



引言
我们之前都是假设指令可以成功执行
如果指令执行失败, 应该怎么办?
本次课内容:
- 异常处理过程
- 异常处理的模型
- 异常处理的真实应用
异常事件
系统难免会出错
- CPU译码时发现非法指令
- 内存某些单元损坏了
- 你写的程序访问了非法内存
计算机系统应该如何应对?
摆烂 - UB
例如整数除0
- C语言标准 - 我不管, 发生什么都不关我事
- MIPS处理器 - 我也不管, 随便给除法指令返回一个结果
- 程序员 - 这…
- MIPS-gcc - 有一个编译选项
-mcheck-zero-division, 可以自动在除法前生成指令检查除数是否为0
- MIPS-gcc - 有一个编译选项
- C语言为了兼容各种机器的差异, 只能UB
- 高层的新语言可以明确定义异常行为
- 通过语言虚拟机(类似NEMU)将底层系统抽象掉
- 例如在Java中, 除零和数组越界都会抛出异常
但摆烂对用户来说并不友好
编译器发现语法错误, 悄悄生成错误的代码
- 这么搞程序员都要折寿 😂
- 我们希望编译器能准确地输出报错信息
- 最好能自动把bug修了
- 真的有这种研究工作
- Guoliang Jin, Linhai Song, Wei Zhang, Shan Lu, and Ben Liblit. Automated atomicity-violation fixing. In Proceedings of the 32nd ACM SIGPLAN conference on Programming language design and implementation, pp. 389-400. 2011 (PLDI’11)
- 真的有这种研究工作
CPU作为数字电路, 要输出报错信息/自动修bug比较困难
- 最低限度要告诉软件
- 这里好像不太对, 要不你来看一下?
异常处理过程
需求
回顾: 程序/指令集/CPU都是状态机
需要把当前程序P的状态保存起来, 并跳转到异常处理程序进行后续诊断
- 这里我们选指令集状态机
S = {<R, M>}
保存M的需求好像很奇怪: M这么大,
要保存到哪里?
一个观察: 异常处理程序和P是两个不同的程序,
它们使用不同的M
- 只要异常处理程序不随意修改P的
M, 则不必进行实质性的保存操作
R只有一份, 异常处理程序也要用, 肯定要保存
保存R
要把P的R保存到哪里呢?
S = {<R, M>}, 也只能保存到S里面了 😂- 保存到
R: 增加一组寄存器R_save, 专门用来保存R - 保存到
M: 需要找一处空闲的内存区域- 最合适的是栈 - 只要栈上还有空间, 肯定是空闲的
- 保存到
谁来保存?
- 硬件保存: 在CPU状态机的控制下保存
- 软件保存: 通过指令控制CPU进行保存
保存R的设计
P发生异常 -> 硬件保存 -> 跳转到异常处理程序 -> 软件保存
R |
M |
|
|---|---|---|
| 硬件 | 硬件保存到R_save |
硬件保存到M |
| 软件 | 软件保存到R_save |
软件保存到M |
考虑到异常处理程序也需要读取R_save,
CPU还要添加相应指令
- x86可以通过硬件TSS特性将
R保存到M- 但开发者发现其性能不如软件保存, 而且不灵活(必须保存所有状态)
- RISC架构一般通过软件将
R保存到M- 采用已有的store指令即可
- 不过PC无法用软件保存, 因为在这之前旧PC已经被覆盖了
- RISC-V硬件将PC保存到mepc这个特殊的寄存器
控制状态寄存器(CSR, Control and Status Register)
用于控制和反映处理器状态的特殊寄存器
- 硬件可能会自动更新CSR, 或者从CSR中读出值来使用
- 软件也可以通过CSR指令来访问CSR
- 所以每个CSR都有一个软件可见的编号(CSR地址空间)
- RTFM
- 所以每个CSR都有一个软件可见的编号(CSR地址空间)
31 20 19 15 14 12 11 7 6 0
+--------------------+-------+------+-------+------+
| csr | rs1 |funct3| rd |opcode|
+--------------------+-------+------+-------+------+
+------+------+---------------------------------+
|Number|Name |Description |
+------+------+---------------------------------+
|0x341 |mepc |Machine exception program counter|
+------+------+---------------------------------+
|0x342 |mcause|Machine trap cause |
