk \ ~1TB $$
+------------------+
~10s / tape \ >10TB $
+----------------------+关键思想: 加一层SRAM, 尽可能将程序需要访问的数据存在SRAM中
- 没cache就写流水线? 接入SoC秒变多周期 🙃
- IPC < 0.0333, load指令的IPC < 0.0167
冷知识: cache发音同cash
问题是, 我们真的可以 “尽可能将程序需要访问的数据存在SRAM中”吗?
- 要访问哪些数据是程序来决定的
一个重要的观察 - 局部性原理
架构师发现, 程序对内存的访问存在若干规律
- 时间局部性 - 当前访问的数据, 短时间内很有可能再次访问
- 空间局部性 - 当前访问的数据, 短时间内很有可能访问其相邻数据
这些现象和程序的结构和行为有关
- 程序大多数时候顺序执行(空间局部性)或循环执行(时间局部性)
- 相关的变量在源码中定义的位置相近, 编译器为其分配相近的存储空间
- 变量的数量 <= 操作的次数, 因此必定有变量会被多次访问(时间局部性)
- 循环访问数组(空间局部性)
人类生活中也存在局部性原理
- 关联的物品放在一起(柴米油盐放在厨房) - 空间局部性
- 经常使用的物品放在身边(手机不离身) - 时间局部性
cache的本质 - 副本管理
副本 = cache块 = 内存中的数据
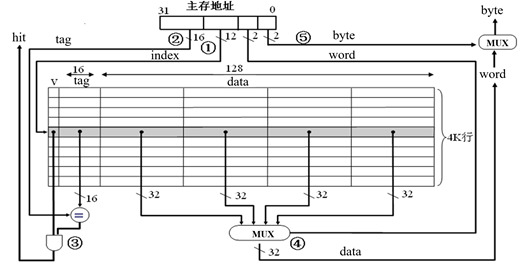
设计cache需要解决如下问题
- 块大小怎么取比较好?
- 即以多少数据为单位进行管理?
- 如何标记cache块来自哪里?
- 如何知道CPU需要访问的数据是否在cache中?
- cache的SRAM可以存放多个cache块, 怎么放?
- cache满了怎么办?
- cache块发生更新, 怎么办?
cache的设计
- 块大小 = 16B
- 实际上, 太大或者太小都不好
- 标记cache块的来源
- 按照块大小给DRAM中的数据编号, 得到每个块的唯一tag
- CPU发出访存请求, 只需要对比tag, 即可得知副本是否在cache中
- 组织多个cache块(上图中的SRAM可存放4096个cache块)
- 一种方案: 放到索引为(tag % 4096)的那一行 - 直接映射(direct map)
- tag可以短一些, 低位充当index位
- 复位时cache块均无效, 故通过valid位标识(与tag统称元数据)
- 如果多个块的index相同, 则用新的替换旧的
- 一种方案: 放到索引为(tag % 4096)的那一行 - 直接映射(direct map)
其他组织方式 - 全相联(fully associate)
- 每个cache块都可放到任意行
- 不需要index位了
- 具体放到哪一行, 由替换算法根据每一行当前的访问状态决定
- FIFO, LRU, random…
- 不过判断命中的开销比较大, 每一行存放的tag都要比较
- CAM(Content-Addressable Memory), 根据内容查询存储地址
- 一般工艺库不提供这种原语
- 要么全定制(难度大), 要么用触发器搭(面积, 功耗大)
- 一般只在行数较少的场景下使用
其他组织方式 - 组相联(set associate)
- 给行分组, 每个cache块都可放到组号为(tag % 组数)中的任意行
- 若每组有x行, 则称为x路组相联
- index位用来指示组号
// 用之前的例子, 4路组相联, 有4096/4=1024组
31 14 13 4 3 0
+---------+-------+--------+
| tag | index | offset |
+---------+-------+--------+- 判断命中时, 只需要比较组内每一行存放的tag即可
- 路数不大时, CAM的开销可以接受
- 直接映射和全相联都可以看成是组相联的特例
- 路数=1 -> 直接映射
- 路数=行数 -> 全相联
- 现代CPU一般采用8或16路组相联
cache块的更新
CPU会发出写请求, cache如何处理?
