ROM: 从制造时编程到现场可编程
val rom = VecInit(wordArray.map(x => x.U(wordbits.W)))
io.data := RegNext(rom(io.addr))我们刚才的ROM是硬连线写死在芯片内的
- 产商根据我们提供的版图(由RTL经过后端物理设计得到)制造芯片
- 芯片制造后, ROM中存储的内容无法修改

随着材料技术的发展, 人们发明了现场可编程的flash存储器
- 现场可编程 = 擦除 + 重新写入
- 改动flash中存放的程序, 代价变得可接受
flash颗粒
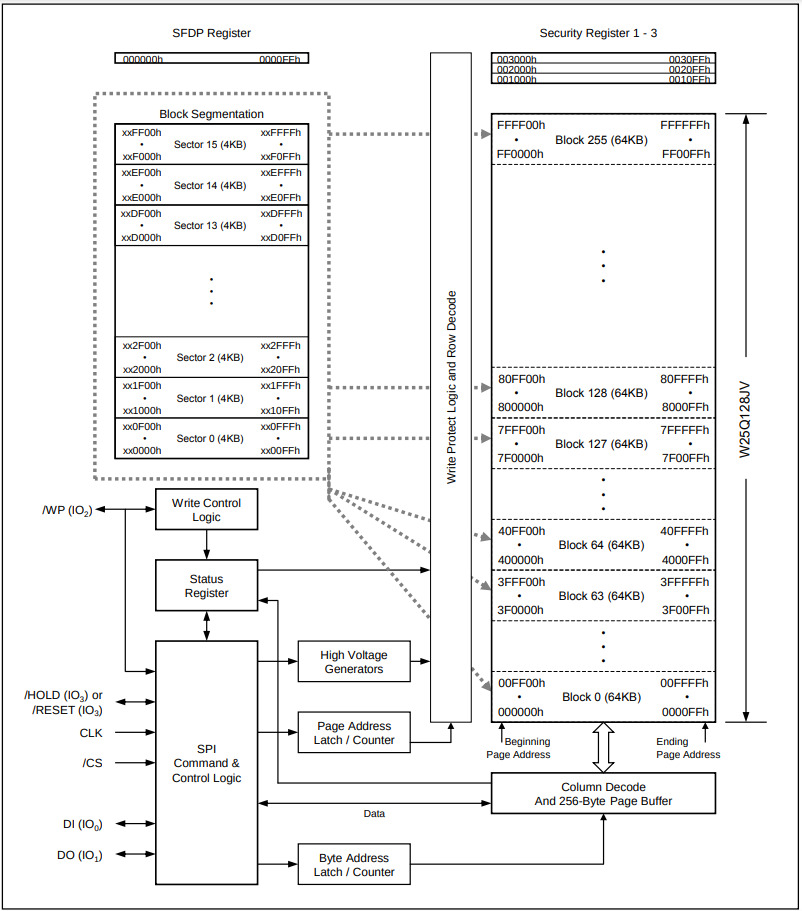
型号W25Q128JV, RTFM
- 内部就是一个设备控制器!
- 24根地址线, 16MB存储单元
- 分成256个64KB块, 每个块有16个4KB扇区, 每个扇区有16个256B页
- 页是最小的擦除和写入单位
- 字节是最小的读出单位, 支持随机读取
- 外部通过SPI总线协议与其通信
SPI总线
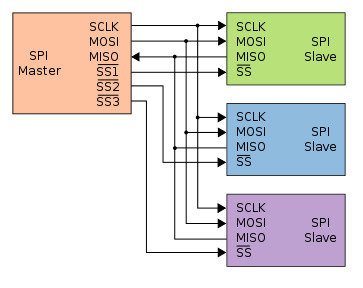
- Serial Peripheral Interface
- 一种串行总线协议, 采用主从设备架构
- SCK - master发出的时钟信号
- SS - slave select, master发出的slave选择信号