+------+------+---------------------------------+
|... |... |... |最简单的异常处理还需要的CSR
mtvec - 异常处理程序的入口地址
- 发生异常时, CPU自动跳转到这个地址
一个最简单的异常处理程序(用了AM提供的运行时环境)
加个异常原因方便诊断
mcause - 异常原因
- 发生异常时, CPU将异常号写入这个CSR
- RTFM了解异常号的含义
uintptr_t mepc, mcause;
asm volatile ("csrr %0, mepc" : "=r"(mepc));
asm volatile ("csrr %0, mcause" : "=r"(mcause));
printf("exception mcause = %p at mepc = %p\n", mcause, mepc);
while (1); 0 - Instruction address misaligned
1 - Instruction access fault
2 - Illegal Instruction
3 - Breakpoint
4 - Load address misaligned
5 - Load access fault
6 - Store/AMO address misaligned
7 - Store/AMO access fault
8 - Environment call from U-mode
9 - Environment call from S-mode
11 - Environment call from M-mode
12 - Instruction page fault
13 - Load page fault
15 - Store/AMO page fault异常处理的模型
异常处理的状态机模型
- 状态的扩展:
R = {PC, GPR, CSR},M无需扩展 - 状态转移的扩展
- 执行指令不再总是成功: 定义一个函数
fex: S -> {0, 1}, 给定任意状态S,fex(S)表示当前指令执行是否失败- 若
fex(S) = 0, 则按照当前指令的语义进行状态转移 - 若
fex(S) = 1, 则执行一条特殊指令raise_intr 异常号, 并更新状态如下:![]()
- 若
- 执行指令不再总是成功: 定义一个函数
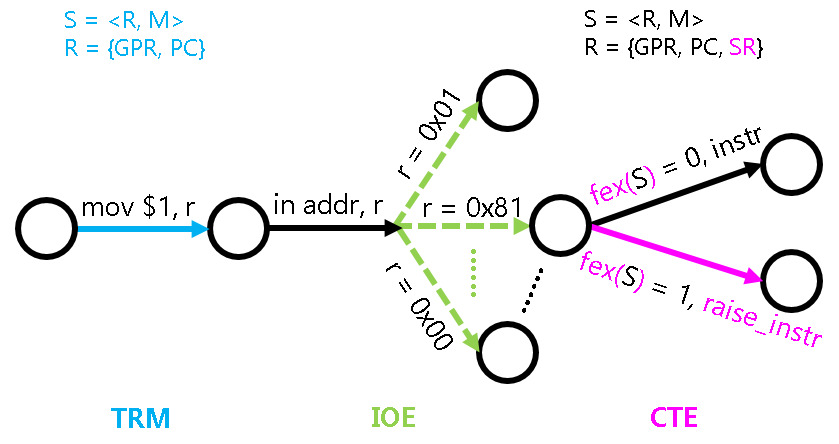
异常处理的状态机模型(2)
fex(S)函数是处处有定义的吗?
- 即能否明确地回答 “一条指令的执行是否会失败”
答案是肯定的: RTFM!
- 地址不对齐: addr % 字节位宽 != 0
- 断点: inst == 0x00100073 (RISC-V的ebreak指令)
- 非法指令: inst.opcode未在手册中定义
- 甚至多个异常同时发生时应该先处理哪一个, 手册都定义了
一个重要的结论: 异常处理过程是确定的!
- 多次运行相同的程序, 都应该在相同的位置抛出相同的异常,
状态机应该进行相同的状态转移
- 不考虑IOE的输入指令
AM中的CTE
不同指令集的不同: 异常号及其含义/触发异常的条件/保存的状态
老规矩, 加个抽象层: CTE (ConText Extension)
- 异常号及其含义不同 - 提供事件的抽象
abstract-machine/am/include/am.h中的事件定义
- 触发异常的条件不同 - 提供事件处理的抽象
- 回调函数
Context* (*h)(Event ev, Context *ctx)
- 回调函数
- 保存的状态不同 - 提供上下文结构的抽象
- “上下文”是操作系统的术语, 其实就是程序的状态
abstract-machine/am/include/arch/$ARCH.h中的Context结构体
上层程序关心的是: 发生了什么事件, 该如何处理
riscv64-nemu CTE代码导读
异常处理的真实应用
1.系统调用
现代计算机系统都支持多用户多任务
让用户程序直接访问系统中的资源并不是一个好主意
| 特权级 | 说明 |
|---|---|
| M | 机器模式 |
| S | 监管模式 |
| U | 用户模式 |
- 程序员都需要了解底层资源的使用方式
- 程序出bug = 系统崩溃
- 多个程序可能竞争相同的资源, 没有协调者
发起系统调用
唯一合法方式: 自陷类异常 - 执行一条无条件触发异常的指令
- RISC-V提供ecall指令
为了让用户程序指定请求何种服务, 系统调用也需要传递参数
- 最合适的方案是通过寄存器来传递
- 操作系统的异常处理函数识别到系统调用请求后,
可从
Context结构中读出系统调用的参数 - RISC-V Linux约定采用a7寄存器传递系统调用号, a0, a1,
…分别传递第1/2/…个参数
man syscall
- 操作系统的异常处理函数识别到系统调用请求后,
可从
- 为什么不通过a0传递系统调用号?