- 写通(write throught) - 每次写操作都同时写到内存
- 如果写操作在cache中缺失, 则又有两种策略
- 写分配(write allocate) - 在cache中分配副本
- 非写分配(not write allocate) - 不在cache中分配副本
- 关键取决于程序更新变量后, 将来还是否会访问它
- 怎么知道呢? 对程序进行Profiling!
- 如果写操作在cache中缺失, 则又有两种策略
- 写回(write back) - 每次只写cache块, 被替换时才写到内存
- 每个块需要一个额外标志位指示是否被CPU写过: dirty位
- 如果被替换时是clean的, 则无需写回内存
- 写通 vs. 写回, 关键取决于程序更新变量后, 将来是否还会再次更新它
- 怎么知道呢? 对程序进行Profiling!
cache的RTL实现
cache的一般工作流程:
- CPU向cache发出访存请求
- cache根据请求地址的tag位, 判断是否命中, 若命中, 则跳转到第7步
- 若需要替换, 则根据替换算法选择一个cache块
- 若该块是dirty的, 则通过总线将其写回内存
- 通过总线读出CPU访存请求所在的数据块
- 将该数据块填入cache中, 更新元数据
- 执行CPU的访存请求
不同情况做不同的事情 = 状态机!
- cache的RTL实现 = 块存储(SRAM) + 元数据存储(存储开销不大时可用触发器) + 控制器(状态机)
ASIC流程中的SRAM原语
ASIC流程中需要使用工艺库提供的SRAM原语
- 读延迟为1周期
- 不要用那种读延迟为0的存储器模型, 例如FPGA中的distributive RAM
- ASIC没有这种原语, 只会综合成大量触发器, 时序/面积/功耗都很低
- 这是FPGA和ASIC的区别
SRAM原语的规格种类是有限的, 需要根据SRAM原语的规格来写RTL
此外, SRAM的读延迟(用ns衡量)决定了处理器主频的上限
- 如果使用了一个读延迟为1ns的SRAM, 则主频最高为1GHz
- 再高的话, SRAM会产生时序违例
- 这个参数和SRAM的规格有关, 越大的SRAM, 读延迟越长
icache & dcache
在流水线/乱序执行CPU中, IFU和LSU通常同时工作, 都要访问cache
一般采用分离cache的方案, 即IFU访问icache, LSU访问dcache, 两者区别如下
- 取指令不会发生写操作
- icache的局部性比dcache好
- 顺序和循环
将两者分开可以进行针对性的设计, 包括组织方式, 替换/预取算法等
此外, 若两者合并, 则需要采用真双口的SRAM, 同时处理两个访问请求
- 面积和延迟都会增加
多级cache
真实的CPU上一般配备多级cache, 若在其中一级缺失, 则访问下一级
一般来说, 不同级别的cache有不同的设计目标
- L1 cache与流水线结合紧密, 需要尽快响应请求, 对IPC影响很大
- 一般采用小容量的SRAM, 保证低延迟, 同时保证大部分请求命中
- L2 cache远离流水线, 可通过更多周期读出数据块
- 延迟没那么紧张, 容量可到100KB甚至MB级别
- 有充分的时序实现更复杂但更有效的替换/预取算法
- L3 cache距离内存更近, 尽量通过大容量保证请求命中
- 容量可到10MB级别, 甚至通过半频方式访问更大容量的SRAM
- 双路AMD EPYC™ 9654共786MB L3 😂
- 容量可到10MB级别, 甚至通过半频方式访问更大容量的SRAM
总线的突发读写
cache每次访问内存时, 总是读写一个块的大小
- 通常块大小 > 总线的数据位宽
方式1 - 拆分成多个总线事务请求
关键字优先
CPU一次通常只访问一个cache块中的一部分
- 例如lw指令只访问其中4字节
cache缺失时, 可以先读出CPU需要的部分(critical word)
CPU: lw a0, 0x8
+------+
16 V8 4 0
+---+---+---+---+
|4th|3rd|2nd|1st|
+---+---+---+---+
1 30 1 1 1 1
|---|----------|---|---|---|---|
3rd 4th 1st 2nd
\ transaction /RTFM: axburst的wrap模式
真实的设计空间探索
设计空间探索
缓存有那么多参数, 那么多策略, 怎么选合适?