- MOSI - master output slave input, master向slave通信的数据线
- MISO - master input slave output, slave向master通信的数据线
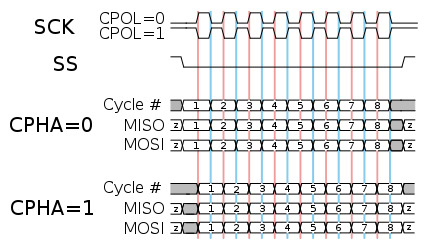
- 本质上是串/并之间的转换, 通过移位寄存器实现
- 还支持设置时钟极性(clock polarity)和时钟相位(clock phase)
- 适应不同种类的slave
ysyxSoC/ysyx/perip/spi/rtl/spi_shift.v
- 还支持设置时钟极性(clock polarity)和时钟相位(clock phase)
从flash颗粒中读出数据
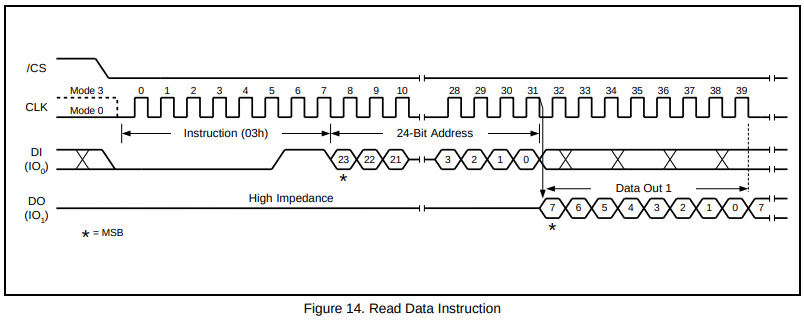
根据手册给flash颗粒发送正确的指令序列
- 8位指令
03h表示读数据, 后面加24位的存储单元地址, 通过MOSI传输 - 之后返回该存储单元的数据, 通过MISO传输
- 若SCK持续, 则依次读出后续存储单元的内容
- 根据FM设置SPI的时钟极性和相位
The code and address bits are latched on the rising edge of the CLK pin. After the
address is received, the data byte of the addressed memory location will be shifted