- Hint: 回顾RISC-V调用约定
系统调用示例
2.RISC-V的SBI调用
- 系统调用 = U模式请求S模式提供服务
- SBI调用 = S模式请求M模式提供服务
- SBI = Supervisor Binary Interface, 是M模式和S模式之间的约定
- SBI调用也通过ecall指令发起, 参数传递方式与系统调用类似
SBI调用涉及的功能(M模式才有权限进行的操作):
- 定时器设置
- IPI(处理器间中断)
- 远程屏障
- 硬件线程状态管理
- 系统复位
- 性能监控单元管理
SBI实现示例
BBL(Berkeley BootLoader)的SBI实现
//riscv-pk/machine/mtrap.c
void mcall_trap(uintptr_t* regs, uintptr_t mcause, uintptr_t mepc) {
write_csr(mepc, mepc + 4);
uintptr_t n = regs[17], arg0 = regs[10], arg1 = regs[11], retval, ipi_type;
switch (n) {
case SBI_CONSOLE_PUTCHAR: retval = mcall_console_putchar(arg0); break;
case SBI_CONSOLE_GETCHAR: retval = mcall_console_getchar(); break;
case SBI_SEND_IPI: ipi_type = IPI_SOFT; goto send_ipi;
case SBI_REMOTE_SFENCE_VMA:
case SBI_REMOTE_SFENCE_VMA_ASID: ipi_type = IPI_SFENCE_VMA; goto send_ipi;
case SBI_REMOTE_FENCE_I: ipi_type = IPI_FENCE_I;
send_ipi:
send_ipi_many((uintptr_t*)arg0, ipi_type); retval = 0; break;
case SBI_CLEAR_IPI: retval = mcall_clear_ipi(); break;
case SBI_SHUTDOWN: retval = mcall_shutdown(); break;
case SBI_SET_TIMER: retval = mcall_set_timer(arg0); break;
default: retval = -ENOSYS; break;
}
regs[10] = retval;
}3.指令模拟
RISC-V是模块化的
- 如果执行了CPU不支持的扩展指令, 将抛出非法指令异常
可让异常处理函数代替CPU执行
- 读出这条 “非法”指令
- 译码, 确定是否真的 “非法”
- 若是合法扩展指令, 则执行它
- Context存放了程序的状态
- 更新PC(Context中的mepc)
这个过程和NEMU几乎完全一样
BBL可模拟浮点指令
- 没有FPU也可以启动Debian!
//riscv-pk/machine/emulation.c
void illegal_insn_trap(uintptr_t* regs,
uintptr_t mcause, uintptr_t mepc) {
// ...
insn = get_insn(mepc, &mstatus);
if ((insn & 3) != 3)
return emulate_rvc(regs, mcause, mepc, mstatus, insn);
extern uint32_t illegal_insn_trap_table[];
int32_t* pf = (void*)illegal_insn_trap_table + (insn & 0x7c);
emulation_func f = (void*)illegal_insn_trap_table + *pf;
f(regs, mcause, mepc, mstatus, insn);
write_csr(mepc, mepc + 4);
}
//riscv-pk/machine/fp_emulation.c
void emulate_fmul(uintptr_t* regs, uintptr_t mcause,
uintptr_t mepc, uintptr_t mstatus, insn_t insn) {
if (GET_PRECISION(insn) == PRECISION_S) {
uint32_t rs1 = GET_F32_RS1(insn, regs);
uint32_t rs2 = GET_F32_RS2(insn, regs);
SET_F32_RD(insn, regs, f32_mul(f32(rs1), f32(rs2)).v);
} else if (GET_PRECISION(insn) == PRECISION_D) {
uint64_t rs1 = GET_F64_RS1(insn, regs);
uint64_t rs2 = GET_F64_RS2(insn, regs);
SET_F64_RD(insn, regs, f64_mul(f64(rs1), f64(rs2)).v);
} else {
return truly_illegal_insn(regs, mcause, mepc, mstatus, insn);
}
}mtime的故事
在RISC-V早期, mtime是一个CSR
- 后来架构师发现在多核场景下这个设计有问题
- 现代处理器支持动态调频, 可能会导致多个核mtime增长速率不一致
- 于是把mtime移到外设, 通过MMIO访问
- 只实现一个副本, 所有核读出的mtime一致
这是一个不兼容旧版的改动, 那些读mtime CSR的程序无法正确执行了
- 解决方案: 让异常处理函数重定向
- 新处理器访问mtime CSR时抛出非法指令异常
- 异常处理函数对指令进行译码
- 若原指令读mtime CSR, 则访问MMIO的mtime, 将结果写入寄存器
- 更新PC, 从异常处理返回
4.处理不对齐访存
如果访存指令的地址不对齐, 将抛出不对齐访存异常
- 和指令模拟类似, 也可以让异常处理函数代替CPU执行
- 拆成多个单字节的访存
- 不过这样就不保证访存的原子性了(但还是符合手册的约定)