- 特别地, 会不会有的组合不相容反而导致性能下降?
- 要想选一个还不错的组合, 需要评估它们效果如何
评估指标: 命中率, IPC, 主频, 面积, …
这些指标的表现都不错, 才是一个比较好的方案
- 反过来说, 如果一个指标的表现很差, 肯定不会采用
快速的设计空间探索: 用较低的开销评估某些容易评估的指标
- cache的命中率可以通过功能模拟器快速统计!
- 在RTL仿真环境中也可以统计, 但没必要
trace驱动的cache模拟器
用C代码模拟cache的工作流程
我们可以把NEMU中的mtrace作为这个cache模拟器的输入!
- mtrace已经记录了程序访存的信息, 评估命中率甚至不需要CPU
- 改成二进制更容易存储和解析
体系结构顶会ISCA多次举行基于ChampSim模拟器的大赛
周期精确的模拟器
在模拟器中用C代码实现周期信息的统计
- 简单系统可以建模, 例如SDRAM的延迟
- 复杂系统通常用全系统模拟器, 例如gem5
- 可以认为是RTL工程的C代码版本
我们可以在周期精确的模拟器上统计IPC!
- 通过对比两个方案的IPC, 可以决定是否值得投入时间用RTL实现它们
- 香山团队的数据: 跑一轮程序, gem5 2小时 vs. verilator 1周
- 用RTL跑一组配置的时间, 可以用模拟器探索84组不同配置的效果
- 对比NEMU和NPC的性能也能感受到两者的区别
最后才是RTL实现
考虑主频/面积等因素, 用RTL实现这些方案
- 有可能有些方案命中率和IPC达标, 但主频和面积不达标
- 但用RTL评估命中率和IPC, 需要花费很多时间
- RTL难写对, 需要考虑与其他模块交互正确(如总线)
- 处理器越复杂, 把RTL写对的难度就越高
- 考虑在香山中加一个模块
- 处理器越复杂, 把RTL写对的难度就越高
- 仿真还跑得慢
- RTL难写对, 需要考虑与其他模块交互正确(如总线)
真实情况: 处理器体系结构的研究和探索并不是在RTL代码上进行的
不要再问这么设计好不好
有一个xxx想法
- 面向大佬的虚假学习: 在群里问大佬好不好, 大佬说好就用RTL实现, 大佬说不好/不说话, 就不实现
- 面向评估的真正学习:
自己实现, 评估性能, 分析为什么跑出这个结果
- “一生一芯”教大家搭环境, 用工具, 就是希望大家有朝一日可以打通 “想法 -> RTL -> 性能评估”的流程
- 通过性能计数器得到一手数据, 真正理解一项技术为什么好/不好
- 这才是真正的学习, 而不是什么都靠道听途说
作业: 不问大佬, 自己探索cache每个参数具体如何影响程序性能
- cache块的大小/关联度/替换算法/写策略/…
缓存一致性问题
cache和输入输出
#include <stdint.h>
int main() {
const int BUSY = 0x0;
volatile uint8_t *status = (uint8_t *)(uintptr_t)0x400;
volatile uint8_t *data = (uint8_t *)(uintptr_t)0x404;
while (*status == BUSY); // wait until idle
*data = 0;
return 0;
}0000000000000000 <main>:
0: 40004783 lbu a5,1024(zero) # 400 <main+0x400>
4: fe078ee3 beqz a5,0 <main>
8: 40000223 sb zero,1028(zero) # 404 <main+0x404>
c: 00000513 li a0,0
10: 00008067 ret如果lbu指令的结果进入cache, 会发生什么?