out on the DO pin at the falling edge of CLK with most significant bit (MSB) first. SDRAM
为了支持store指令的执行, 需要有一个支持随机写操作的存储器
- SDRAM - Synchronous Dynamic Random Access Memory
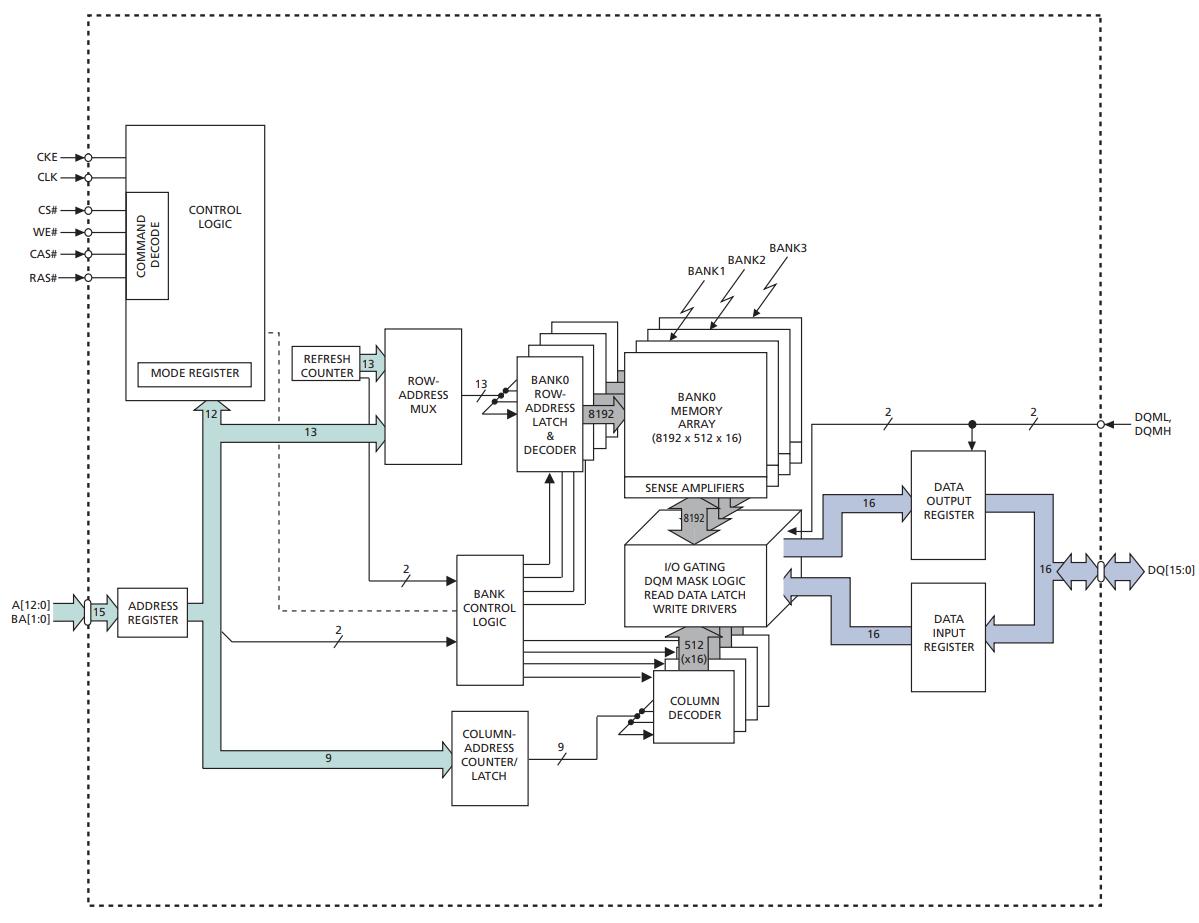
SDRAM命令

ysyxSoC/ysyx/perip/sdram/rtl/sdram_axi_core.v
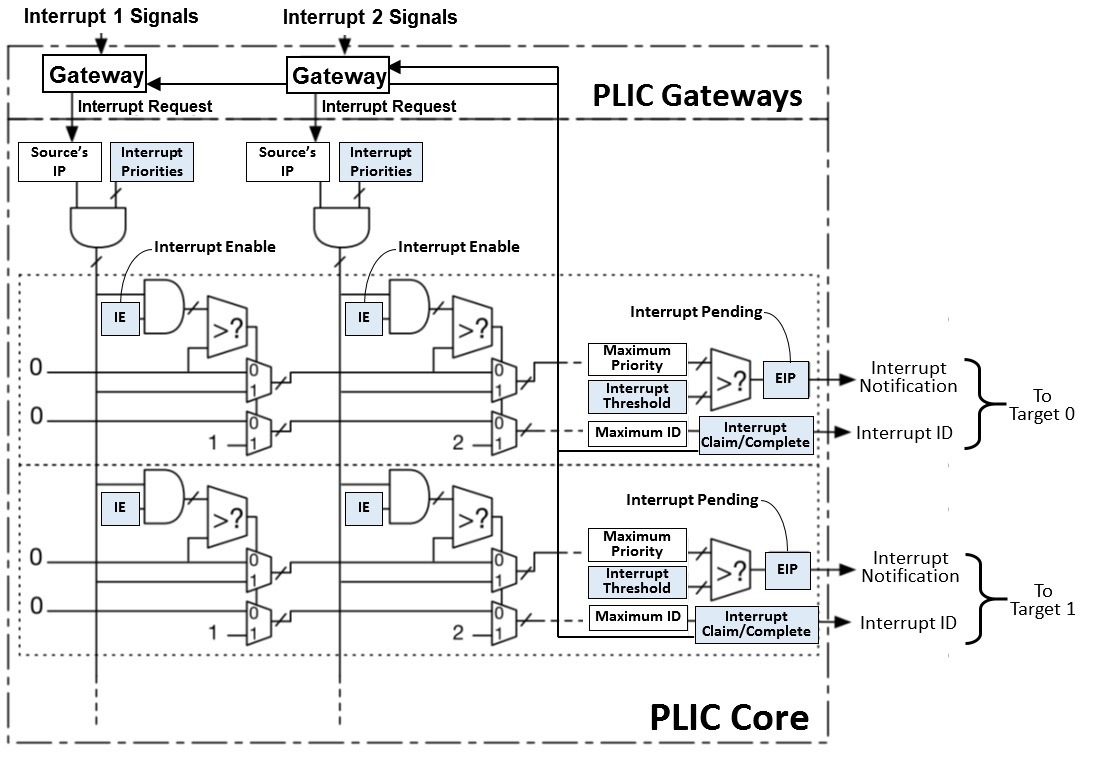
PLIC
一个外部中断的选择器(RTFM)
- 当多个设备同时发起外部中断, PLIC负责从中选择一个, 并通过M模式外部中断通知CPU
ChipLink + FPGA = 灵活的设备扩展
在FPGA端将ChipLink包拼接并还原为TileLink请求, 然后转回AXI请求
- 可以在FPGA中连接各种设备
- 只要FPGA足够高级, 可以连现代外设DDR/PCI-e
- 通过额外1根中断线实现中断控制器级联, 接入FPGA设备中断信号
- 设备中断 -> 中断控制器 -> 中断引脚 -> 片上PLIC -> 片上CPU
- 缺点: 带宽低(用性能换来的灵活性)