Even when misaligned loads and stores complete successfully, these accesses might run
extremely slowly depending on the implementation (e.g., when implemented via an
invisible trap). Furthermore, whereas naturally aligned loads and stores are
guaranteed to execute atomically, misaligned loads and stores might not, and hence
require additional synchronization to ensure atomicity.BBL处理不对齐访存
// riscv-pk/machine/misaligned_ldst.c
void misaligned_load_trap(uintptr_t* regs, uintptr_t mcause, uintptr_t mepc) {
union byte_array val;
uintptr_t mstatus;
insn_t insn = get_insn(mepc, &mstatus);
uintptr_t npc = mepc + insn_len(insn);
uintptr_t addr = read_csr(mtval);
int shift = 0, len;
if ((insn & MASK_LW) == MATCH_LW) len = 4, shift = 8*(sizeof(uintptr_t) - len);
else if ((insn & MASK_LD) == MATCH_LD) len = 8, shift = 8*(sizeof(uintptr_t) - len);
else if ((insn & MASK_LWU) == MATCH_LWU) len = 4;
else if ((insn & MASK_LH) == MATCH_LH) len = 2, shift = 8*(sizeof(uintptr_t) - len);
else if ((insn & MASK_LHU) == MATCH_LHU) len = 2;
else {
mcause = CAUSE_LOAD_ACCESS;
write_csr(mcause, mcause);
return truly_illegal_insn(regs, mcause, mepc, mstatus, insn);
}
val.int64 = 0;
for (intptr_t i = 0; i < len; i++)
val.bytes[i] = load_uint8_t((void *)(addr + i), mepc);
SET_RD(insn, regs, (intptr_t)val.intx << shift >> shift);
write_csr(mepc, npc);
}5.妙用mtvec实现try-catch功能
C++在语言特性上支持异常处理
借助mtvec可实现类似功能(当然只能用于M模式)
// riscv-pk/machine/minit.c
void setup_pmp(void) {
// Set up a PMP to permit access to all of memory.
// Ignore the illegal-instruction trap if PMPs aren't supported.
uintptr_t pmpc = PMP_NAPOT | PMP_R | PMP_W | PMP_X;
asm volatile ("la t0, 1f\n\t"
"csrrw t0, mtvec, t0\n\t"
"csrw pmpaddr0, %1\n\t"
"csrw pmpcfg0, %0\n\t"
".align 2\n\t"
"1: csrw mtvec, t0"
: : "r" (pmpc), "r" (-1UL) : "t0");
}6.上下文切换
这样就实现了从A切换到B的效果 (操作系统的原型)
#include <am.h>
union task { Context *ctx; uint8_t stack[8192]; } tasks[2], *current = NULL;
static void delay() { for (int volatile i = 0; i < 10000000; i++) ; }
static void f1(void *arg) { while (1) { putch('a'); yield(); delay(); } }
static void f2(void *arg) { while (1) { putch('b'); yield(); delay(); } }
static void create_task(union task *t, void *f) {
Area stack = (Area) { &t->ctx + 1, t + 1 };
t->ctx = kcontext(stack, f, NULL);
}
static Context *handler(Event ev, Context *ctx) {
if (!current) current = &tasks[0];
else current->ctx = ctx;
current = (current == &tasks[0] ? &tasks[1] : &tasks[0]);
return current->ctx;
}
int main() {
cte_init(handler);
create_task(&tasks[0], f1);
create_task(&tasks[1], f2);
yield();
while (1);
}真实系统通过时钟中断强制触发上下文切换
- 操作系统的根基:
while (1)无法卡死整个系统了
总结
异常处理: 一种特殊的跳转
- CPU
- 按照手册约定, 发生异常时跳转到一个预先设定的位置
- 通过CSR保存部分状态
- RTFM
- AM的CTE抽象
- 把异常抽象成事件, 提供事件处理模型
- 上层应用
- 决定如何处理事件
- 真实应用
- 系统调用, SBI调用, 指令模拟, 处理不对齐访存, 上下文切换…