回顾: 访问设备有副作用, 会改变其状态
- 访问cache块的行为与访问设备不一致
- 解决方案: 用crossbar将IFU和LSU的I/O请求绕过cache
icache和dcache
如果icache和dcache包含同一个副本, 而且dcache对其更新, 则需要考虑两者的一致性问题
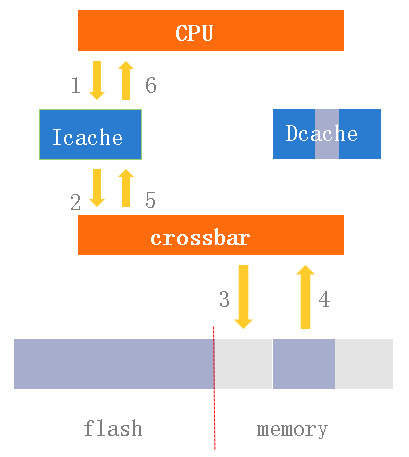
- loader加载代码就会出现这个问题
- IFU可能取不到新指令
采用写通策略也不能100%解决
- 考虑在流水线/乱序执行CPU中, 加载完代码后马上跳到代码末尾
维护icache和dcache之间的一致性
RISC-V提供fence.i指令, 让程序指示硬件进行代码和数据的同步
| 写dcache时 | icache缺失时 | 执行fence.i时 |
|---|---|---|
| 更新icache中相应块 | - | nop |
| 无效icache中相应块 | 先检查dcache相应块 | nop |
| - | 先检查dcache相应块 | 无效整个icache |
| - | - | 无效整个icache,
写回dcache中的脏块 |
推荐最后一种, 容易实现
- 如果你觉得性能低, 就做profiling, 统计fence.i的执行频率
cache和DMA
DMA也会访问内存, 需要考虑dcache和DMA访问的内存之间的一致性
- 如果DMA写内存, 而相应数据块已经在dcache中, CPU将读到旧数据
- 如果DMA读内存, 而相应数据块已经在dcache中, DMA会读到旧数据
- 硬件解决方案: 让DMA进入cache, 可从dcache中读出新数据,
也可以往dcache中写入新数据供CPU访问
- L3容量大, intel推出DDIO(data direct I/O)技术, 让DMA数据进入指定的路, 避免冲刷整个L3 cache
- L1容量小, 一般通过硬件cache一致性来维护(RISC-V默认方案)
- 软件解决方案: 添加cache控制指令
- 软件发起DMA写内存的请求前, 通过该指令无效相应cache块
- 软件发起DMA读内存的请求前, 通过该指令写回相应cache块
因为cache控制指令容易造成安全问题, RISC-V将其作为可选扩展
多核 & 多片
多核CPU可能会访问同一个cache块
- 典型场景: 多线程程序访问共享变量
- 只能靠硬件cache一致性了,
总不能在每条访存指令之前都插入一条cache控制指令
- cache一致性协议基于总线实现
- 顺手把DMA一致性的问题也解决了
- 于是更没有必要添加cache控制指令了, 所以RISC-V将其作为可选扩展
如果系统中有多个芯片共享内存, 还要考虑多个芯片之间的cache一致性
- 需要在片间总线协议中支持cache一致性
总结
体系结构设计 != RTL设计
- 基于profiling数据(程序行为)和底层实现(电路)做出的权衡
- profiling需要有benchmark和性能计数器
- 经典体系结构的4类优化方法
- 局部性/并行/预测/加速器
- 缓存是局部性原理的重要应用
- 设计空间探索需要用较低的开销评估命中率, IPC等容易评估的指标
- 通过较低成本过滤掉某些不达标的设计
- 通常在功能模拟器/全系统模拟器上开展
- 最后才在RTL层次考虑主频和面积